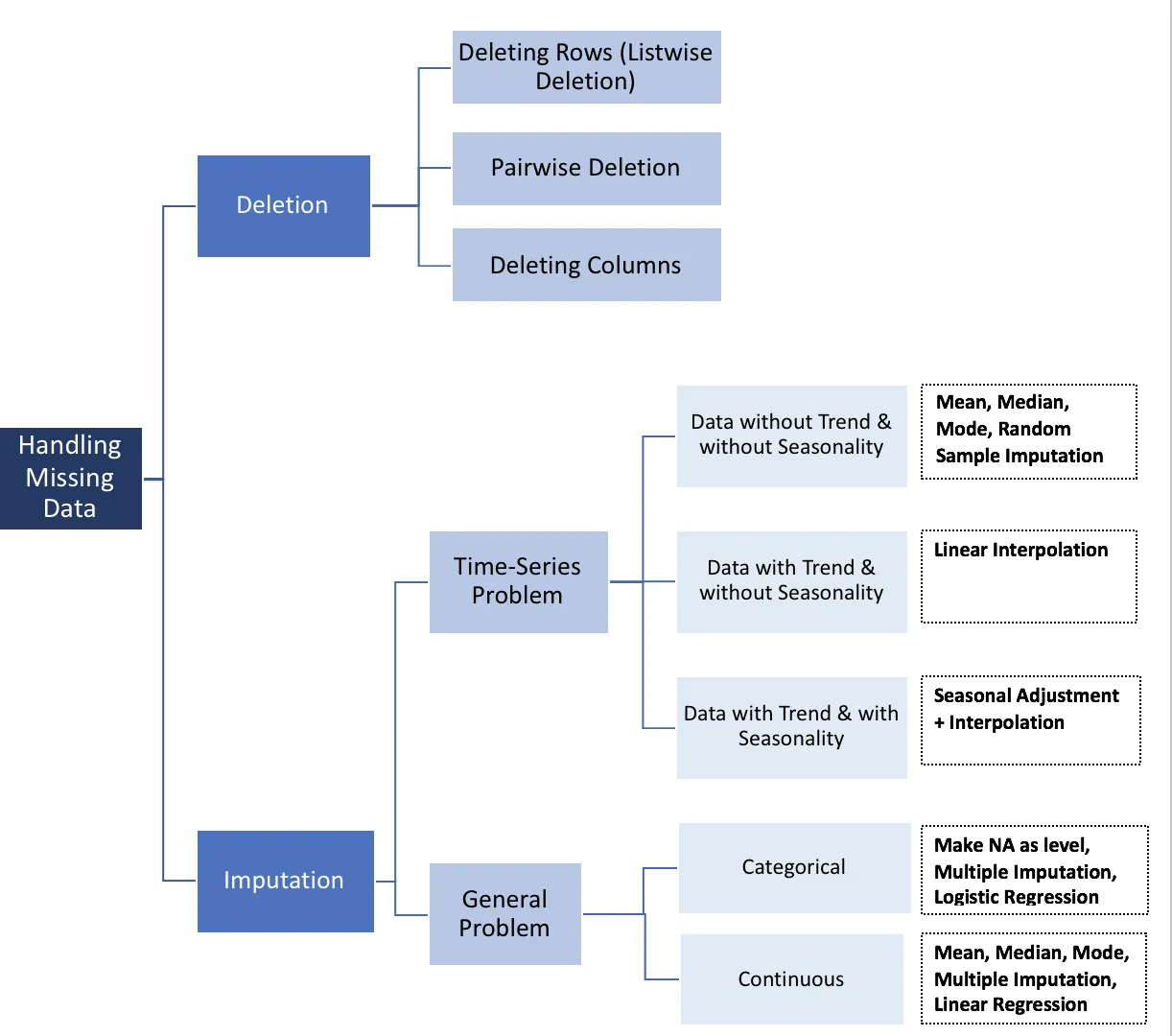
The biggest challenge for data scientists is probably something that sounds mundane, but very important for any analyses — cleaning dirty data. When you think of dirty data, you are probably thinking about inaccurate or malformed data. But the truth is, missing data is actually the most common occurrence of dirty data. Imagine trying to do a customer segmentation analysis, but 50% of the data have no address on record. It would be hard or impossible to do your analysis since the analysis would be bias in showing no customers in certain areas.
Explore Missing Data
- **How much data is missing? **You can run a simple exploratory analysis to look at the frequency of your missing data. If it’s a small percentage, let’s say 5% or less, and the data is missing completely at random, you could consider ignore and delete those cases. But keep in mind that it’s always better to analyze all data if possible, and dropping data can introduce biases. Therefore, it’s always better to check the distribution to see where the missing data are coming from.**Analyze how the data is missing **(MCAR, MAR, MNAR). We will discover different types of missing data in the next section.
Types of missing data
There are three kinds of missing data:
- data missing completely at random (MCAR)data missing at random (MAR)data missing not at random (MNAR)
In this article, I’ll go over the types of missing data with examples, and share how to handle missing data with imputation.
#technology #statistics #data-science #missing-data #women-in-tech