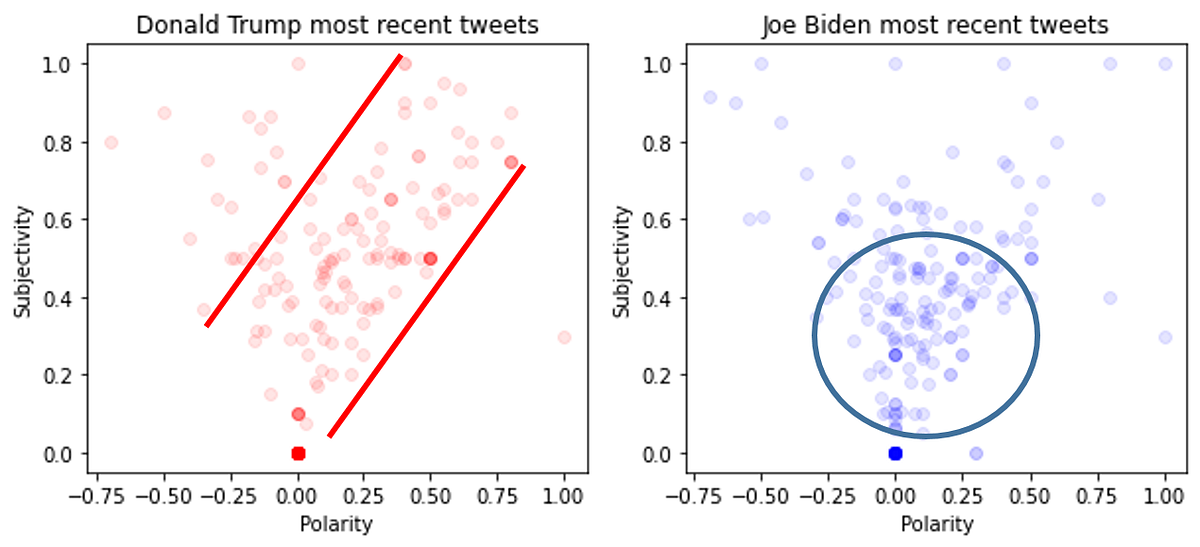
In 5 months, US voters will head to the polls and choose their next President. The presumptive nominees — Donald Trump and Joe Biden have been engaging with the public to promote their political agendas in social media platforms like Twitter in order to win votes. This post will analyze the tweets of Trump and Biden using a machine learning technique called Natural Language Processing.
The python code notebooks I used in the post are available here and here.
Tweets are available for download off Twitter APIs as long as you have the necessary security keys. You can request from Twitter here https://developer.twitter.com/en/apply-for-access to get your own keys. Once you received the keys, type them in this code and run it in Python to download the tweets of Donald Trump and Joe Biden.
import twitter
import json
# Note: Go to https://developer.twitter.com/en/apply-for-access to get your own secret keys.
api = twitter.Api(consumer_key = '---',
consumer_secret = '---',
access_token_key = '---',
access_token_secret = '---',cache=None, tweet_mode='extended')
I ran the code on June 19, 2020 and was able to retrieve around 3200 tweets posted by Donald Trump and Joe Biden. I uploaded their tweets here and here and their Python list object pickles here and here
Let’s load their tweets and display the first 500 characters:
import requests
candidates = ['DonaldTrump', 'JoeBiden']
data = {}
for i, c in enumerate(candidates):
url = "https://raw.githubusercontent.com/gomachinelearning/Blogs/master/" + c + "Tweets.txt"
req = requests.get(url)
data[c] = req.text
# check the sizes: Count the number of characters
print("Verify the dictionary variables are not empty. Print total number of characters in the variables:\n")
print("Donald Trump: {} , Joe Biden: {}".format(len(data['DonaldTrump']) ,len(data['JoeBiden'])))
def print_first_n_characters(n):
if n == -1:
print('Printing full tweets of each candidate \n'.format(n) )
else:
print('\n\nPrinting the first {} characters of tweets of each candidate \n'.format(n) )
print('DONALD TRUMP: \n ' + data['DonaldTrump'][0:n])
print('\n\nJOE BIDEN: \n ' + data['JoeBiden'][0:n])
print_first_n_characters(500)
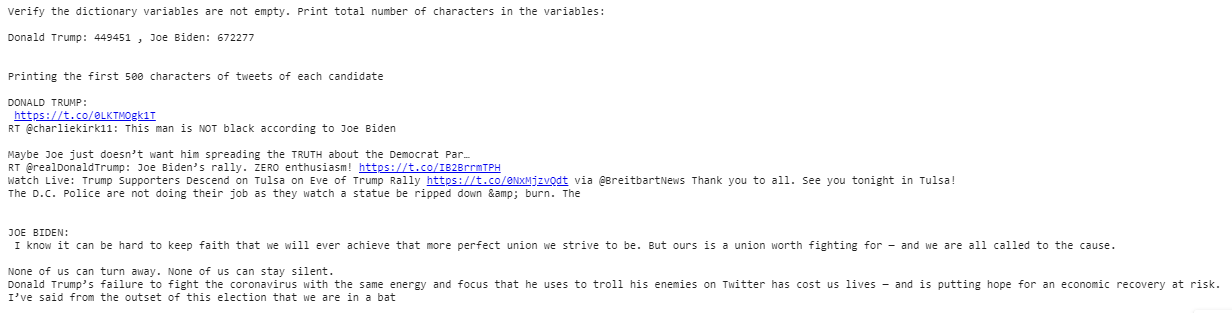
Figure 1: Printing sample tweets of Trump and Biden
One interesting observation is that, overall, Joe Biden tweet’s are longer compared to Trump’s.
import pickle
import cloudpickle as cp
lst_donald_trump_tweets=[]
lst_joe_biden_tweets=[]
from urllib.request import urlopen
lst_donald_trump_tweets = cp.load(urlopen("https://raw.githubusercontent.com/gomachinelearning/Blogs/master/DonaldTrumpTweets.pickle"))
lst_joe_biden_tweets = cp.load(urlopen("https://raw.githubusercontent.com/gomachinelearning/Blogs/master/JoeBidenTweets.pickle"))
print("AVerage Number of characters per tweet:\n")
print("Donald Trump: {} , Joe Biden: {}".format(round(len(data['DonaldTrump'])/len(lst_donald_trump_tweets)) , round(len(data['JoeBiden'])/len(lst_joe_biden_tweets))))

Figure 2: On average, Biden’s tweets are longer per tweet compared to Trump’s
Visualize the Data
Wordle, also known as word cloud or tag cloud, is a visual representation of text data in the form of tags. A tag is usually a word in the data whose importance is visualized as font size and color.
Wordle has its own share of strengths and weaknesses and I’ve heard some criticisms about it. But let’s use it for now just to have a quick look and get an idea of what kind of data we’re dealing with.
#machine-learning #donald-trump #sentiment-analysis #joe-biden #naturallanguageprocessing #deep learning