In my last blog, I wrote about how we can use dpdk pktgen for performance testing. Today I spent some time on some baseline testing to see what we can expect out of a vanilla Linux system nowadays when used as a router. Over the last two years I’ve been playing a fair bit with kernel bypass networking and hope to write about it in the near future. The promise of kernel bypass networking is higher performance, to determine how much of performance increase over the Kernel we need to establish a baseline first, we’ll do that in this article.
Test setup
n2.large.x86 CPU specs.
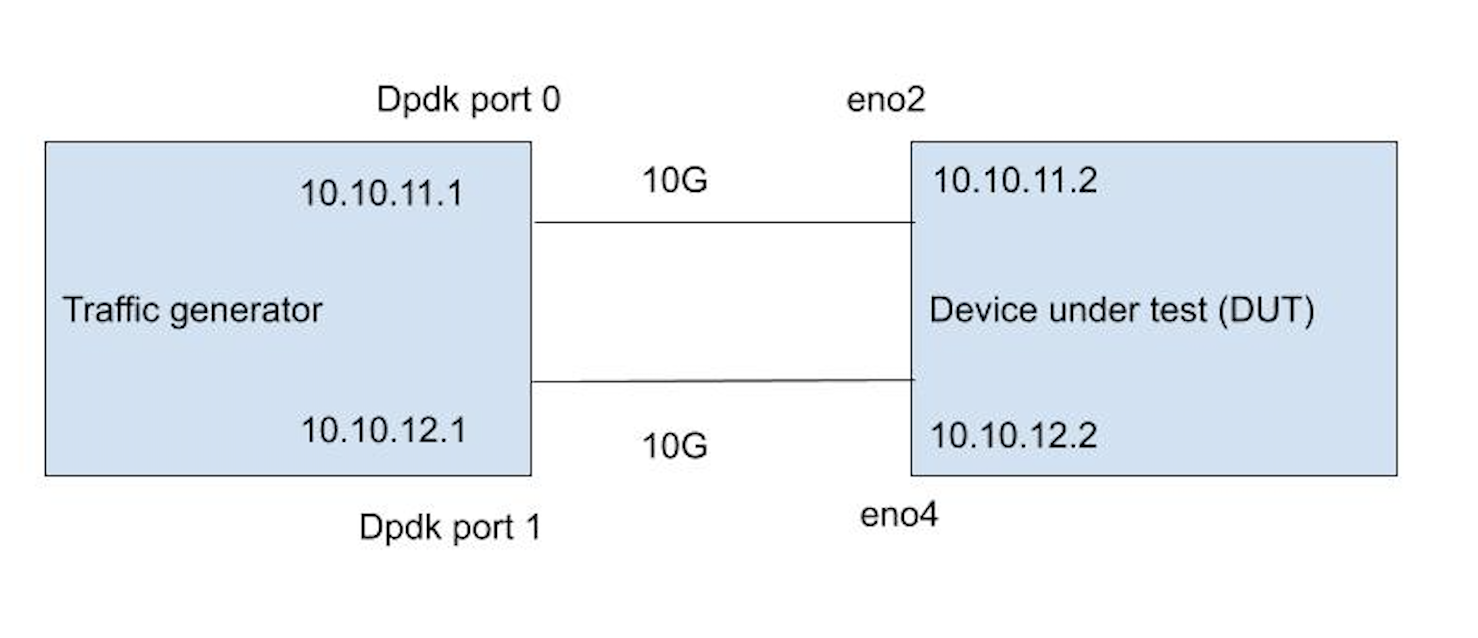
I’m using two n2.xlarge.x86 servers from packet.com. With its two Numa nodes, 16cores per socket, 32 cores in total, 64 with hyper-threading, this is a very beefy machine! It also comes with a quad-port Intel x710 NIC, giving us 4 x 10Gbs. Packet allows you to create custom vlans and assign network ports to a vlan. I’ve created two vlans and assigned one NIC to each vlan. The setup looks like below.
Test setup
The Device Under Test (DUT), is a vanilla Ubuntu 19.04 system running a 5.0.0–38-generic kernel. The only minor tune I’ve done is to set the NIC rx ring to 4096. And I enabled ip forwarding ( net.ipv4.ip_forward=1)
Using the traffic generator, I’m sending as many packets possible and observe when packets stop coming back at the same rate, which indicates packet-loss. I record the point that happens as the maximum throughput. I’m also keeping a close eye on the CPU usage, to get a sense of how many CPU cores (hyper threads) are needed to serve the traffic.
Test 1 — packet forwarding on Linux
The first test was easy. I’m simply sending packets from 10.10.11.1 to 10.10.12.1 and vice versa, through the DUT (Device under Test), which is routing the packets between the two interfaces eno2 and eno4.
Note that that I did both a one directional test (10.10.11.1 > 10.10.12.1) and a bidirectional test (10.10.11.1 > 10.10.12.1 AND 10.10.12.1 > 10.10.11.1).
I also tested with just one flow, and with 10,000 flows.
Receive Side Scaling (RSS)
This is important as the NIC is doing something called Receive Side Scaling (RSS), which will load balance different flows on to different NIC receive Queues. Each queue is then served by a different core, meaning the system scales horizontally. But, keep in mind, you may still be limited by what a single core can do depending on your traffic patterns.
Ok, show me the results! Keep in mind that we’re talking mostly about Packets Per Second (PPS) as that is the major indicator of the performance, it’s not super relevant how much data is caried in each packet. In the world of Linux networking, it really comes down to, how many interrrupts per second the system can process.
Test results for test 1
In the results above, you can see that one flow can go as high as 1.4Mpps. At that point, the core serving that queue is maxed out (running 100%), and can not process any more packets and will start dropping. The single flow forwarding performance is good to know for DDOS use-cases or large single flow network streams such as ESP. For services like these, the performance is as good as a single queue / cpu can handle.
When doing the same test with 10,000 flows, I get to 14 Mpps, full 10g line rate at the smallest possible packet size (64B), yay! At this point I can see all cores doing a fair amount of work. This is expected and is due to the hashing of flows over different queues. Looking at the CPU usage, I estimate that you’d need roughly 16 cores at 100% usage to serve this amount of packets (interrupts).
14M pps, unidirectional test.
Interestingly, I wasn’t able to get to full line rate when doing the bidirectional test. Meaning both NICs both sending and receiving simultaneously. Although I am getting reasonably close at 12Mpps (24Mpps total per NIC). When eyeballing the cpu usage and amount of idle left over, I’d expect you’d need roughly 26 cores at 100% usage to do that.
#network #devops #iptables #networking #xdp