Collections in Python
This article is intended to help Java programmers who, on their path to machine-learning glory, must first ease into Python.
We’ll only cover the very basic collection types and their operations. References include more comprehensive tutorials and documentation.
Tuple and List
Tuple
A tuple is an immutable, heterogeneous, sequence of values. This is a very useful data structure that does not exist in Java.
>>> a_tuple = ((1,2,3,4), 'is a', 'sequence of', 4, 'numbers')
A tuple is heterogenous as it can hold items of any type: primitives, objects, other tuples, arrays, and so on. It is a sequence because it is indexable and iterable.
>>> a_tuple[1]
'is a'
>>> for item in a_tuple:
... print(item)
...
(1, 2, 3, 4)
is a
sequence of
4
numbers
Items cannot be modified in, added to, or removed from a tuple. However, tuples can be sliced and concatenated to form new tuples.
>>> a_tuple[0]=(2,3,4,5)
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
TypeError: 'tuple' object does not support item assignment
>>> another_tuple = ((2,3,4,5), 'is also a') + a_tuple[2:]
>>> print(another_tuple)
((2, 3, 4, 5), 'is also a', 'sequence of', 4, 'numbers')
The most common usage of tuples is to return multiple values from a function.
>>> def stats(list_of_ints):
... total = sum(list_of_ints)
... count = len(list_of_ints)
... average = total / count
... return (total, count , average)
...
>>> (total, count, average) = stats(a_tuple[0])
>>> print(total, count, average)
10 4 2.5
List
A list is also a heterogenous but mutable sequence of values. Values in a list can be indexed, iterated, and modified.
# convert tuple to list
>>> a_list=list(a_tuple)
>>> a_list[0]=list(a_list[0])
>>> a_list
[[1, 2, 3, 4], 'is a', 'sequence of', 4, 'numbers']
# append item to a list
>>> a_list[0].append(5)
#modify item in a list
>>> a_list[3]=5
>>> a_list
[[1, 2, 3, 4, 5], 'is a', 'sequence of', 5, 'numbers']
Even though lists can be heterogenous, in practice, they are used to store similar items. Now we see how some common list operations in Java (8) can be performed in Python.
// Java
List<Integer> numbers = Arrays.asList(1,2,3,4,5,6,7,8,9,10);
# Python
numbers = [1,2,3,4,5,6,7,8,9,10]
List Operations
Query/filter
// Java
List<Integer> odds = numbers
.stream()
.filter(num -> (num & 1) == 1)
.collect(Collectors.toList());
# Python
>>> def is_odd(number):
... return (number & 1) == 1
...
>>> odds = list(filter(is_odd, numbers))
>>> print(odds)
[1, 3, 5, 7, 9]
Test for membership
// Java
boolean isOddNumber = odds.contains(1);
// Python
>>> 1 in odds
True
Transform
// Java
List<Integer> squares = numbers
.stream()
.map(n -> n * n)
.collect(Collectors.toList());
# Python
>>> squares=list(map(lambda n: n*n, numbers))
>>> print(squares)
[1, 4, 9, 16, 25, 36, 49, 64, 81, 100]
Flatten
This involves the creation of a new list by extracting all items that are nested inside objects in an another list.
In Python, this requires the use of a built-in library (functools). There are other implementations as well.
// Java
List<List<Integer>> listOfLists = Arrays.asList(odds, evens);
List<Integer> flattened = listOfLists.stream()
.flatMap(list -> list.stream())
.collect(Collectors.toList());
# Python
>>> from functools import reduce
>>> list_of_lists=[odds, evens]
>>> flattened = reduce(list.__add__, list_of_lists)
>>> flattened
[1, 3, 5, 7, 9, 2, 4, 6, 8, 10]
Sort
// Sort based on modulo 3
// Java
flattened.sort(Comparator.comparing(n -> n % 3));
# Python
>>> numbers.sort(key=lambda n: n % 3)
>>> numbers
[3, 6, 9, 1, 4, 7, 10, 2, 5, 8]
Dictionary
Dictionary is a container for key-value pairs and is similar to the Map data structure in Java.
The main difference is that Java maps are strongly typed, whereas in Python, dictionary keys and values can be heterogeneous (but the keys still have to be unique).
Create a dictionary from a list
// Group a sequence of numbers using modulo by 3
// Java collect grouping by
Map<Integer, List<Integer>> map = numbers.stream()
.collect(Collectors.groupingBy(n -> n % 3));
System.out.println(map.get(0));
// [3, 6, 9]
# Python - list has to be sorted by group key first
>>> from itertools import groupby
>>> numbers = [1,2,3,4,5,6,7,8,9,10]
>>> dict={}
>>> keyfunc = lambda n : n % 3
>>> sorted_numbers = sorted(numbers, key=keyfunc)
>>> for k,g in groupby(sorted_numbers,keyfunc):
... dict[k]=list(g)
...
>>> dict[0]
[3, 6, 9]
Iterate using keys
// Java
Map<Integer, List<Integer>> map = numbers.stream()
.collect(Collectors.groupingBy(n -> n % 3));
map.entrySet().forEach(entry -> {
System.out.println(entry.getKey() + ":" + entry.getValue());
});
# Python
>>> for k, v in dict.items():
... print(k,':',v)
...
0 : [3, 6, 9]
1 : [1, 4, 7, 10]
2 : [2, 5, 8]
Having transitioned to a “Pythonic” state of mind, we can now lose our Java crutches and look at some advanced data structures and libraries widely used in machine learning.
Array
NumPy is a popular library for working with scientific and engineering data. Here, we highlight the array manipulation capabilities offered by NumPy.
A NumPy array is an N-dimensional grid of homogenous values. It can be used to store a single value (scalar), coordinates of a point in N-dimensional space (vector), a 2D matrix containing the linear transformations of a vector (matrix), or even N-dimensional matrices (not tensors though).
>>> import numpy as np
>>> a_vector = np.array([1, 2, 3])
>>> print('vector shape:', a_vector.shape)
vector shape: (3,)
>>> a_matrix = np.array([[1, 2, 3], [4, 5, 6], [7, 8, 9]])
>>> print('matrix shape:', a_matrix.shape)
matrix shape: (3, 3)
Now, let us look at some of the frequently used array operations.
Query/Filter/Mask
>>> numbers=np.array([1,2,3,4,5,6,7,8,9,10])
# mask
>>> mask = numbers & 1 == 0
array([False, True, False, True, False, True, False, True, False, True])
# filter out the odds
>>> numbers[mask]
array([ 2, 4, 6, 8, 10])
# zero out the odds and retain the shape
>>> numbers * mask
array([ 0, 2, 0, 4, 0, 6, 0, 8, 0, 10])
Reshape
Reshaping simply rearranges the existing items in an array into a new shape.
# Reshape a row vector to a column vector
>>> row = np.array([1,2,3])
>>> np.reshape(row, (3,1))
array([[1],
[2],
[3]])
>>> np.reshape(row, (-1,1))
array([[1],
[2],
[3]])
Transform
All the power of NumPy comes from its ability to efficiently transform large arrays of data for scientific and engineering computations. This is really a vast topic and we will only touch upon a few key transformations here.
# Vector
>>> row = np.array([1, 2, 3])
# Scale
>>> row*2
array([2, 4, 6])
# Shift
>>> row + np.array([5,5,5])
array([6, 7, 8])
# Rotate by -90 degrees around the z-axis
>>> row = np.array([1, 2, 3])
>>> rotation = np.array([[0, -1, 0],[1, 0, 0],[0, 0, 1]])
>>> np.dot(rotation, row)
array([-2, 1, 3])
# Transpose
>>> rows = np.array([[1,2,3],[2,3,4]])
>>> rows.T
array([[1, 2],
[2, 3],
[3, 4]])
Sort
Sorting is a bit tricky. The Python sort function does not behave the same way as it does for lists.
# Sorting vectors on x-coordinate
>>> rows = np.array([[2, 1, 3],[1, 2, 3]])
# naive sort
>>> np.sort(rows, axis=0)
array([[1, 1, 3],
[2, 2, 3]])
# output does not contain the same vectors at all!
# Correct method:
# Obtain the sorted indices for first column (x)
# and then use those indices to sort all the columns
>>> ind = np.argsort(rows[:,0],axis=0).reshape(-1,1)
>>> ind = np.repeat(ind, rows.shape[-1],axis=-1)
>>> ind
array([[1, 1, 1],
[0, 0, 0]])
>>> np.take_along_axis(rows,ind,axis=0)
array([[1, 2, 3],
[2, 1, 3]])

Sorting a NumPy array of vectors
DataFrame
The pandas library provides functionality to manipulate tabular data.
DataFrames are used in machine learning to load, analyze, process, and feed the input data sets into the model, and then format the fitted and predicted output for presentation.
Similar to spreadsheets and SQL tables, a pandas DataFrame is a 2D structure with named/indexed columns and rows.
>>> import pandas as pd
>>> rows = [[2, 1, 3], [1, 2, 3], [3, 1, 0], [10, 100, 20],
[200, 30, 0]]
>>> rows_df = pd.DataFrame(rows)
>>> rows_df.columns = ['x', 'y', 'z']
>>> rows_df
x y z
0 2 1 3
1 1 2 3
2 3 1 0
3 10 100 20
4 200 30 0
Query
# Access row by index
>>> rows_df.loc[0]
x 2
y 1
z 3
Name: 0, dtype: int64
# Access column by label
>>> rows_df['x']
0 2
1 1
2 3
3 10
4 200
Name: x, dtype: int64
# Extract z-intercepts
>>> rows_df.query('z == 0')
x y z
2 3 1 0
4 200 30 0
>>> rows_df[rows_df['z'] == 0]
x y z
2 3 1 0
4 200 30 0
Transform
# Transpose
>>> rows_df.T
0 1 2 3 4
x 2 1 3 10 200
y 1 2 1 100 30
z 3 3 0 20 0
# Add computed columns
>>> pd.options.display.float_format = '{:,.2f}'.format
>>> rows_df['l2_norm'] = np.linalg.norm(rows_df.iloc[:, :3], axis=1)
>>> rows_df
x y z l2_norm
0 2 1 3 3.74
1 1 2 3 3.74
2 3 1 0 3.16
3 10 100 20 102.47
4 200 30 0 202.24
# Zip with another series
>>> w = pd.Series([30, 45, 60, 100, 10])
>>> rows_df['w'] = w
>>> rows_df
x y z l2_norm w
0 2 1 3 3.74 30
1 1 2 3 3.74 45
2 3 1 0 3.16 60
3 10 100 20 102.47 100
4 200 30 0 202.24 10
# Insert another column
>>> labels = ['bird', 'plane', 'superman', 'bird', 'plane']
>>> rows_df.insert(0, "object", labels)
>>> rows_df
object x y z l2_norm w
0 bird 2 1 3 3.74 30
1 plane 1 2 3 3.74 45
2 superman 3 1 0 3.16 60
3 bird 10 100 20 102.47 100
4 plane 200 30 0 202.24 10
# Merge with another dataframe
>>> extra_df = pd.DataFrame([[10], [1000], [10000], [500], [200]])
>>> extra_df.columns = ['v']
>>> extra_df.insert(0, "object", labels)
>>> extra_df
object v
0 bird 10
1 plane 1000
2 superman 10000
3 bird 500
4 plane 200
>>> rows_df = rows_df.merge(extra_df, left_index=True, right_index=True, how='inner')
>>> rows_df
object_x x y z l2_norm w object_y v
0 bird 2 1 3 3.74 30 bird 10
1 plane 1 2 3 3.74 45 plane 1000
2 superman 3 1 0 3.16 60 superman 10000
3 bird 10 100 20 102.47 100 bird 500
4 plane 200 30 0 202.24 10 plane 200
# Drop a column
>>> rows_df = rows_df.drop('object_y',axis=1)
object_x x y z l2_norm w v
0 bird 2 1 3 3.74 30 10
1 plane 1 2 3 3.74 45 1000
2 superman 3 1 0 3.16 60 10000
3 bird 10 100 20 102.47 100 500
4 plane 200 30 0 202.24 10 200
# Rename a column
>>> rows_df.rename(columns={'object_x':'object'}, inplace=True)
Sort
>>> rows_df.sort_values(by='l2_norm')
object x y z l2_norm w v
2 superman 3 1 0 3.16 60 10000
0 bird 2 1 3 3.74 30 10
1 plane 1 2 3 3.74 45 1000
3 bird 10 100 20 102.47 100 500
4 plane 200 30 0 202.24 10 200
Aggregate
>>> rows_df[['object','v']].groupby('object').mean()
v
object
bird 255
plane 600
superman 10000
Summary
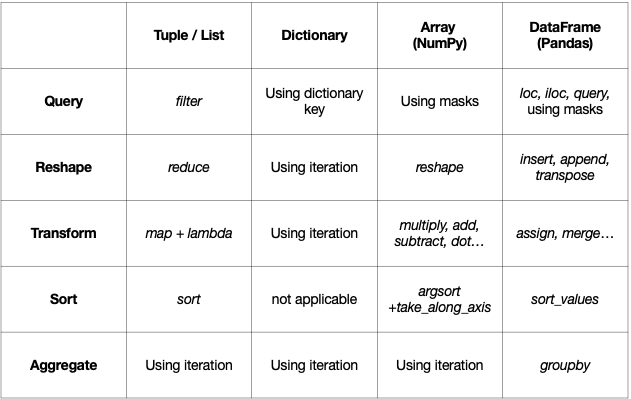
Below is a summary of basic Python collections and various techniques available to manipulate them:
Thank you for reading!
#Python #Java #Machine Learning #Data Science #Programming
