ML implementations tend to get complicated quickly. This article will explain how ML system can be split into as few services as possible.
Introduction
After implementing several ML systems and running them in production, I realized there is a significant maintenance overload for monolithic ML apps. ML app code complexity grows exponentially. Data processing and preparation, model training, model serving — these things could look straightforward, but they are not, especially after moving to production.
Data structures are changing, this requires adjusting data processing code. New data types are appearing, this requires maintaining the model up to date and re-train it. These changes could lead to model serving updates. When all this runs as a monolith, it becomes so hard to fix one thing, without breaking something else.
Performance is another important point. When the system is split into different services, it becomes possible to run these services on different hardware. For example, we could run training services on TensorFlow Cloud with GPU, while data processing service could run on local CPU VM.
I did research and checked what options are available to implement ML microservices. There are various solutions, but most of them looked over complicated to me. I decided to implement my own open-source product, which would rely on Python, FastAPI, RabbitMQ, and Celery for communication between services. I called it Skipper, it is on GitHub. The product is under active development, nevertheless, it can be used already.
The core idea of Skipper is to provide a simple and reliable workflow for ML microservices implementation, with Web API interface in the front. In the next phases, services will be wrapped into Docker containers. We will provide support to run services on top of Kubernetes.
Solution Architecture
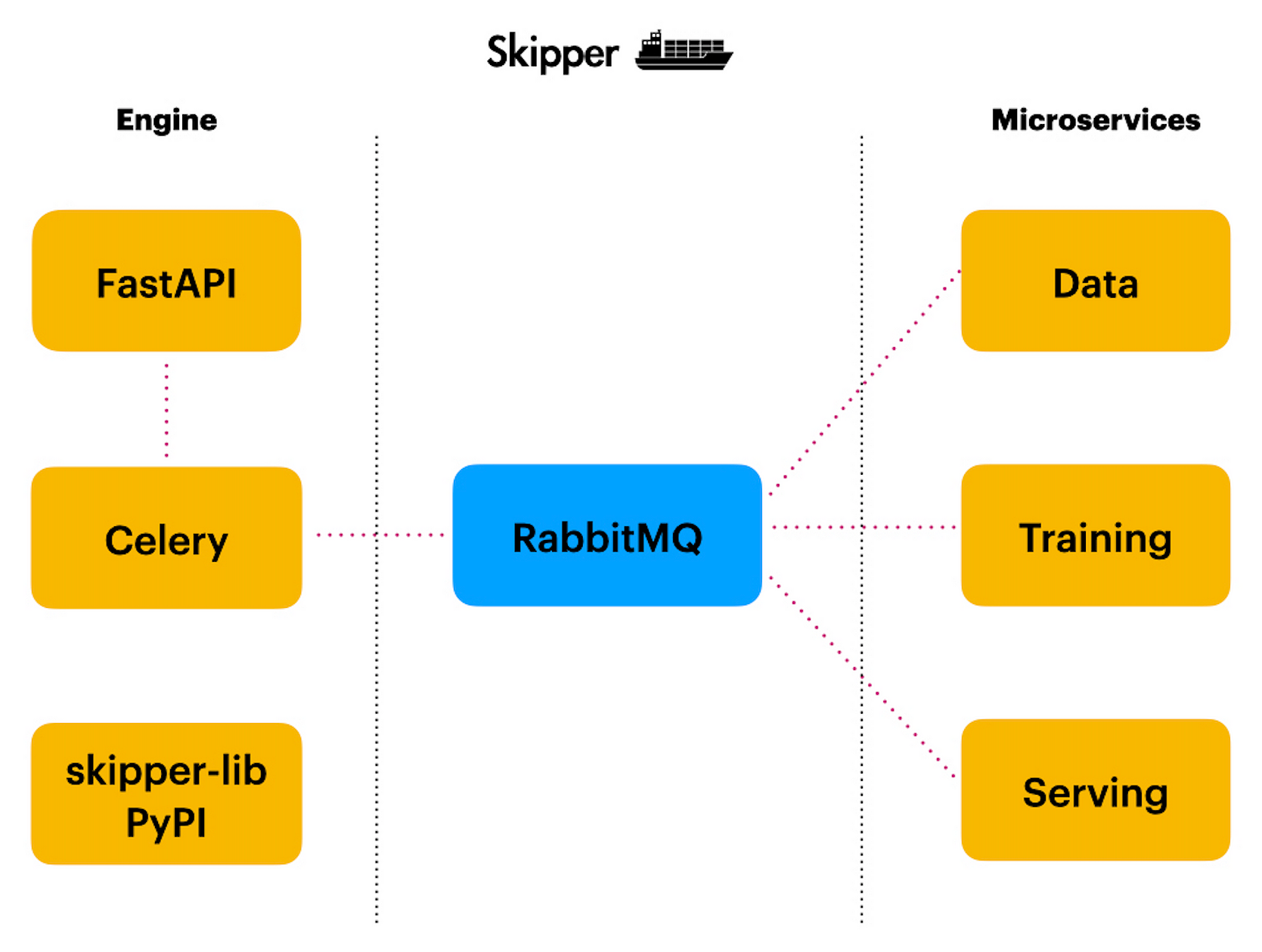
Skipper architecture, author: Andrej Baranovskij
There are two main blocks — engine and microservices. The engine can be treated as a microservice on its own, but I don’t call it a microservice for a reason. The engine part is responsible to provide Web API access, which is called from the outside. It acts as a gateway to a group of microservices. Web API is implemented with FastAPI.
Celery is used to handle long-running tasks submitted through Web API. We start a long-running async task with Celery, the result is retrieved through another endpoint, using task ID.
#python #rabbitmq #pipeline #microservices
