A few days ago, OpenAI announced a new successor to their Language Model (LM) — GPT-3. This is the largest model trained so far, with 175 billion parameters. While training this large model has its merits, reading a large portion of 72 pages can be tiresome. In this blog post I’ll highlight the parts that I find interesting for people familiar with LMs, who merely wish to know (most of) the important points of this work.
What’s in a Language Model?
“The diversity of tasks the model is able to perform in a zero-shot setting suggests that high-capacity models trained to maximize the likelihood of a sufficiently varied text corpus begin to learn how to perform a surprising amount of tasks without the need for explicit supervision”
This is an excerpt from the paper accompanying GPT-2. GPT-3 is taking another step in this avenue.
More specifically, the authors pinpoint the drawbacks of fine-tuning using task specific datasets.
- Getting these datasets is difficult.
- Fine-tuning allows the model to exploit spurious correlations, which lead to bad out-of-distribution performance.
- A brief directive in natural language is usually enough for humans to understand a given task. This adaptability is a desired property of NLP systems.
The route the authors chose to take is “in-context learning” — feeding the model a task specification (prompt) and/or a few demonstrations of the task as a prefix, priming it towards a subspace in the latent space that adheres to the given task. Translation, for instance, would look like “Q: What is the {language} translation of {sentence} A: {translation}”.
This is based on the assumption that the model develops a broad set of skills and pattern recognition abilities at training time, and then uses those abilities at inference time to rapidly adapt to or recognize the desired task.
It’s a common wisdom that low perplexity is correlated with performance on downstream tasks, so one can hope that bigger models will yield better in-context capabilities. And indeed, this holds true, as can be seen in the next figure, where a simple task requiring the model to remove random symbols from a word is tested:
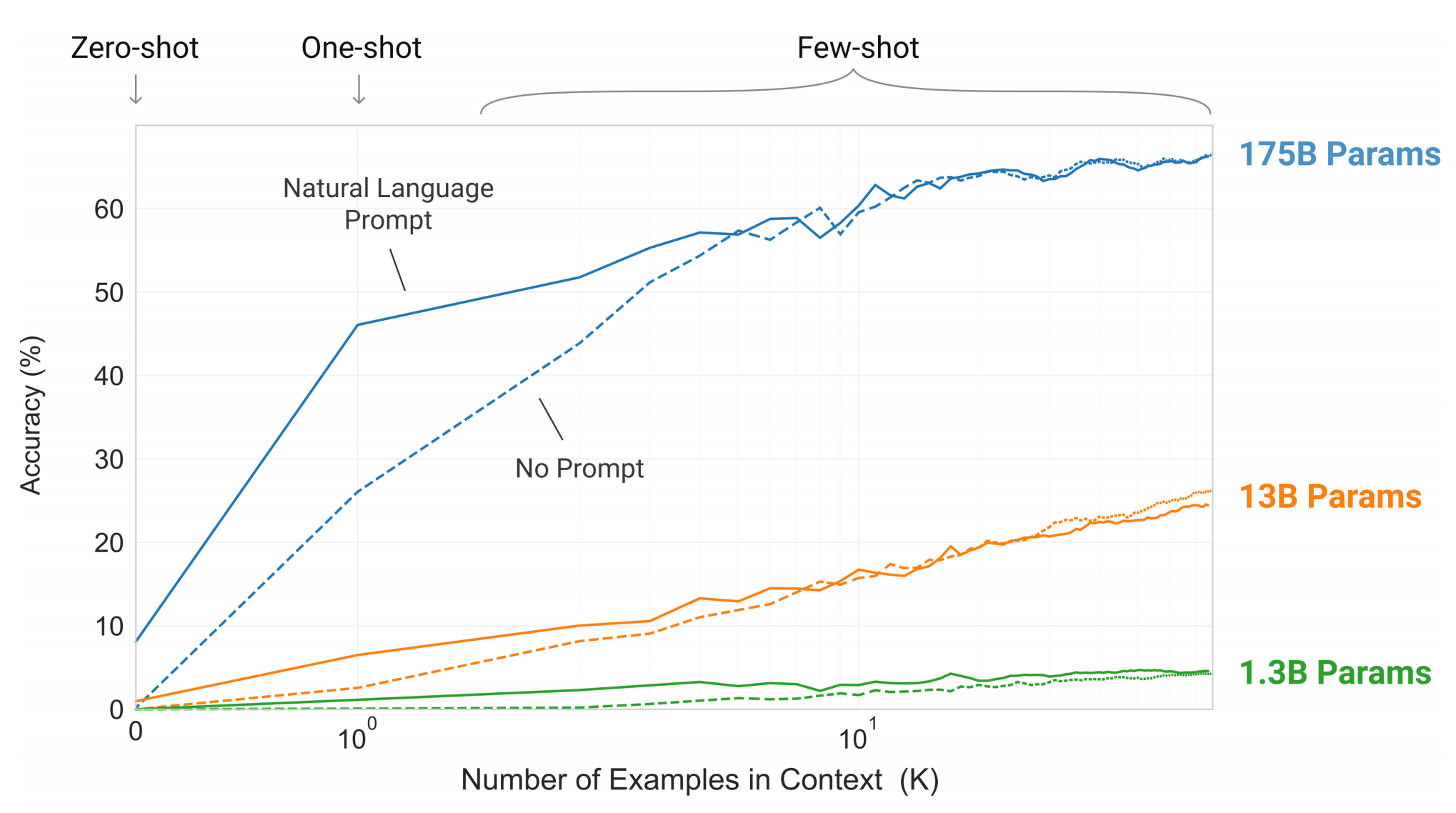
Larger models make increasingly efficient use of in-context information.
The number of in-context examples varies between 10 to 100, since this is typically what’s permitted with the model’s context size of 2048. Prompt (task specification) plays a significant role when the number of examples is low.
The authors tested many well known benchmarks, but first — let’s inspect the model specification.
Heavy Weight Lifting
GPT-3 is made up of a Transformers-based architecture similarly to GPT-2, including the modified initialization, pre-normalization, and reversible tokenization described therein, with the exception that it uses alternating dense and locally banded sparse attention patterns in the layers of the transformer, similar to the Sparse Transformer.
The authors trained several model sizes, varying from 125 million parameters to 175 billion parameters, in order to measure correlation between model size and benchmark performance.
#machine-learning #nlp #artificial-intelligence #neural-networks #deep-learning #deep learning
