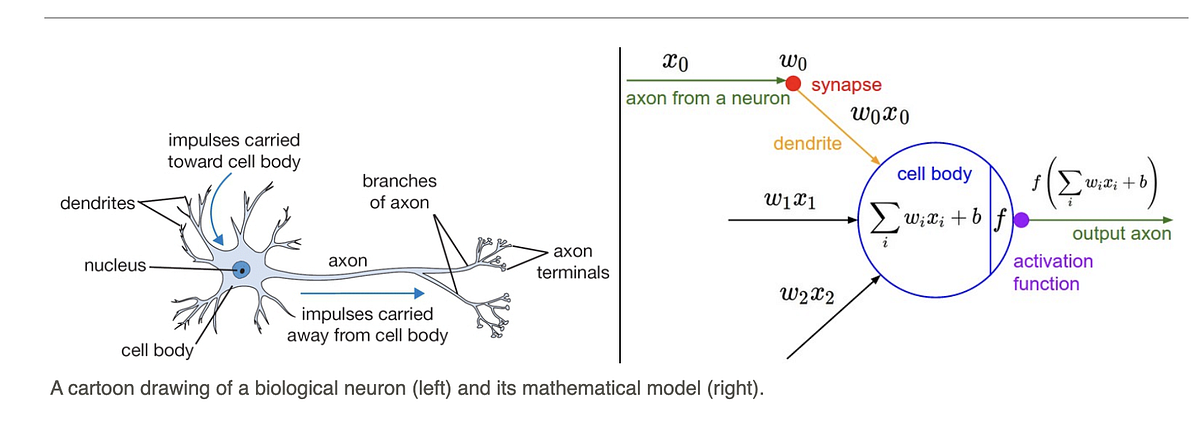
What are Activation Functions?
Activation functions in neural networks are used to define the output of the neuron given the set of inputs. These are applied to the weighted sum of the inputs and transform them into output depending on the type of activation used.
Output of neuron = Activation(weighted sum of inputs + bias)
Why we need Activation Functions?
The main idea behind using activation functions is to add non-linearity.
Now, the question arises why we need non-linearity? We need neural network models to **learn and represent complex functions. **Thus, using activation functions in neural networks, aids in process of learning complex patterns from data and adds the capability to generate non-linear mappings from inputs to outputs.
Types of Activation Functions
- Sigmoid- It limits the input value between 0 and 1.
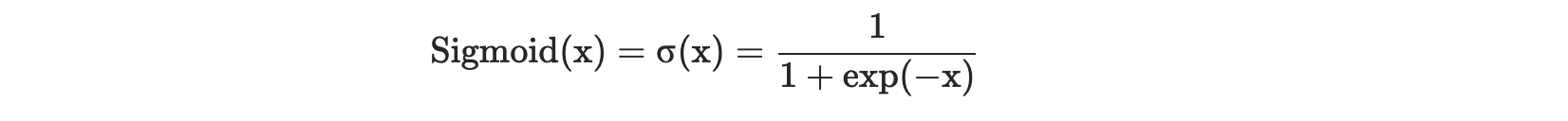
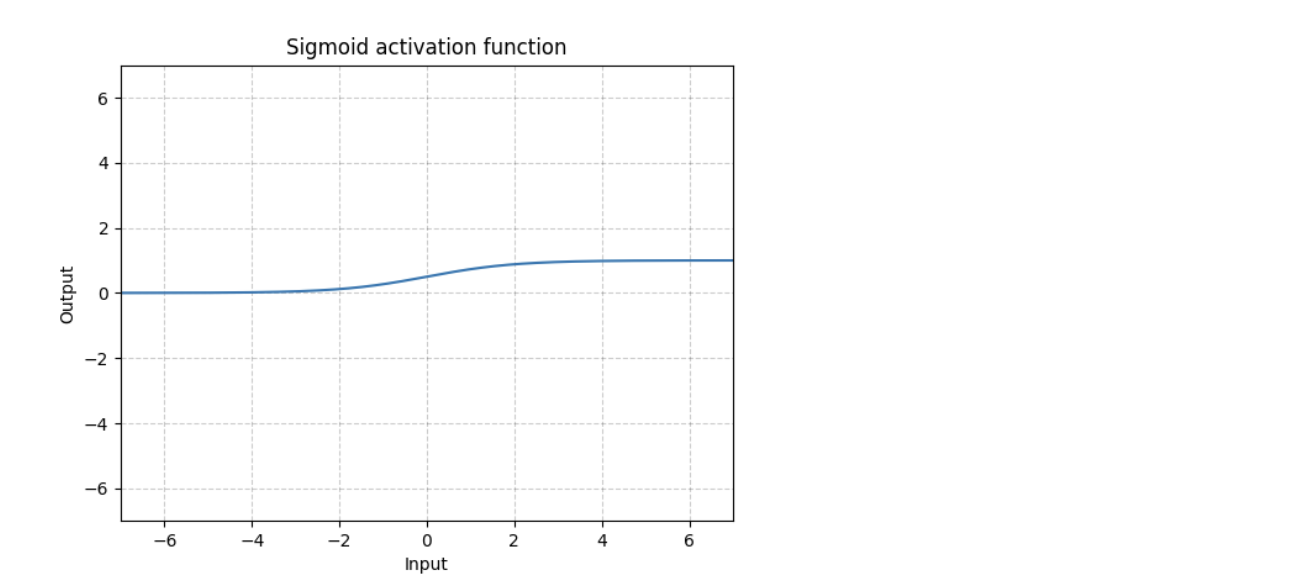
Sigmoid maps the input to a small range of [0, 1]. As a result, there are large regions of the input space which are mapped to a very small range. This leads to a problem called vanishing gradient. It means that the most upstream layers will learn very slowly because essentially the computed gradient is very small due to the way the gradients are chained together.
2. Tanh- It limits the value between -1 and 1.
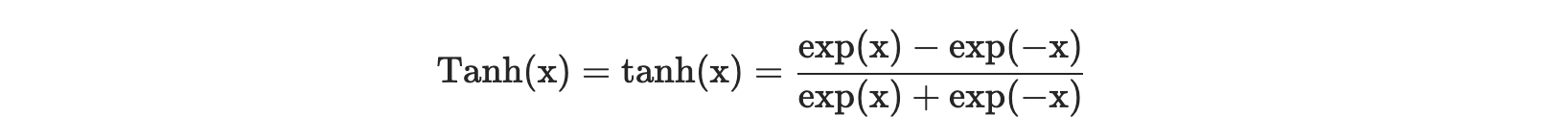
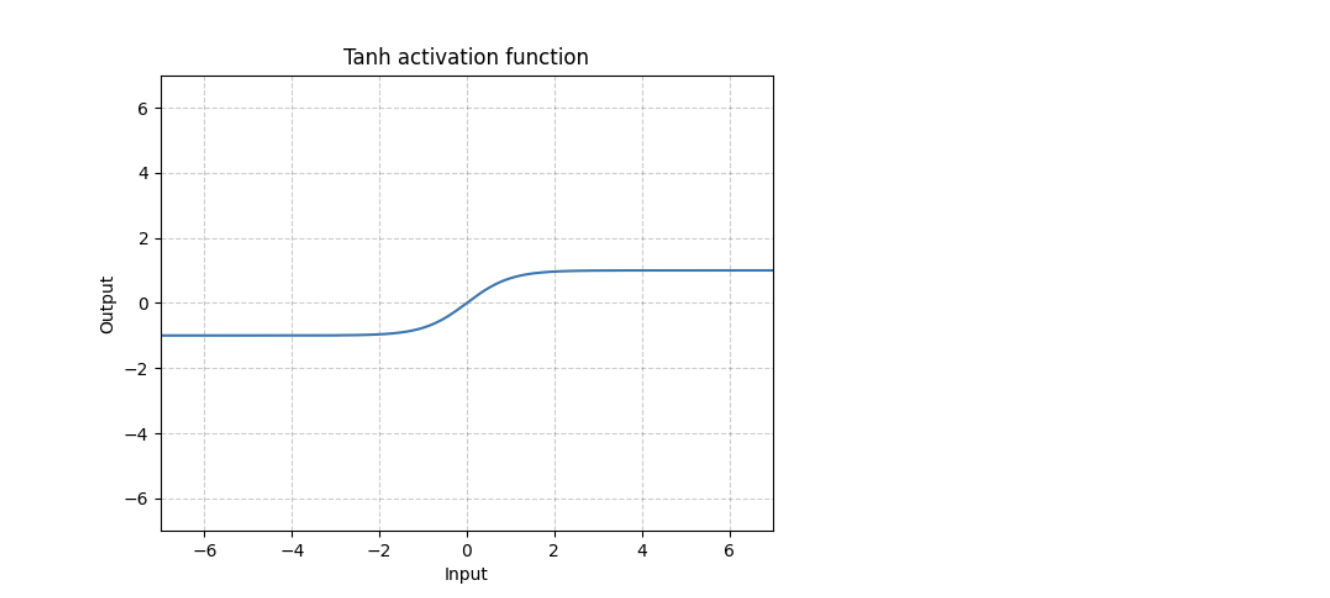
**Difference between tanh and sigmoid **— Apart from the difference in the range of these activation functions, tanh function is symmetric around the origin, whereas the sigmoid function is not.
Both sigmoid and tanh pose vanishing gradient problems when used as activation functions in neural networks.
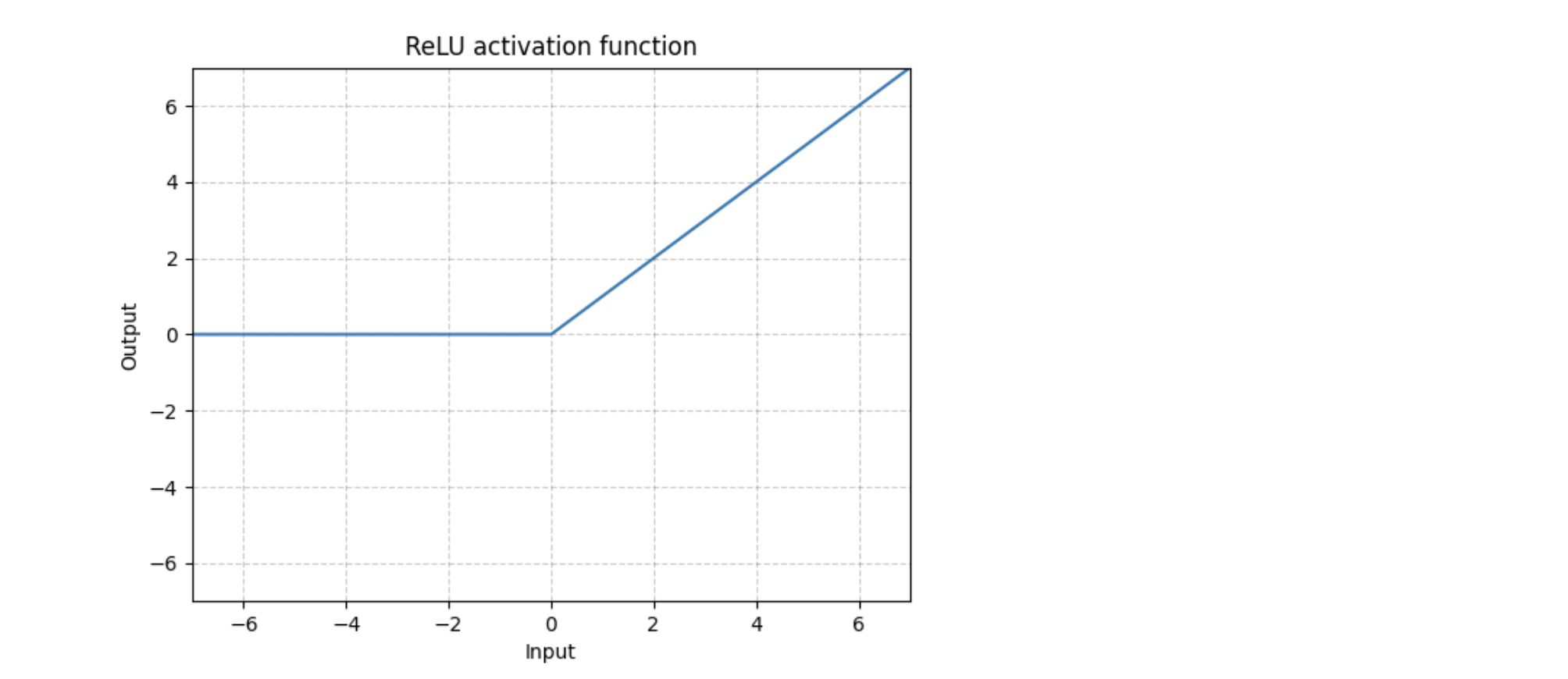
**3. ReLU(Rectified Linear Unit)- **It is the most popular activation function.
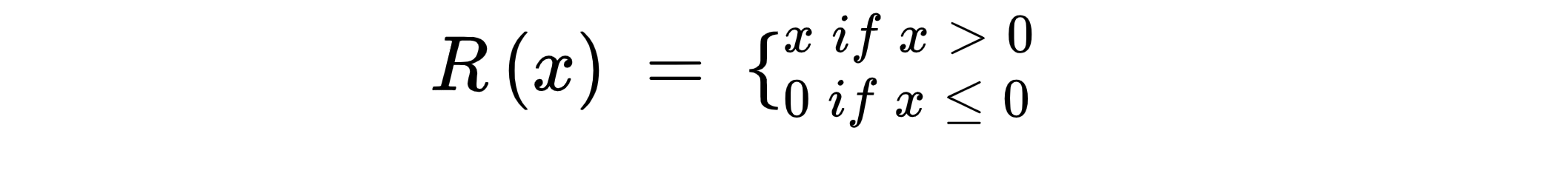
- Outputs the same value for a positive value and zeroes out negative values.
- It is very fast to compute (given the simplicity of logic), thus improving training time.
- ReLU does not pose vanishing gradient problem.
- It does not have a maximum value.
There are different variations of ReLU that are available like LeakyReLU, SELU, ELU, SReLU. Still, ReLU is widely used as it is simple, fast, and efficient
#neural-networks #activation-functions #deep-learning #convolutional-network #relu