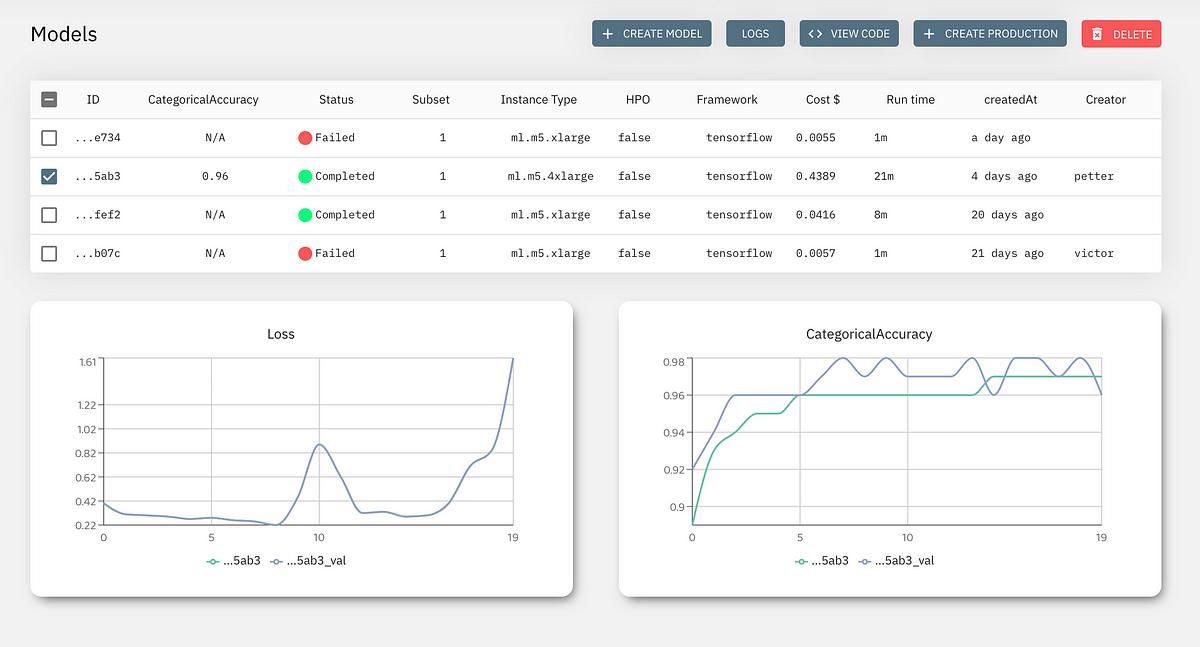
Introduction
Backing inventors on Kickstarter has for me, in 99 % of the cases, lead to years of waiting for a product that just never shows up at my doorstep. So, let’s once and for all remedy this with an amazing kickstarter success classifier. We will use the MLOps platform to our ingest our datasource (you can find it here on Kaggle), then develop our preprocessing and model scripts locally using the SDK, to finally submit the whole package to our AWS account to get it versioned and ready for production. After all, this could be a real money maker.
Preprocessing with PySpark
Some might argue that using Spark for a 50 MB dataset might be a bit overkill. But I like consistency and improvement. After all, it works just as good for MB as TB.
Let’s start with defining our main function:
if __name__ == "__main__":
mlops = SparkProcessor()
df_1 = mlops.read(database_name='mlops',
table_name='datasource_b67e6bff-e909-4113-a450-5c98dfa1be44_ks_projects_201801_csv')
result_df = my_transformations(df_1)
label_cols = result_df.schema.names[-2:]
mlops.write(
result_df,
label_columns=label_cols,
coalesce=False,
output_format="parquet"
)
As usual, I generate the script template using the MLOps platform, reading the datasource from S3. The MLOps SDK gives me a nice wrapper for all the things we don’t want to think about — like reading, writing and version controlling the transformations, so that I can focus on what happens in my_transformations .
#data-science #machine-learning #devops #ai #project-management