Much of the success of deep learning has come from building larger and larger neural networks. This allows these models to perform better on various tasks, but also makes them more expensive to use. Larger models take more storage space which makes them harder to distribute. Larger models also take more time to run and can require more expensive hardware. This is especially a concern if you are productionizing a model for a real-world application.
Model compression aims to reduce the size of models while minimizing loss in accuracy or performance. Neural network pruning is a method of compression that involves removing weights from a trained model. In agriculture, pruning is cutting off unnecessary branches or stems of a plant. In machine learning, pruning is removing unnecessary neurons or weights. We will go over some basic concepts and methods of neural network pruning.
Remove weights or neurons?
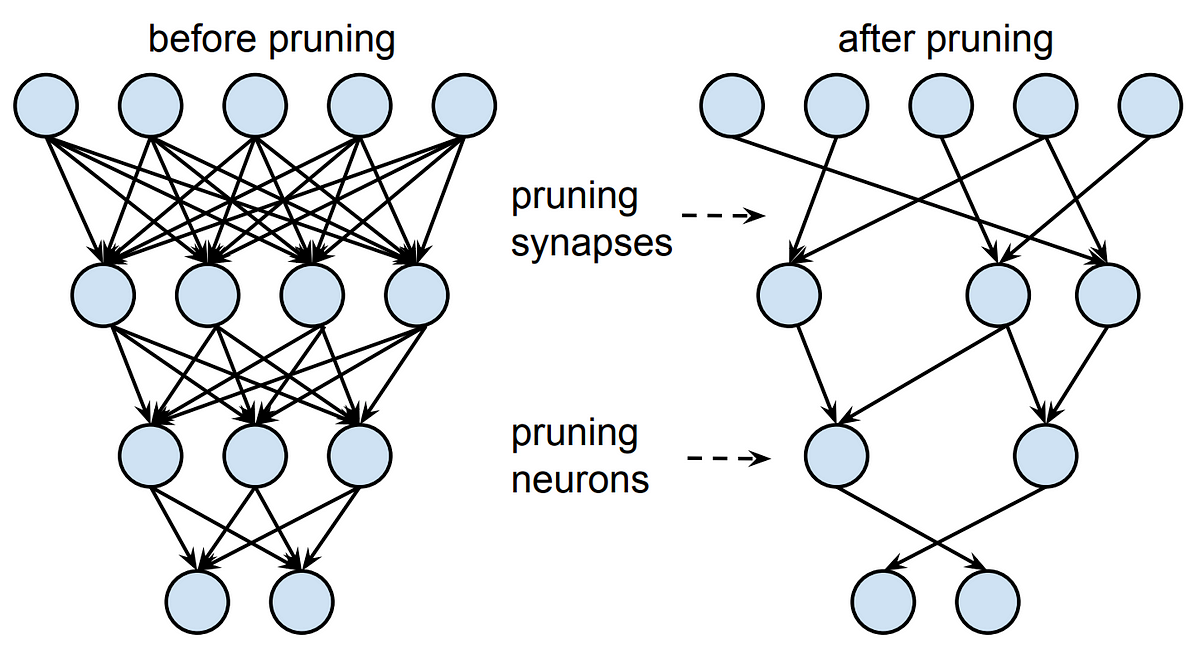
There are different ways to prune a neural network. (1) You can prune weights. This is done by setting individual parameters to zero and making the network sparse. This would lower the number of parameters in the model while keeping the architecture the same. (2) You can remove entire nodes from the network. This would make the network architecture itself smaller, while aiming to keep the accuracy of the initial larger network.
Visualization of pruning weights/synapses vs nodes/neurons (Source)
Weight-based pruning is more popular as it is easier to do without hurting the performance of the network. However, it requires sparse computations to be effective. This requires hardware support and a certain amount of sparsity to be efficient.
Pruning nodes will allow dense computation which is more optimized. This allows the network to be run normally without sparse computation. This dense computation is more often better supported on hardware. However, removing entire neurons can more easily hurt the accuracy of the neural network.
What to prune?
A major challenge in pruning is determining what to prune. If you are removing weights or nodes from a model, you want the parameters you remove to be less useful. There are different heuristics and methods of determining which nodes are less important and can be removed with minimal effect on accuracy. You can use heuristics based on the weights or activations of a neuron to determine how important it is for the model’s performance. The goal is to remove more of the less important parameters.
One of the simplest ways to prune is based on the magnitude of the weight. Removing a weight is essentially setting it to zero. You can minimize the effect on the network by removing weights that are already close to zero, meaning low in magnitude. This can be implemented by removing all weights below a certain threshold. To prune a neuron based on weight magnitude you can use the L2 norm of the neuron’s weights.
Rather than just weights, activations on training data can be used as a criteria for pruning. When running a dataset through a network, certain statistics of the activations can be observed. You may observe that some neurons always outputs near-zero values. Those neurons can likely be removed with little impact on the model. The intuition is that if a neuron rarely activates with a high value, then it is rarely used in the model’s task.
#deep-learning #pruning #artificial-intelligence #compression #machine-learning