Based on a real use-case, discover why you should always take care of maintenance activities when modeling an industrial process… and what to do in case you did not!
The Machine Learning Challenges:
Many Data Scientists do agree on the importance of data preparation before actually using machine learning algorithms. This challenge is usually depicted as the iceberg displayed on the left below.
The second challenge is probably to transfer a Proof of Concept (P.O.C.) to the real environment where data is collected live and predictions integrated into the existing digital infrastructure.
But, in my opinion, the greatest challenge of all is to create a solution that will last over time:
What is pleasant with industrial processes is that they usually do not change their behavior overnight as human consumers would do! (And if you need an example of strange behavior switch, just remember how irrational toilet paper shortages were when the first COVID lockdowns started and how hard it was for A.I. systems to cope with it!)
But even industrial machine learning models can drift apart as their robustness also relies on the 3 axioms of Data Science:

From Good… to Great… to Worse!
As for every modeling project, it took me a few weeks from the moment one operational team came to me with a use case to solve and the time when the quality predictions were displayed live on a dashboard within the control room with a pretty good level of accuracy.
However, after a few weeks, a sudden drift in the accuracy of the predictions made me question the robustness of the whole model and, by extension, the stability of the industrial process!
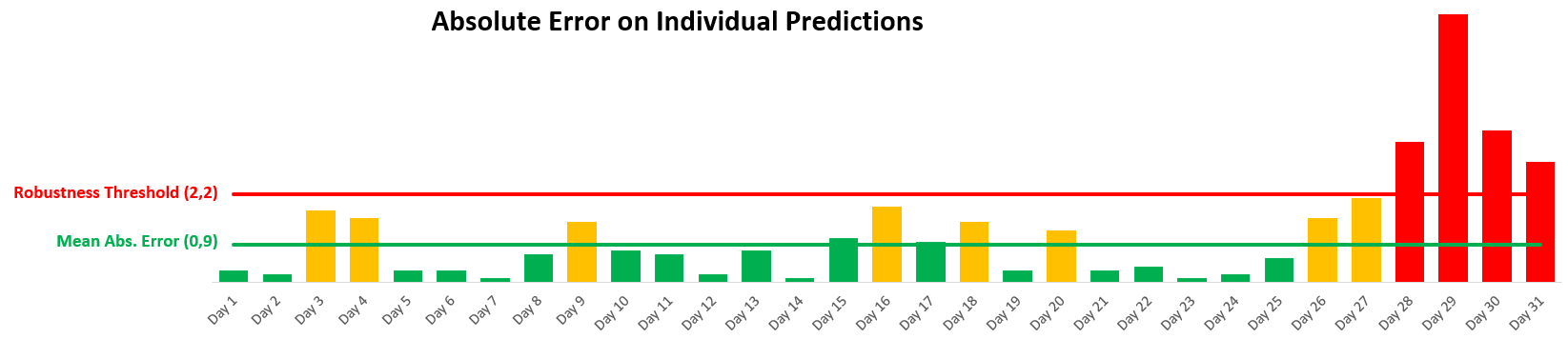
Predictions’ accuracy (MAE) over the last month
We see that the predictions of the last four days are beyond the robustness threshold we have defined with the team (2,2) and significantly above the Mean Absolute Error (M.A.E.) at 0,9.
#machine-learning #lessons-learned #data-science #maintenance #towards-data-science #deep learning