Let’s split data 70:30, train model and test the given data-set to get accuracy. The major drawback of this method is that we perform training on the 70% of the data-set, it’s highly possible that the remaining 30% of the data contains some important information which are left out while training our model i.e higher bias.So we can’t be 100 % sure that the model will work accurately for the real production data which is unseen. For this, we must assure that our model get the correct patterns from the data, and it is not getting up too much noise. For this purpose, we use the cross-validation technique.
Cross-validation is used to evaluate machine learning models on a limited data sample.It estimates the skill of a machine learning model on unseen data.
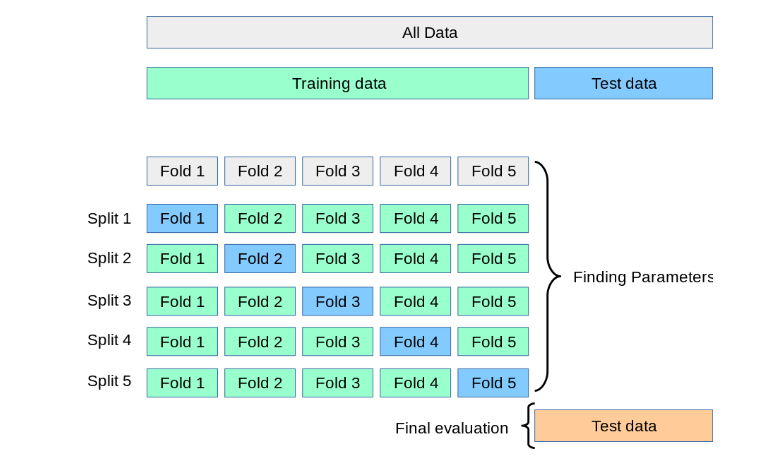
K-Fold Pictorial Description
The techniques creates and validates given model multiple times. We have 2–4 types of cross validation like Stratified, LOOCV, K-Fold etc. Here, we will study K-Fold technique.
K-Fold
This means that each sample is given the opportunity to be used in the hold out set 1 time and used to train the model k-1 times.By splitting our data into three sets instead of two, we’ll tackle all the same issues we talked about before, especially if we don’t have a lot of data. By doing cross-validation, we’re able to do all those steps using a single set.To perform K-Fold we need to keep aside a sample/portion of the data which is not used to train the model.
Cross validation procedure
1. Shuffle the dataset randomly>>Split the dataset into k folds
2. For each distinct fold: a. Keep the fold data separate / hold out data set b. Use the remaining folds as a single training data set c. Fit the model on the training set and evaluate it on the test set d. Retain the evaluation score and discard the model e. Loop back
3. Executed steps K times
5. Summarize the scores and average it by dividing the sum by K.
6. Analyze the average score, the dispersion to assess the likely performance of the model in the unseen data (production data / universe)
When K = n (i.e of datapoints) — then its LOOCV
Ideal value of K is 5–10 based on data.The higher value of K leads to less biased model, where as the lower value of K is similar to 70:30.
Code Sample :-
from sklearn import cross_validation
# value of K is 10.
data = cross_validation.KFold(len(train_set), n_folds=10, indices=False)

Python Code
Here we repeat the model evaluation process multiple times (instead of one time) and calculate the mean of result score.Standard deviation varies w.r.t Confidence level i.e Mean + 2S.D. So if we get mean score as 80% then on production data it may vary w.r.t to 2S.D.
All the Best ! Keep Learning.
#machine-learning #data-science