Does your company have a lot of Documents / PDF files that your employees have to check and enter into the database manually?
Yes! Then, you are on the right blog!
Introduction
Most businesses are now sitting on Document goldmines. These documents are contracts, PDFs, emails, customer feedback, patterns. These documents are increasing over time.
Following are some example of the business which has millions of contract documents. They need to read these documents at a different times of their lifecycle for analyzing it. This needs a lot of processing time and error prone.
- Mortgage Providers
- Insurance Companies
- School
These are unstructured data.
Document AI
Document AI, in beta, offers a scalable, serverless platform to automatically classify, extract, and enrich data from your scanned documents. It converts unstructured data into structured data.
Internally it uses the same deep machine learning technology that powers Google Search, Google Assistant, Natural Language Processing API to derive valuable insights from your unstructured documents.

Use Case
The organisation has multiple field offices and the head office runs the HR / Payroll system. New joiner’s details are filled in a form by field managers and then forms are being sent to head office. The operator enters the details manually to the system and then Employee’s email, training, access card, laptop, and other formalities get sorted.
This end-2-end process takes days and till then employee sits idle. In my opinion new joiners (be it fresher or experienced) have always eager to demonstrate his/her talent or skill so they should not idle in their early days.
In this post, we will see how to automate document processing and end-to-end new joiner process:
- Field managers fill the form and upload the scanned form
- The application extracts the data from document and store into database
- Then alerts to other processes, new joiners employee_id
- Other processes like ID Cards, Laptop, Desk, etc will fetch the details from the database using employee_id
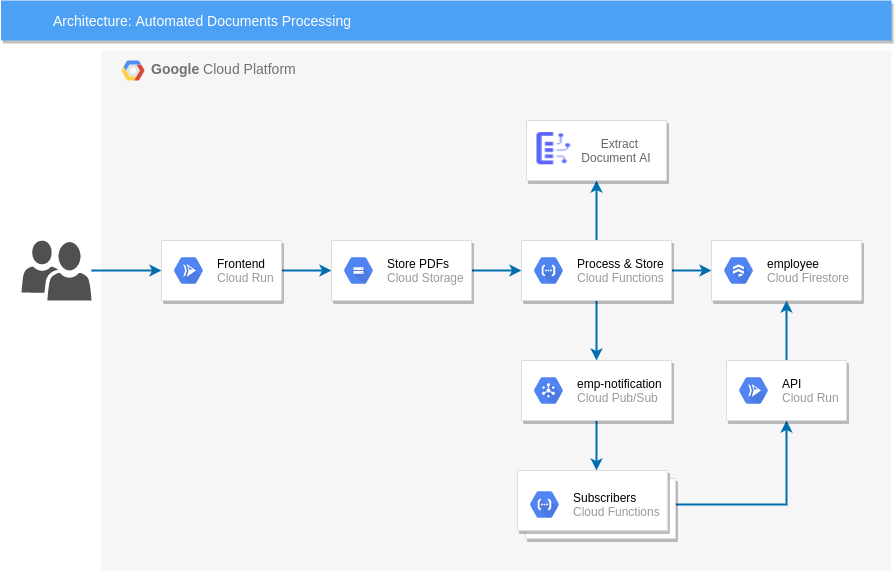
Architecture
Components
The following Serverless components are used in this architecture. This means that you will pay per use, without any up-front costs. Also, no servers need to be configured or maintained.
- Front-end app to upload the scanned document on Cloud Run.
- The document is stored in Google Cloud Storage.
- This triggers the Cloud Function.
- The Cloud Function calls Document AI to fetch the entities.
- The Cloud Function reads the response generates employee_id, email, and stores data to Cloud Firestore.
- The new-joiner notification is sent to **Cloud Pub/Sub **topic.
- This topic has multiple subscribers: Desk Service, Laptop Service, ID Card Service. These services will fetch the details from Firestore.
- The Service deployed using Cloud Run which has end-point to GET the details of an employee from Cloud Firestore.
- All components are logging data to Stackdriver.
Deploy this Document AI app using Terraform
Setup
In order to complete this guide, you’ll need to install the following tools
- Terraform: This guide uses Terraform to deploy resources.
- Git: Git is used to clone the example code and trigger new deployments.
- GCP: You will need a GCP account with billing enabled.
Create GCP Project
Create a GCP project for this tutorial.
Select Firestore mode
- Go to Firestore
- Select Native Mode
- Select a Location (e.g. United States)
- Click on “Create Database”
Create Service Account
- Create Service Account.
- Assign the roles: Editor
- Download the key and renamed it as terraform-key.json
Clone the Repository
#ai #terraform #google-cloud-platform #serverless #devops