In this post, we are going to discuss the workings of Decision Tree classifier conceptually so that it can later be applied to a real world dataset.
Classification can be defined as the task of learning a target function **f**that maps each attribute set **x**to one of the predefined labels y.
Examples:
- Assigning a piece of news to one of the predefined categories.
- Detecting spam email messages based upon the message header and content
- Categorising cells as malignant or benign based upon the results of MRI scans
- Classifying galaxies based upon their shape
Decision Tree can be a powerful tool in your arsenal as Data Scientist or a Machine Learning Engineer when working with real world datasets. Decision Trees are also used in tandem when you are building a Random Forest classifier which is a culmination of multiple Decision Trees working together to classify a record based on majority vote.
A Decision Tree is constructed by asking a serious of questions with respect to a record of the dataset we have got. Each time an answer is received, a follow-up question is asked until a conclusion about the class label of the record. The series of questions and their possible answers can be organised in the form of a decision tree, which is a hierarchical structure consisting of nodes and directed edges. A tree has three types of nodes:
- root node that has no incoming edges and zero or more outgoing edges.
- Internal nodes, each of which has exactly one incoming edge and two or more outgoing edges.
- Leaf or terminal nodes, each of which has exactly one incoming edge and no outgoing edges.
In a decision tree, each leaf node is assigned a class label. The non-terminal nodes, which include the root and other internal nodes, contain attribute test conditions to separate records that have different characteristics.
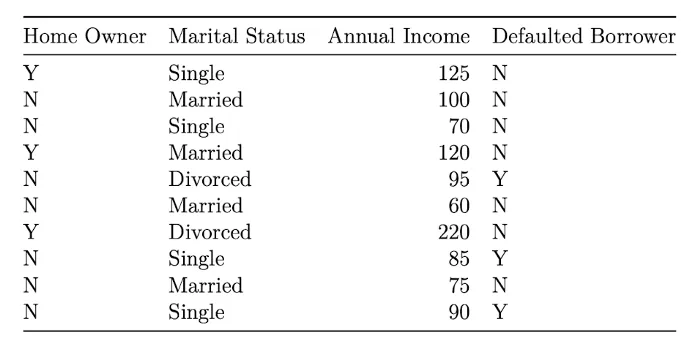
Let us construct a Decision Tree intuitively given a dataset before diving into the mathematics of it.
#computer-science #towards-data-science #classification #data-science #machine-learning