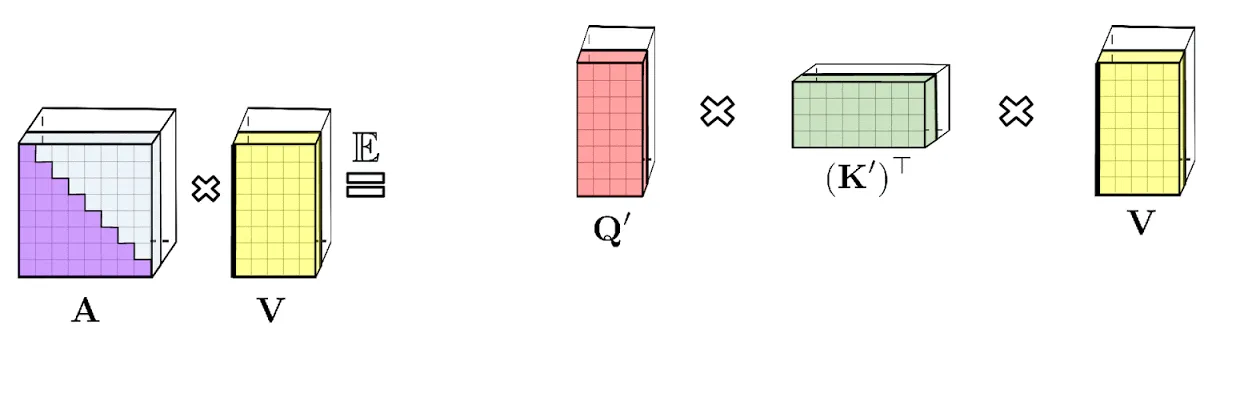
The key component of the transformer architecture is the attention module. Its job is to figure out the matching pairs (think: Translation) in a sequence through similarity scores. When the length of a sequence increases, calculating similarity scores for all pairs gets inefficient. So, the researchers have come up with the sparse attention technique where it computes only a few pairs and cuts downtime and memory requirements.
According to Google researchers, sparse attention methods still suffer from a number of limitations:
- They require efficient sparse-matrix multiplication operations, which are not available on all accelerators.
- They do not provide rigorous theoretical guarantees for their representation power.
- Optimised primarily for Transformer models and generative pre-training.
- Difficult to use with other pre-trained models as they usually stack more attention layers to compensate for sparse representations, thus requiring retraining and significant energy consumption.
- Not sufficient to address the full range of problems to which regular attention methods are applied, such as Pointer Networks.
Along with these, there are also some operations that cannot be sparsified, such as the commonly used softmax operation, which normalises similarity scores in the attention mechanism and is used heavily in industry-scale recommender systems.
#developers corner #google ai #performers #self attention models #ai