In this lab we are going to build demo TARS from Interstellar movie with Python. TARS can help you to automate your tasks such as search videos in YouTube and play them, send emails, open websites, search materials in Wikipedia and read them,inform weather forecast in your country, greetings and more. By building TARS you will increase your Python knowledge and learn many useful libraries/tools. I will push source code to my git repository so feel free to contribute and improve functionality of TARS

Let’s start by creating virtual environment and building the base audio system of TARS.
mkdir TARS
cd TARS
virtualenv venv
To activate the venv run command below
. venv/bin/activate
Once you activated venv, we need to install main libraries by following commands:
pip3 install gTTS
pip3 install SpeechRecognition
pip3 install PyAudio
pip3 install pygame
gTTS (Google Text-to-Speech) is a Python library and CLI tool to interface with Google Translate’s text-to-speech API. This module helps to convert String text to Spoken text and can be saved as .mp3
Speech Recognition is an important feature in several applications used such as home automation, artificial intelligence, etc. Recognizing speech needs audio input, and SpeechRecognition makes it really simple to retrieve this input. Instead of building scripts from scratch to access microphones and process audio files, SpeechRecognition will have you up and running in just a few minutes.
To access your microphone with SpeechRecognizer, you’ll have to install the PyAudio package
Pygame is a cross-platform set of Python modules designed for writing video games. It includes computer graphics and sound libraries designed to be used with the Python programming language.
Now, let’s build voice system of TARS:
from gtts import gTTS
import speech_recognition as sr
from pygame import mixer
def talk(audio):
print(audio)
for line in audio.splitlines():
text_to_speech = gTTS(text=audio, lang='en-uk')
text_to_speech.save('audio.mp3')
mixer.init()
mixer.music.load("audio.mp3")
mixer.music.play()
As you see we are passing audio as an argument to let the TARS speak. For instance, talk(‘Hey I am TARS! How can I help you?’) program will loop these lines with the help of splitlines() method. This method is used to split the lines at line boundaries. Then, gTTS will handle to convert all these texts to speech. text parameter defines text to be read and lang defines the language (IETF language tag) to read the text in. Once loop finished, save() method writes result to file.
pygame.mixer is a module for loading and playing sounds and must be initialized before using it.
Alright! Now, let’s create a function that will listen for commands.
def myCommand():
#Initialize the recognizer
r = sr.Recognizer()
with sr.Microphone() as source:
print('TARS is Ready...')
r.pause_threshold = 1
#wait for a second to let the recognizer adjust the
#energy threshold based on the surrounding noise level
r.adjust_for_ambient_noise(source, duration=1)
#listens for the user's input
audio = r.listen(source)
try:
command = r.recognize_google(audio).lower()
print('You said: ' + command + '\n')
#loop back to continue to listen for commands if unrecognizable speech is received
except sr.UnknownValueError:
print('Your last command couldn\'t be heard')
command = myCommand();
return command
In this function we are using SpeechRecognition library. It acts as a wrapper for several popular speech APIs and is thus extremely flexible. One of these—the Google Web Speech API—supports a default API key that is hard-coded into the SpeechRecognition library. That means you can get off your feet without having to sign up for a service.
To be able to work with your own voice with speech recognition, you need the PyAudio package. Like Recognizer for audio files, we will need Microphone for real-time speech data.
You can capture input from the microphone using the listen() method of the Recognizer class inside of the with block. This method takes an audio source as its first argument and records input from the source until silence is detected.
Try to say your commands in silence place( with less background noise ) otherwise TARS can confuse.
import random
def tars(command):
errors=[
"I don\'t know what you mean!",
"Excuse me?",
"Can you repeat it please?",
]
if 'Hello' in command:
talk('Hello! I am TARS. How can I help you?')
else:
error = random.choice(errors)
talk(error)
talk('TARS is ready!')
while True:
assistant(myCommand())
Once you run the program TARS will start talk with you by saying ‘TARS is ready!’ and continue to listen your commands until you stop the program. Start by saying ‘Hello’ :)
When TARS didn’t get the command we will handle the error by random sentences.
Here is the full code of main structure:
from gtts import gTTS
import speech_recognition as sr
from pygame import mixer
import random
def talk(audio):
print(audio)
for line in audio.splitlines():
text_to_speech = gTTS(text=audio, lang='en-uk')
text_to_speech.save('audio.mp3')
mixer.init()
mixer.music.load("audio.mp3")
mixer.music.play()
def myCommand():
#Initialize the recognizer
#The primary purpose of a Recognizer instance is, of course, to recognize speech.
r = sr.Recognizer()
with sr.Microphone() as source:
print('TARS is Ready...')
r.pause_threshold = 2
#wait for a second to let the recognizer adjust the
#energy threshold based on the surrounding noise level
r.adjust_for_ambient_noise(source, duration=1)
#listens for the user's input
audio = r.listen(source)
try:
command = r.recognize_google(audio).lower()
print('You said: ' + command + '\n')
#loop back to continue to listen for commands if unrecognizable speech is received
except sr.UnknownValueError:
print('Your last command couldn\'t be heard')
command = myCommand();
return command
def tars(command):
errors=[
"I don't know what you mean",
"Did you mean astronaut?",
"Can you repeat it please?",
]
if 'hello' in command:
talk('Hello! I am TARS. How can I help you?')
else:
error = random.choice(errors)
talk(error)
talk('TARS is ready!')
#loop to continue executing multiple commands
while True:
tars(myCommand())
Well… Is AI anything more than a bunch of IF statements?

If you are talking about “real” AI , then yes it’s a lot more than just If statements.The development of AI has historically been split into two fields; symbolic AI, and machine learning.
Symbolic AI is the field in which artificially intelligent systems were designed with if-else type logic. Programmers would attempt to define every possible scenario for the system to deal with. Until the late seventies this was the dominant form of AI system development. Experts in the field argued very strongly that machine-learning would never catch on and that AI could only be written in this way.
Now we know that accounting for every possible scenario in an intelligent system is enormously impractical and we use machine-learning instead. Machine learning uses statistics to look for and define patterns in data so that a machine can learn about and improve the tasks that it is designed to perform. This is significantly more flexible.
We are using just bunch of IF statements to understand basics of AI. But we will implement some cool ML algorithms later.
I hope you learned new things so far, now, it is time to teach TARS how to automate stuff.
Open Google and search for something
We are going to import webbrowser module in Python which provides an interface to display Web-based documents.
While we are saying commands, TARS have to detect availability of these commands by matching them. Python has a built-in package called re, which can be used to work with Regular Expressions.
import re
import webbrowser
if 'open google' in command:
#matching command to check it is available
reg_ex = re.search('open google (.*)', command)
url = 'https://www.google.com/'
if reg_ex:
subgoogle = reg_ex.group(1)
url = url + 'r/' + subreddit
webbrowser.open(url)
print('Done!')
The re.search() method takes a regular expression pattern and a string and searches for that pattern within the string. If the search is successful, search() returns a match object or None otherwise. Therefore, the search is usually immediately followed by an if-statement to test if the search succeeded
The code reg_ex = re.search(‘open google (.*)’, command) stores the search result in a variable named “reg_ex”. Then the if-statement tests the match – if true the search succeeded and group() is the matching text. Otherwise if the match is false (None to be more specific), then the search did not succeed, and there is no matching text. The 1 in reg_ex.group(1) represents the first parenthesized subgroup.
Even you can install Selenium to make search in Google by TARS. To install Selenium run the following command:
pip3 install selenium
Selenium WebDriver is a collection of open source APIs which are used to automate the testing of a web application. This tool is used to automate web application testing to verify that it works as expected. It supports many browsers such as Safari, Firefox, IE, and Chrome.
You can search how to use Selenium with Python there is a lot of sources on internet and it is really easy to learn. Let’s add this feature to TARS
from selenium import webdriver
from selenium.webdriver.common.keys import Keys
if 'open google and search' in command:
reg_ex = re.search('open google and search (.*)', command)
search_for = command.split("search",1)[1]
url = 'https://www.google.com/'
if reg_ex:
subgoogle = reg_ex.group(1)
url = url + 'r/' + subgoogle
talk('Okay!')
driver = webdriver.Firefox(executable_path='/path/to/geckodriver') #depends which web browser you are using
driver.get('http://www.google.com')
search = driver.find_element_by_name('q') # finds search
search.send_keys(str(search_for)) #sends search keys
search.send_keys(Keys.RETURN) #hits enter
I’m beginning the automate the boring stuff book and I’m trying to open a chrome web browser through python. I have already installed selenium and
I have tried to run this file:
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.common.keys import Keys
browser = webdriver.Chrome()
browser.get('https://automatetheboringstuff.com')
Send Email
We are going to import smtplib to send emails with Python. SMTP stands for Simple Mail Transfer Protocol and it is useful for communicating with mail servers to send mail.
import smtplib
elif 'email' or 'gmail' in command:
talk('What is the subject?')
time.sleep(3)
subject = myCommand()
talk('What should I say?')
time.sleep(3)
message = myCommand()
content = 'Subject: {}\n\n{}'.format(subject, message)
#init gmail SMTP
mail = smtplib.SMTP('smtp.gmail.com', 587)
#identify to server
mail.ehlo()
#encrypt session
mail.starttls()
#login
mail.login('your_gmail', 'your_gmail_password')
#send message
mail.sendmail('FROM', 'TO', content)
#end mail connection
mail.close()
talk('Email sent.')
Note that, in a nutshell, google is not allowing you to log in via smtplib because it has flagged this sort of login as “less secure”, so what you have to do is go to this link while you’re logged in to your google account, and allow the access.
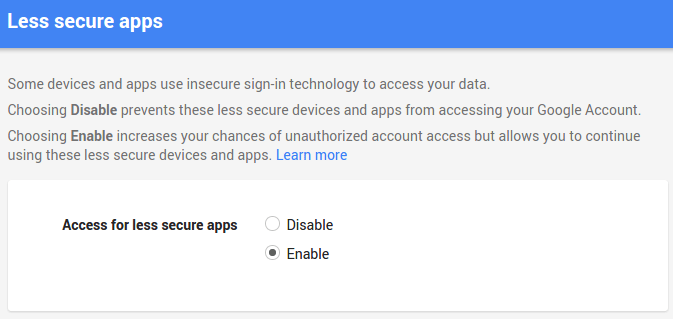
Still not working? Check this StackOverflow question
I am attempting to send an email in Python, through Gmail. Here is my code:
import smtplib
fromaddr = '......................'
toaddrs = '......................'
msg = 'Spam email Test'
username = '.......'
password = '.......'
server = smtplib.SMTP('smtp.gmail.com', 587)
server.ehlo()
server.starttls()
server.login(username, password)
server.sendmail(fromaddr, toaddrs, msg)
server.quit()
Crawl Data
We are doing great so far! TARS can send mails and search whatever you want on google. Now, let’s implement more complex function to make TARS crawl some Wikipedia data and read it for us.
Beautiful Soup is a Python library for pulling data out of HTML and XML files. It works with your favorite parser to provide idiomatic ways of navigating, searching, and modifying the parse tree. It commonly saves programmers hours or days of work. Run the following command in your terminal to install beautifulsoup:
pip install beautifulsoup4
We also will need requests library for making HTTP requests in Python. It abstracts the complexities of making requests behind a beautiful, simple API so that you can focus on interacting with services and consuming data in your application. Alright! Let’s see the code:
import bs4
import requests
elif 'wikipedia' in command:
reg_ex = re.search('search in wikipedia (.+)', command)
if reg_ex:
query = command.split()
response = requests.get("https://en.wikipedia.org/wiki/" + query[3])
if response is not None:
html = bs4.BeautifulSoup(response.text, 'html.parser')
title = html.select("#firstHeading")[0].text
paragraphs = html.select("p")
for para in paragraphs:
print (para.text)
intro = '\n'.join([ para.text for para in paragraphs[0:5]])
print (intro)
mp3name = 'speech.mp3'
language = 'en'
myobj = gTTS(text=intro, lang=language, slow=False)
myobj.save(mp3name)
mixer.init()
mixer.music.load("speech.mp3")
mixer.music.play()
elif 'stop' in command:
mixer.music.stop()
“search in wikipedia Mars” and TARS will take “Mars” as a keyword to search in Wikipedia. If you search something on Wikipedia you will see URL will look like https://en.wikipedia.org/wiki/Keyword so we are sending get request with keyword(what to search) to access data. Once request succeed, beautifulsoup will parse content inside Wikipedia. The join() method is a string method and returns a string in which the elements of sequence have been joined by str separator and we are using it to separate paragraphs. You already familiar with gTTS and mixer so I am passing that part.
TARS will display the crawled data on console and start to reading it for you.
Search videos on YouTube and play
This function is similar to search with google but this time it is better to use urllib. The main objective is to learn new things with Python, so I don’t want include Selenium in this function. Here is the code:
import urllib.request #used to make requests
import urllib.parse #used to parse values into the url
elif 'youtube' in command:
talk('Ok!')
reg_ex = re.search('youtube (.+)', command)
if reg_ex:
domain = command.split("youtube",1)[1]
query_string = urllib.parse.urlencode({"search_query" : domain})
html_content = urllib.request.urlopen("http://www.youtube.com/results?" + query_string)
search_results = re.findall(r'href=\"\/watch\?v=(.{11})', html_content.read().decode()) # finds all links in search result
webbrowser.open("http://www.youtube.com/watch?v={}".format(search_results[0]))
pass
The urllib module in Python 3 allows you access websites via your program. This opens up as many doors for your programs as the internet opens up for you. urllib in Python 3 is slightly different than urllib2 in Python 2, but they are mostly the same. Through urllib, you can access websites, download data, parse data, modify your headers, and do any GET and POST requests you might need to do.
Check this tutorial for more about urllib
Search key must be encoded before parsing into url. If you search something on YouTube you can see after http://www.youtube.com/results?" there is a encoded search keys. Once these search keys encoded program can successfully access search results. The expression re.findall() returns all the non-overlapping matches of patterns in a string as a list of strings. Each video on youtube has its own 11 characters ID (https://www.youtube.com/watch?v=gEPmA3USJdI)and re.findall() will find all matches in decoded html_content(in search results page). decode() is used to convert from one encoding scheme, in which argument string is encoded to the desired encoding scheme. This works opposite to the encode. It accepts the encoding of the encoding string to decode it and returns the original string. Finally, it plays first video in search results because usually the first video is nearest one for search keys.
Full Code:
from gtts import gTTS
import speech_recognition as sr
import re
import time
import webbrowser
import random
from selenium import webdriver
from selenium.webdriver.common.keys import Keys
import smtplib
import requests
from pygame import mixer
import urllib.request
import urllib.parse
import bs4
def talk(audio):
"speaks audio passed as argument"
print(audio)
for line in audio.splitlines():
text_to_speech = gTTS(text=audio, lang='en-uk')
text_to_speech.save('audio.mp3')
mixer.init()
mixer.music.load("audio.mp3")
mixer.music.play()
def myCommand():
"listens for commands"
#Initialize the recognizer
#The primary purpose of a Recognizer instance is, of course, to recognize speech.
r = sr.Recognizer()
with sr.Microphone() as source:
print('TARS is Ready...')
r.pause_threshold = 1
#wait for a second to let the recognizer adjust the
#energy threshold based on the surrounding noise level
r.adjust_for_ambient_noise(source, duration=1)
#listens for the user's input
audio = r.listen(source)
print('analyzing...')
try:
command = r.recognize_google(audio).lower()
print('You said: ' + command + '\n')
time.sleep(2)
#loop back to continue to listen for commands if unrecognizable speech is received
except sr.UnknownValueError:
print('Your last command couldn\'t be heard')
command = myCommand();
return command
def tars(command):
errors=[
"I don't know what you mean",
"Excuse me?",
"Can you repeat it please?",
]
"if statements for executing commands"
# Search on Google
if 'open google and search' in command:
reg_ex = re.search('open google and search (.*)', command)
search_for = command.split("search",1)[1]
print(search_for)
url = 'https://www.google.com/'
if reg_ex:
subgoogle = reg_ex.group(1)
url = url + 'r/' + subgoogle
talk('Okay!')
driver = webdriver.Firefox(executable_path='/home/coderasha/Desktop/geckodriver')
driver.get('http://www.google.com')
search = driver.find_element_by_name('q')
search.send_keys(str(search_for))
search.send_keys(Keys.RETURN) # hit return after you enter search text
#Send Email
elif 'email' in command:
talk('What is the subject?')
time.sleep(3)
subject = myCommand()
talk('What should I say?')
message = myCommand()
content = 'Subject: {}\n\n{}'.format(subject, message)
#init gmail SMTP
mail = smtplib.SMTP('smtp.gmail.com', 587)
#identify to server
mail.ehlo()
#encrypt session
mail.starttls()
#login
mail.login('your_mail', 'your_mail_password')
#send message
mail.sendmail('FROM', 'TO', content)
#end mail connection
mail.close()
talk('Email sent.')
# search in wikipedia (e.g. Can you search in wikipedia apples)
elif 'wikipedia' in command:
reg_ex = re.search('wikipedia (.+)', command)
if reg_ex:
query = command.split("wikipedia",1)[1]
response = requests.get("https://en.wikipedia.org/wiki/" + query)
if response is not None:
html = bs4.BeautifulSoup(response.text, 'html.parser')
title = html.select("#firstHeading")[0].text
paragraphs = html.select("p")
for para in paragraphs:
print (para.text)
intro = '\n'.join([ para.text for para in paragraphs[0:3]])
print (intro)
mp3name = 'speech.mp3'
language = 'en'
myobj = gTTS(text=intro, lang=language, slow=False)
myobj.save(mp3name)
mixer.init()
mixer.music.load("speech.mp3")
while mixer.music.play()
elif 'stop' in command:
mixer.music.stop()
# Search videos on Youtube and play (e.g. Search in youtube believer)
elif 'youtube' in command:
talk('Ok!')
reg_ex = re.search('youtube (.+)', command)
if reg_ex:
domain = command.split("youtube",1)[1]
query_string = urllib.parse.urlencode({"search_query" : domain})
html_content = urllib.request.urlopen("http://www.youtube.com/results?" + query_string)
search_results = re.findall(r'href=\"\/watch\?v=(.{11})', html_content.read().decode())
#print("http://www.youtube.com/watch?v=" + search_results[0])
webbrowser.open("http://www.youtube.com/watch?v={}".format(search_results[0]))
pass
elif 'hello' in command:
talk('Hello! I am TARS. How can I help you?')
time.sleep(3)
elif 'who are you' in command:
talk('I am one of four former U.S. Marine Corps tactical robots')
time.sleep(3)
else:
error = random.choice(errors)
talk(error)
time.sleep(3)
talk('TARS activated!')
#loop to continue executing multiple commands
while True:
time.sleep(4)
tars(myCommand())
Cool! We just created demo TARS and I hope you learned many things from this lab. Please feel free to contribute this project on GitHub, TARS will wait for improvements.
#python #webdev