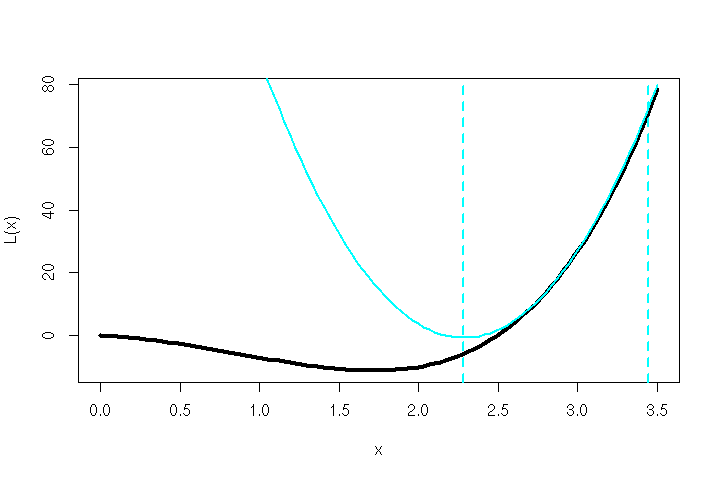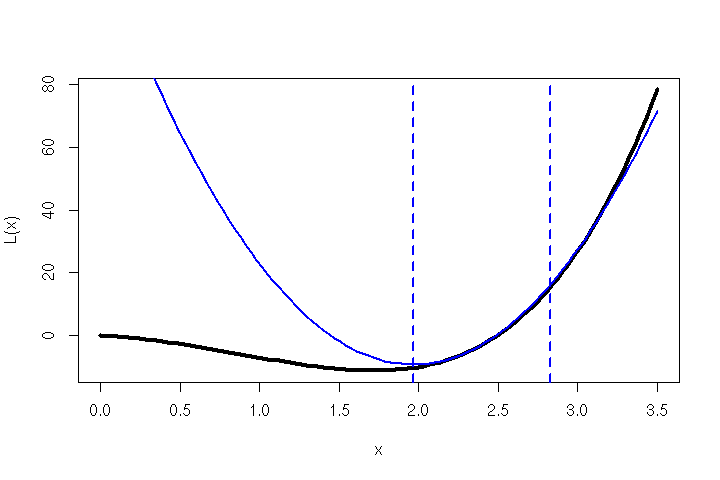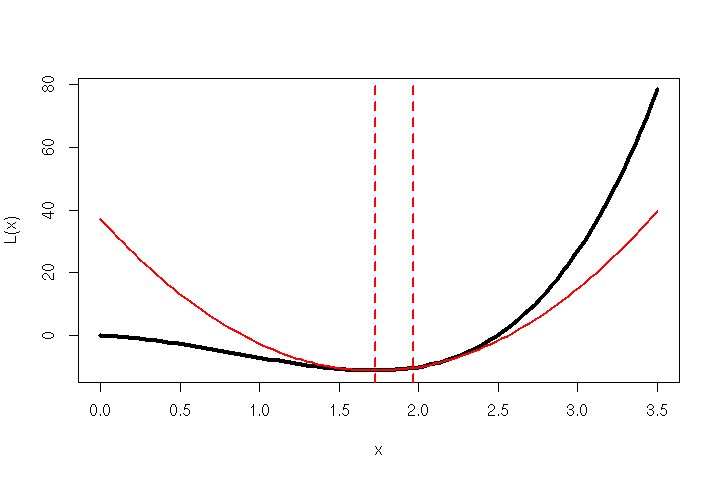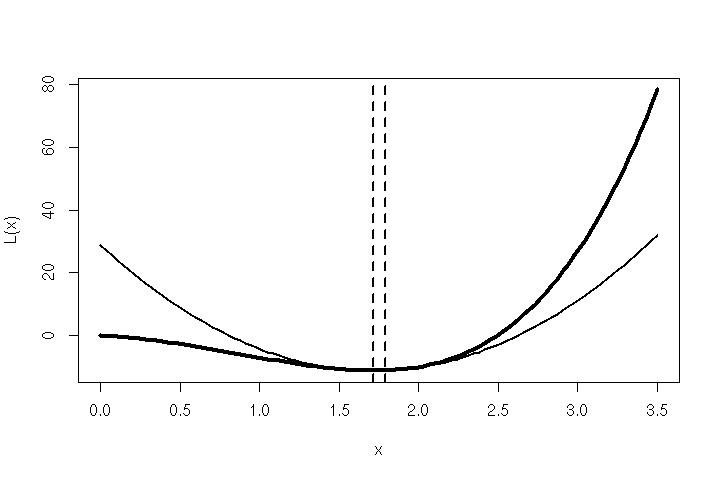
Due to the slowly converging nature of the vanilla back-propagation algorithms of the ’80s/’90s, Scott Fahlman invented a learning algorithm dubbed Quickprop [1] that is roughly based on Newton’s method. His simple idea outperformed back-propagation (with various adjustments) on problem domains like the ‘N-M-N Encoder’ task — i.e. training a de-/encoder network with N inputs, M hidden units and N outputs.
One of the problems that Quickprop specifically tackles is the issue of finding a domain-specific optimal learning rate, or rather: an algorithm that adjusts it appropriately dynamically.
In this article, we’ll look at the simple mathematical idea behind Quickprop. We’ll implement the basic algorithm and some improvements that Fahlman suggests — all in Python and PyTorch.
A rough implementation of the algorithm and some background can already be found in this useful blog post by Giuseppe Bonaccorso. We are going to expand on that — both on the theory and code side — but if in doubt, have a look at how Giuseppe explains it.
The motivation to look into Quickprop came from writing my last article on the “Cascade-Correlation Learning Architecture” [2]. There, I used it to train the neural network’s output and hidden neurons, which was a mistake I realized only later and which we’ll also look into here.
To follow along with this article, you should be familiar with how neural networks can be trained using back-propagation of the loss gradient (as of 2020, a widely used approach). That is, you should understand how the gradient is usually calculated and applied to the parameters of a network to try to iteratively achieve convergence of the loss to a global minimum.
Overview
We’ll start with the mathematics behind Quickprop and then look at how it can be implemented and improved step by step.
To make following along easier, any equations used and inference steps done are explained in more detail than in the original paper.
The Mathematics Behind Quickprop
The often used learning method of back-propagation for neural networks is based on the idea of iteratively ‘riding down’ the slop of a function, by taking short steps in the inverse direction of its gradient.
These ‘short steps’ are the crux here. Their length usually depends on a learning rate factor, and that is kept intentionally small to not overshoot a potential minimum.
#python #pytorch #quickprop #artificial-intelligence #machine-learning