In one of my previous posts, I talked about topic modeling with BERT which involved a class-based version of TF-IDF. This version of TF-IDF allowed me to extract interesting topics from a set of documents.
I thought it might be interesting to go a little bit deeper into the method since it can be used for many more applications than just topic modeling!
An overview of the possible applications:
- Informative Words per Class: Which words make a class stand-out compared to all others?
- **Class Reduction: **Using c-TF-IDF to reduce the number of classes
- **Semi-supervised Modeling: **Predicting the class of unseen documents using only cosine similarity and c-TF-IDF
This article will mostly go into the applications of **c-TF-IDF** but some background on the model will also be given.
If you want to skip all of that and go directly go to the code you can start from the repo here.
Class-based TF-IDF
Before going into the possibilities of this class-based TF-IDF, let us first look at how TF-IDF works and the steps we need to take to transform it into c-TF-IDF.
TF-IDF
TF-IDF is a method for generating features from textual documents which is the result of multiplying two methods:
- Term Frequency (TF)
- Inverse Document Frequency (IDF)
The term frequency is simply the raw count of words within a document where each word count is considered a feature.
Inverse document frequency extracts how **informative **certain words are by calculating a word’s frequency in a document compared to its frequency across all other documents.
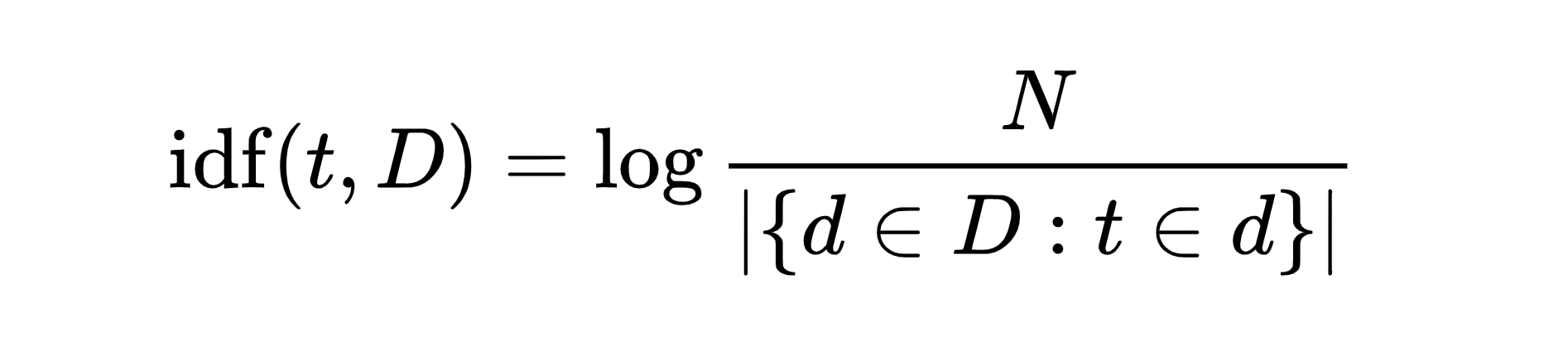
#nlp #python #scikit-learn #machine-learning #data-science
