In this article, we will understand the concept and code for dueling double deep q learning. This involves some improvement techniques applied to the Deep Q learning method. Let’s first understand the concept behind this method and then we will explore the code.
Double DQN
This technique addresses the problem of overestimation in DQN. This overestimation occurs due to the presence of Max of Q value for the next state in the Q learning update equation. This max operator on Q value leads to maximization bias, which can result in bad performance by the agent in certain environments where the maximum of true value is zero, but the maximum estimate by the agent is positive.

Double Q learning update, image via Reinforcement Learning:
An Introduction by Richard S. Sutton and Andrew G. Barto
We will use the Deep RL version of the above equation in our code.
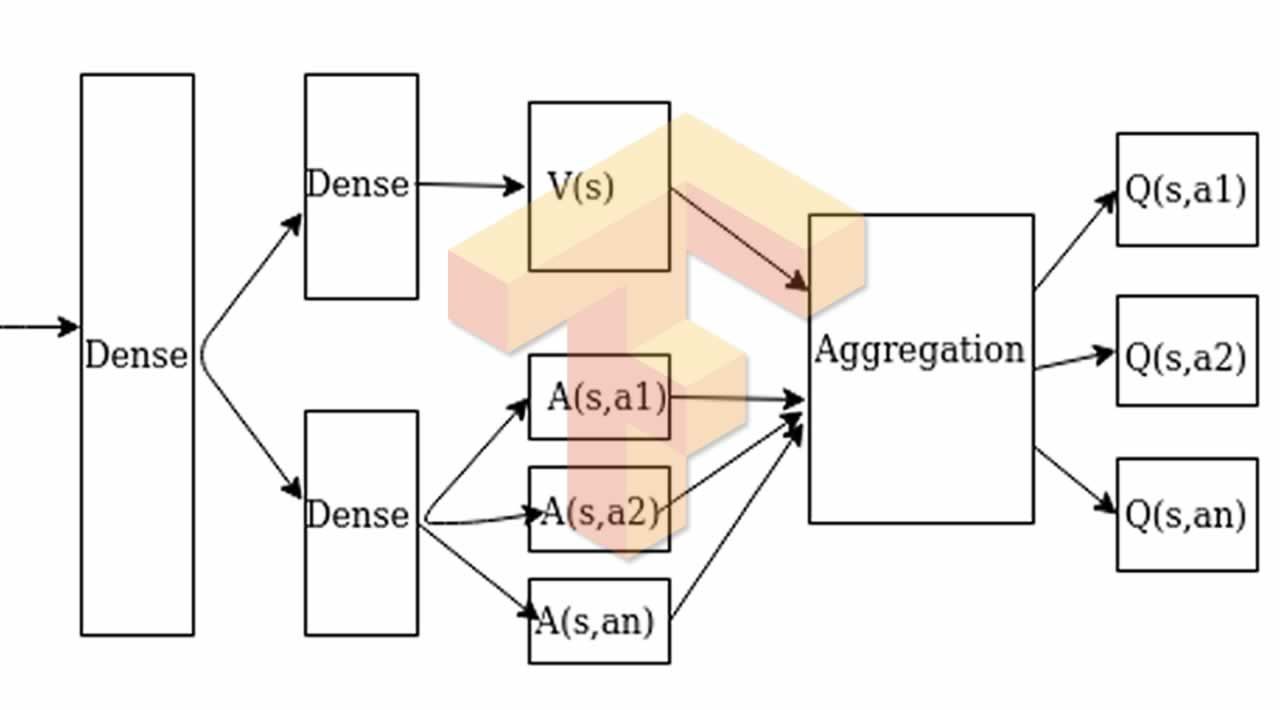
Dueling DQN
In dueling DQN, there are two different estimates which are as follows:
- Estimate for the value of a given state: This estimates how good it is for an agent to be in that state.
- Estimate for the advantage of each action in a state.
Our DDDQN
These two estimates can be aggregated as [Q = V + A — mean of all A]
#machine-learning #tensorflow #data-science #ai