Background
Missing observations are common in time series data and several methods are available to impute these values prior to analysis. Variation in statistical characteristics of univariate time series can have a profound effect on the characteristics of missing observations and, therefore, the accuracy of different imputation methods.
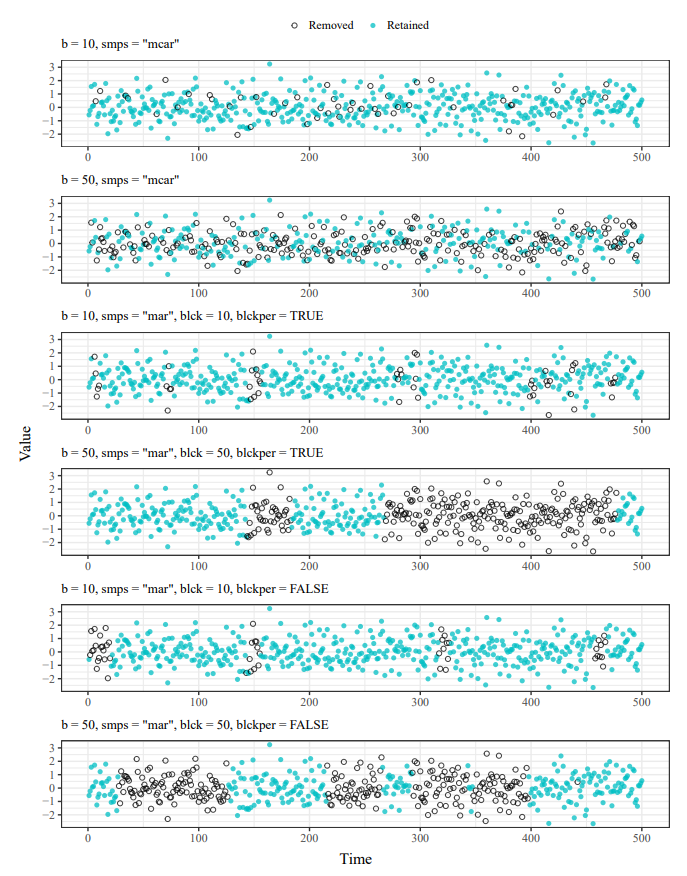
The imputeTestbench package can be used to compare the prediction accuracy of different methods as related to the amount and type of missing data for a user-supplied dataset. Missing data are simulated by removing observations completely at random or in blocks of different sizes depending on the characteristics of the data. Several imputation algorithms are included with the package that varies from simple replacement with means to more complex interpolation methods. The testbench is not limited to the default functions and users can add or remove methods as needed. Plotting functions also allow comparative visualization of the behavior and effectiveness of different algorithms.
This post present example of applications that demonstrate how the package can be used to understand differences in prediction accuracy between methods as affected by characteristics of a dataset and nature of missing data.
Missing Value Imputation
Identifying an appropriate imputation method is often the first step towards a more formal time series analysis. Different imputation methods will have differing precision in reproducing missing values, where precision will depend on how much data are missing and how the data are missing (i.e., individual observations missing at random or data missing in continuous chunks). The characteristics of the dataset will also influence imputation precision between methods.
An expectation is that imputation methods that leverage characteristics of the dataset to predict missing values will perform better than more naïve methods if indeed there is sufficient temporal structure. Accordingly, choosing an appropriate imputation method can be facilitated by using a standardized method of comparison.
A simple approach for method comparison is to evaluate prediction accuracy from imputed values after removing observations from a test dataset, where the test dataset should have characteristics similar to the one requiring imputation.
In such an approach, the imputation methods are compared by simulating different amounts of missing data, predicting the missing values with each method, and then comparing the predictions to the actual data that were removed. Then, the accuracy of predicted values is checked with statistical methods such as root-mean-squared error (RMSE) between observed and predicted data for each imputation method after removing and predicting 10% and 80% of the complete dataset.
In order to automate such a procedure, the imputeTestbench package is proposed, to simultaneously compare different imputation methods for univariate time series. The goal of this package is to provide an evaluation toolset that addresses the above challenges for identifying an appropriate imputation method before a more detailed analysis. This package provides several options for simulating missing observations with repeated sampling from a complete dataset. Missing values are imputed using any of several methods and then compared with a common error metric chosen by the user. Plotting functions are available to visualize the simulation methods for missing data, the predicted time series from each method, and the overall evaluation of prediction accuracy between methods.
Following is the theoretical foundation of imputeTestbench.
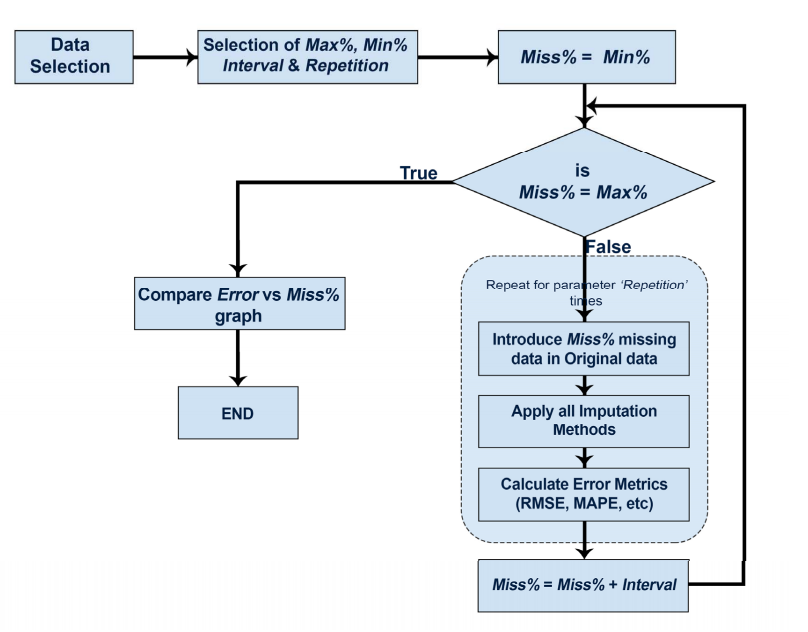
The theoretical foundation of imputeTestbench
Overview of imputeTestbench
Components of the workflow in the above figure are executed with the functions in imputeTestbench. The primary function is_ impute_errors()_ which is used to evaluate different imputation methods with missing data that are randomly generated from a complete dataset. The sample_dat() function is used to generate missing data within impute_errors() and includes a plotting option to demonstrate how the missing data are generated. The default error metrics for the imputed data are in the error_functions() function. The remaining two functions, plot_impute() and plot_errors(), are used to visualize imputation results and error summaries for the chosen methods.
#r #time-series-analysis #data-science #research #missing-data #data analysis