Initialization & Transfer Learning

Deep Learning at FAU
These are the lecture notes for FAU’s YouTube Lecture “Deep Learning”. This is a full transcript of the lecture video & matching slides. We hope, you enjoy this as much as the videos. Of course, this transcript was created with deep learning techniques largely automatically and only minor manual modifications were performed. If you spot mistakes, please let us know!
Navigation
Previous Lecture** / Watch this Video / Top Level / **Next Lecture
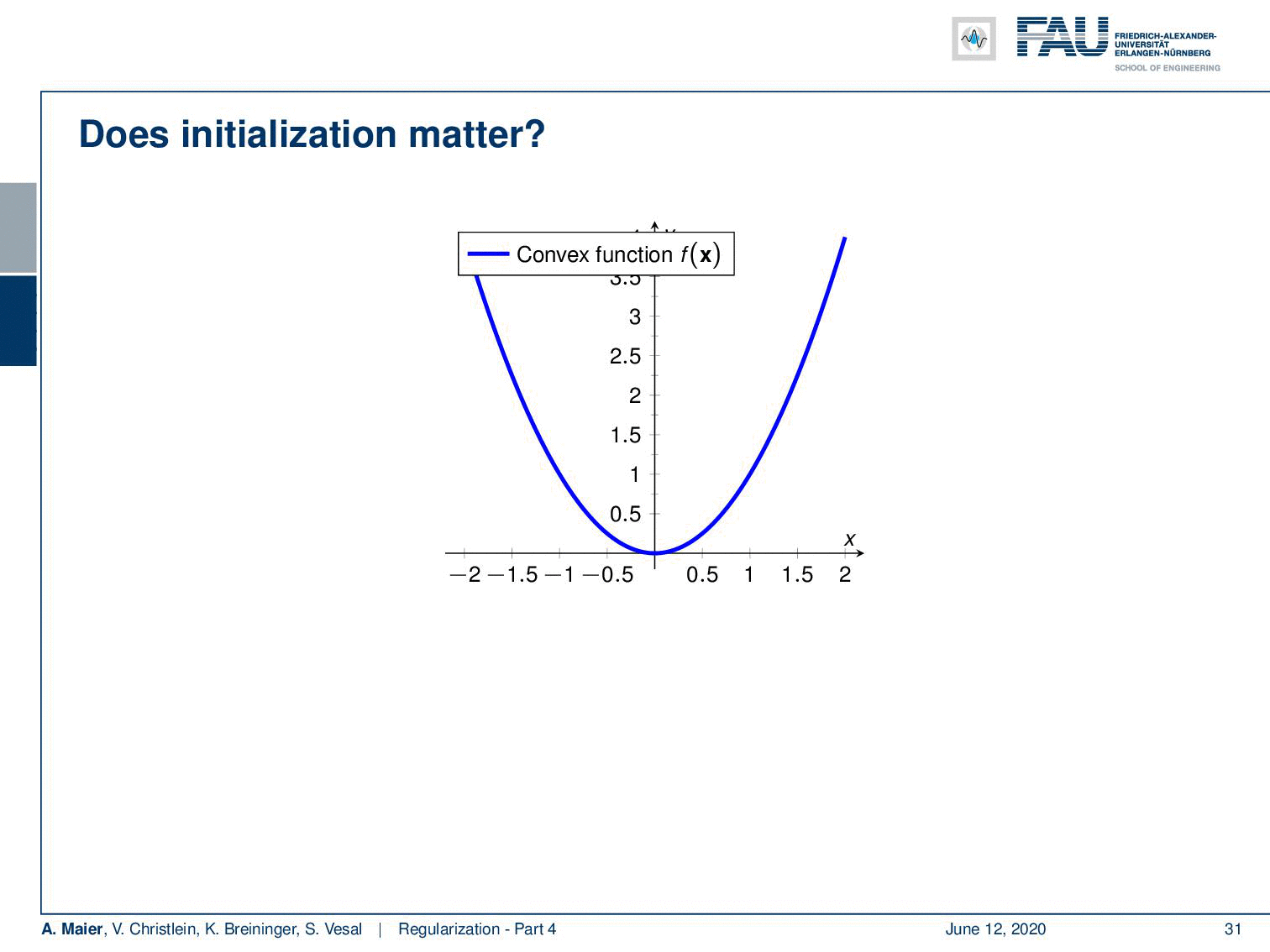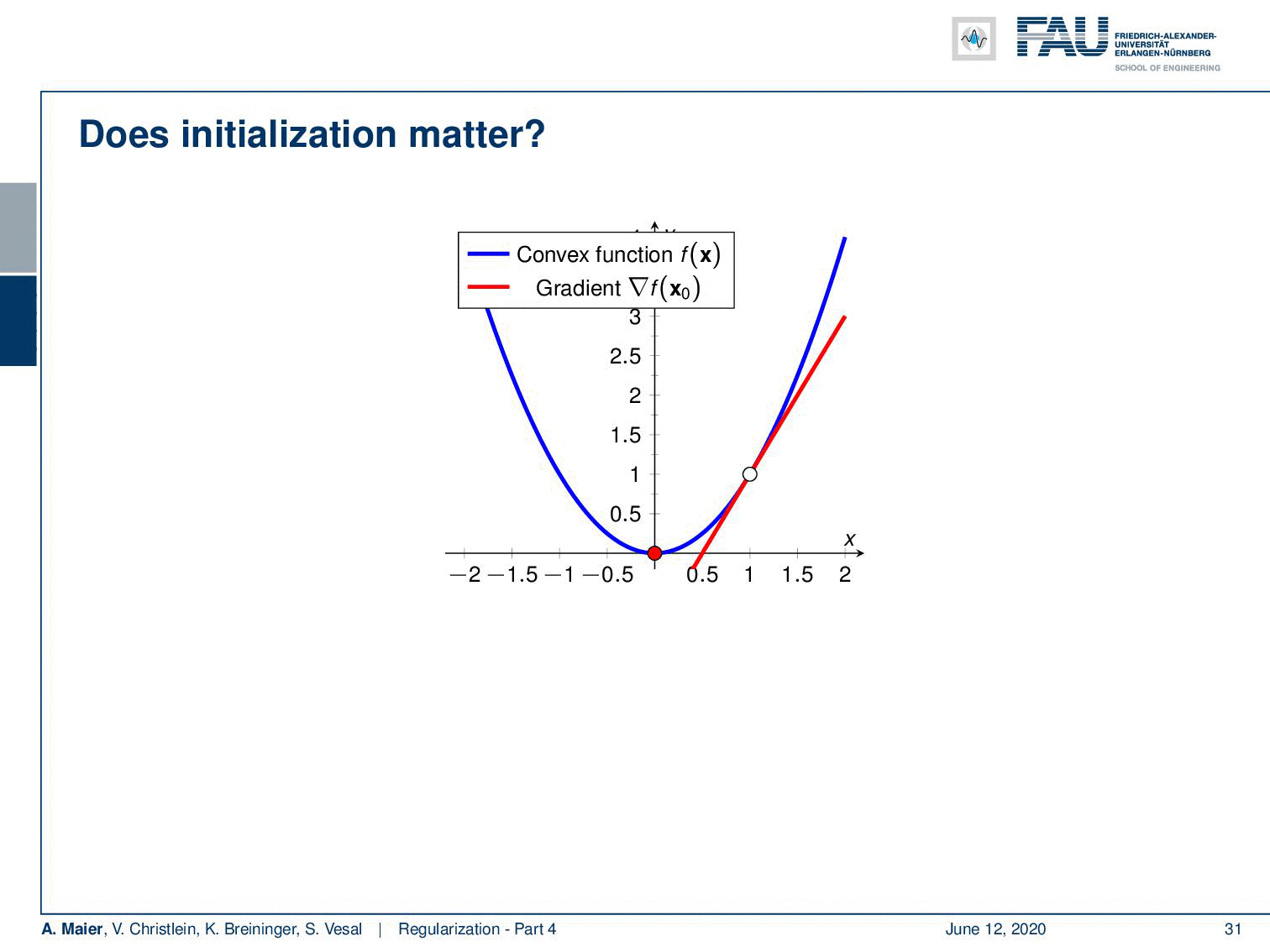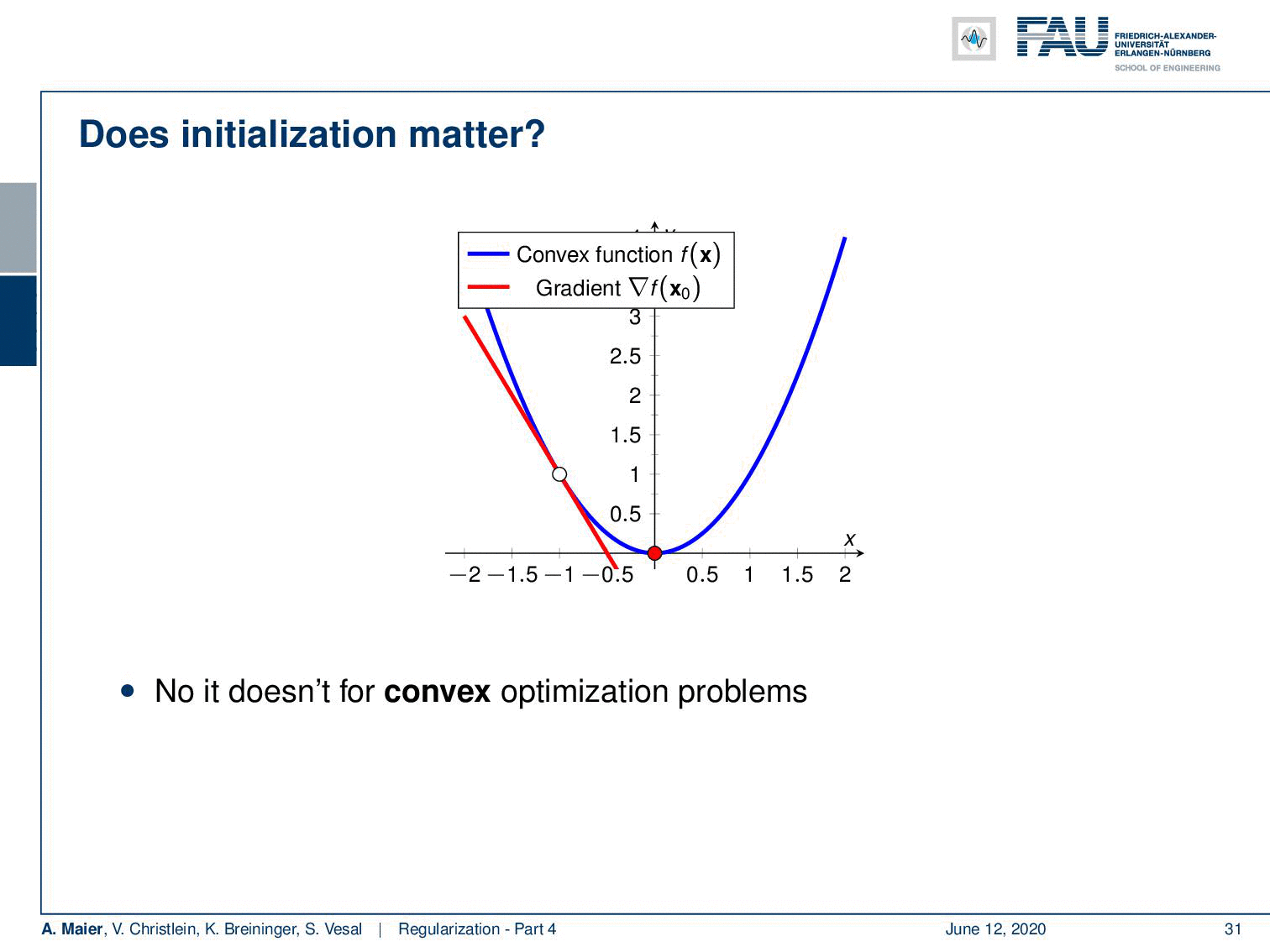
In convex problems, initialisation does not play a role.
Welcome back to deep learning! So today, we want to look at a couple of initialization techniques that will come in really handy throughout your work with deep learning networks. So, you may wonder why does initialization matter if you have a convex function, actually, it doesn’t matter at all because you follow the negative gradient direction and you will always find the global minimum. So, no problem for convex optimization.

Initialization can make a big difference in non-convex problems.
However, many of the problems that we are dealing with are non-convex. A non-convex function may have different local minima. If I start at this point you can see that I achieve one local minimum by the optimization. But if I were to start at this point, you can see that I would end up with a very different local minimum. So for non-convex problems, initialization is actually a big deal. Neural networks with non-linearities are in general non-convex.

Simple ideas for initialization.
So, what can be done? Well, of course, you have to work with some initialization. For the biases, you can start quite easily and initialize them to 0. This is very typical. Keep in mind that if you’re working with a ReLU, you may want to start with a small positive constant, This is better because of the dying ReLU issue. For the weights, you need to be random to break the symmetry. We already had this problem. In dropout, we saw that we need additional regularization in order to break the symmetry. Also, it would be especially bad to initialize them with zeros because then the gradient is zero. So, this is something that you don’t want to do. Similar to the learning rate, their variance influences the stability of the learning process. Small uniform gaussian values work.

How can the variances be calibrated?
Now, you may wonder how can we calibrate those variances. Let’s suppose we have a single linear neuron with weights W and input X. Remember that the capital letters here mark them as random variables. Then, you can see that the output is W times X. So, this is this linear combination of the respective inputs plus some bias. Now, we are interested in the variance of Y hat. If we assume that W and X are independent, then the variance of every product can be actually computed as the expected value of X to the power of 2 times the variance of W plus the expected value of W to the power of 2 times the variance of X and then you add the variances of the two random variables. Now if we require W and X to have 0 mean, then this would simplify the whole issue. The means would be 0, so the expected values cancel out and our variance would simply be the multiplication of the two variances. Now, we assume that X subscript n and W subscript n are independent and identically distributed. In this special case, we can then see that essentially the N here scaled our variances. So, it’s actually dependent on the number of inputs that you have towards your layer. This is a scaling of the variance with your W subscript n. So, you see that the weights are very important. Effectively, the more weights you have, the more it scales the variance.
#machine-learning #data-science #fau-lecture-notes #deep learning