Serverless is relatively straightforward to get started with but becomes more complicated as functions leverage more advanced resources.
Serverless computing enables developers to assemble programmatic functions into services efficiently, flexibility, cost-effectively, and with easy scalability. But to really get the most benefit from a shift to serverless, it really helps to understand what’s going on under the hood. In this article, I’ll use the AWS Lambda service as a basis for explaining how serverless functions actually work and then how best to use them. I’ll also cover a number of available resources you can use to build out powerful services with serverless. Just don’t forget security.
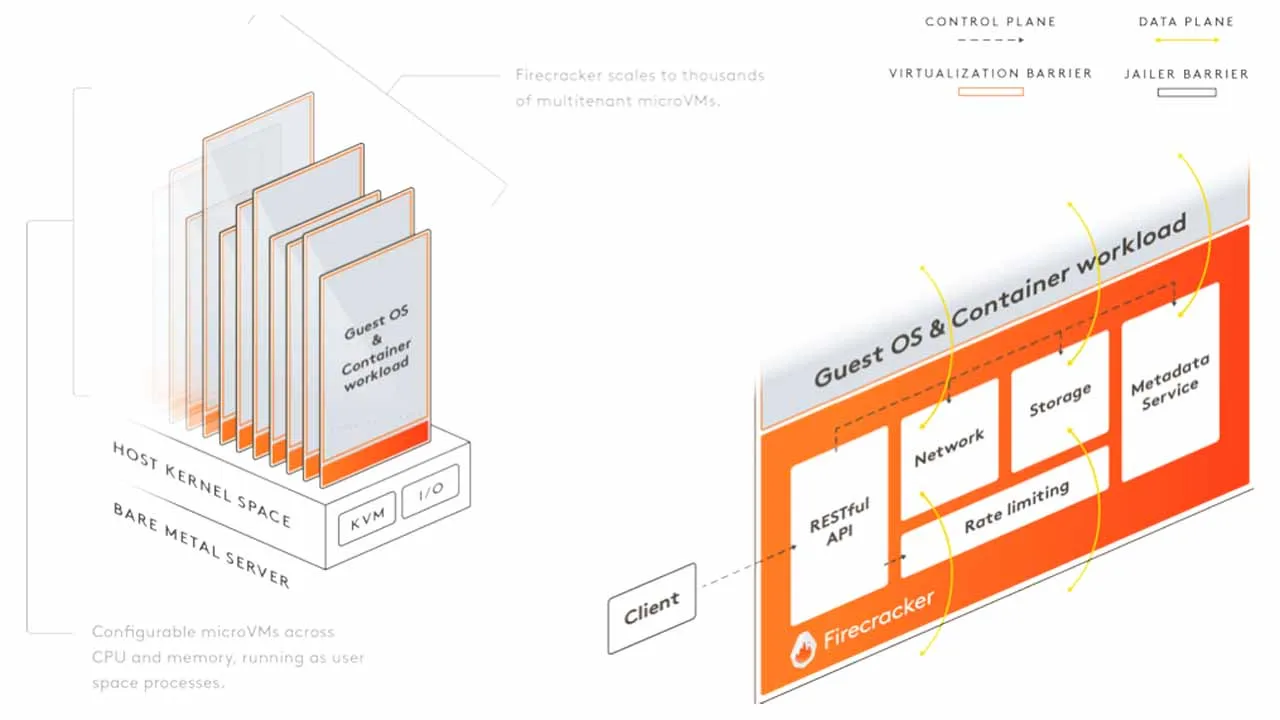
First, let’s demystify the name: serverless functions do, in fact, run on servers. However, serverless costs are based purely on consumption, and users are spared from considering server-based resource terms such as server size or bandwidth. The machine that runs serverless functions is a highly customized micro VM, which builds a minimal runtime that’s designed exclusively for the function’s specified programming language.
This diagram shows that Firecracker is a KVM-based VM, like other hypervisor systems. Firecracker stores functions in the /var/runtime/bin folder and waits until the function is called.
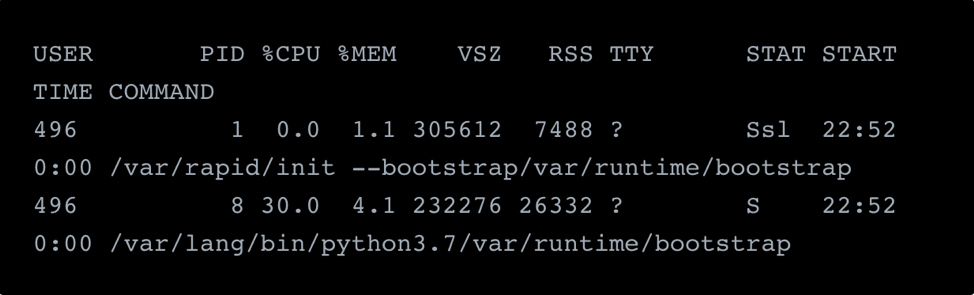
To understand how the function runs, let’s look at the process for running an example Python function in the microVM:
#serverless #aws lambda #firecracker