I will start a new series of articles about what I build and what I learn during the weekend.
As I mentioned before, to be a great Engineering Leader, I always believe that we should know how to “fight.”
This weekend, I will build a batch-based product data pipeline by using GCP stacks.
Here is the Data Flow.
- We are going to scrape the Amazon Audible website. And mock as the Product data source. (Disclaimer this is only for self-learning propers)
- Using Apache Beam + DataFlow processes the data transformation.
- We will upload the data to the GCS.
- Load the data to the BigQuery.
Let’s start with the high-level of architecture.

Batch Data Pipeline with GCP stacks
Web Scraping
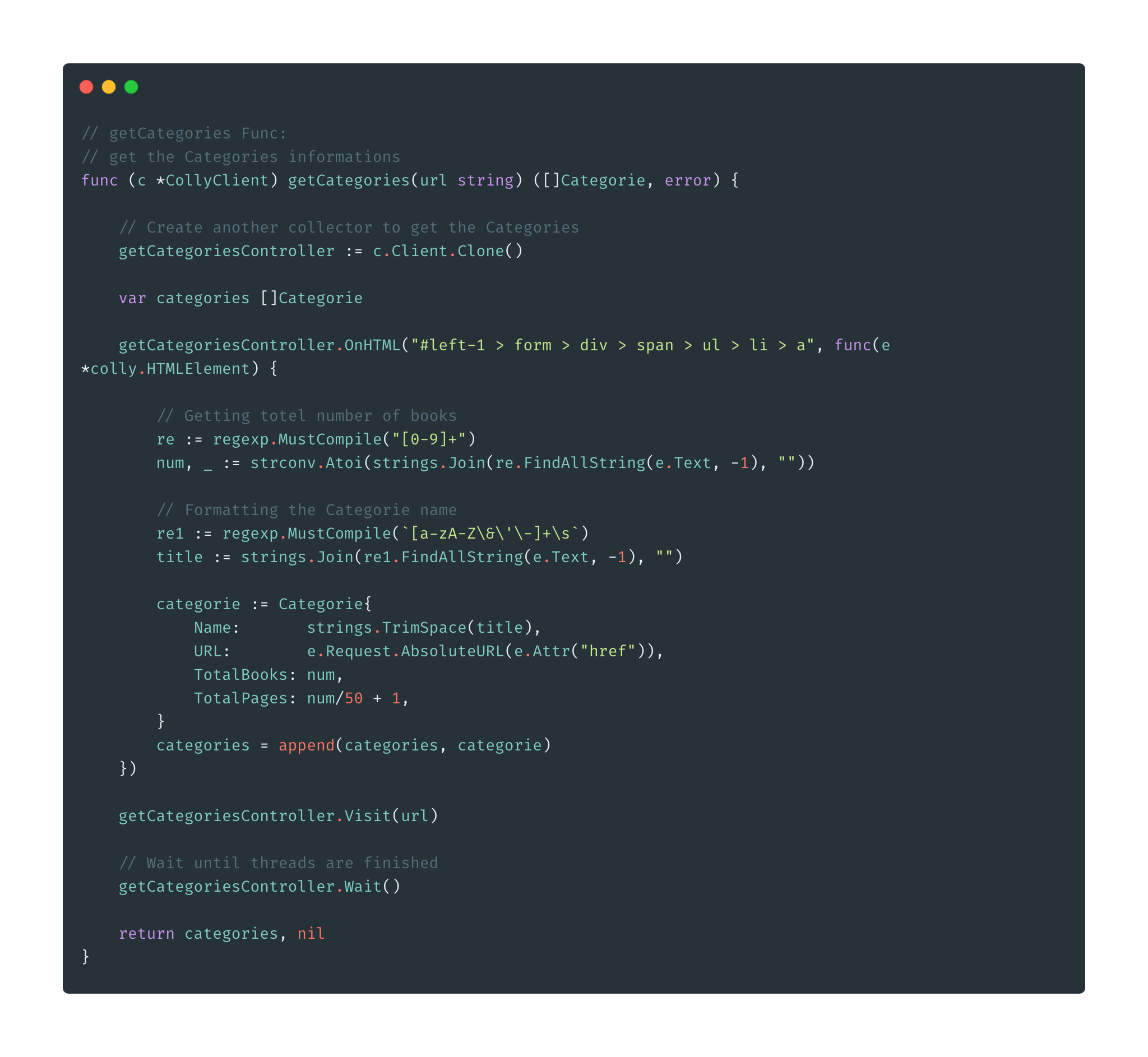
We are going to scrape the Audible entire 515,845 items by using the most excellent Go concurrency feature. Here are the details steps:
- Scraping the Category page and get each category link and total page of each category have.
#apache-beam #go #self-improvement #data-pipeline #data-science
2.60 GEEK