Introduction
If you google “data science use cases”, you will find hundreds of lists of them, each item starting with a buzz word such as fraud detection, recommendation system or other fancier terms. A short paragraph follows, attempting to explain it in 200 words, barely enough to put this buzz word together with other buzz words such as AI, data science, machine learning, deep learning, all spiced up with superlatives. Anyway, data science (or AI, or machine learning, or deep learning) should make things better, or else, what’s the point?Looking at those lists, it could be puzzling for a DS¹ trying to make sense of what needs to be actually done. They are inspirations at the best, but not recipes nor contain any know-how. As (good) DS, we should be able to identify a potential use case, find and master the tools to solve it, and deliver impact together with our business colleagues. Let’s start from the identification, and here is how you can do it well.
Identify data science use cases
There are at least two prerequisites for a data science use case, one is data (unsurprisingly) and the second is a business decision which lead to an action. Data science provides tools to examine the mechanisms underlying the data, so that it can be leveraged to make better business decisions. In a very schematic way, we can design an exercise to find out the best data science use cases in 4 steps:Step 1: understand the context
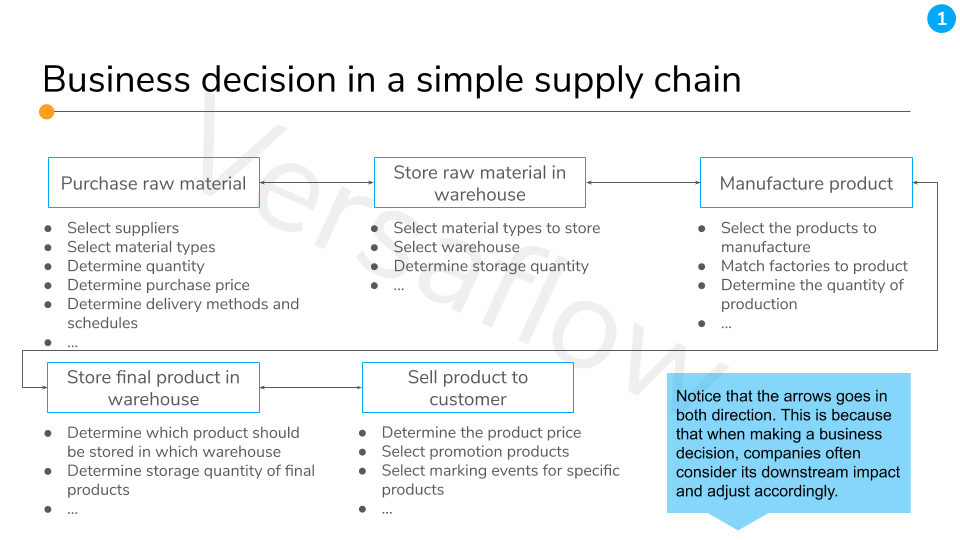
- Draw structure of key decisions and the following actions (BDA²) in the business devision that you are interested, like this. All BDAs are grouped under a node, representing the unit who owns the decisions or actions. The arrows between the nodes indicate how they impact each other, either through a material impact (production in factories are dependent on raw material supply) or an information exchange (a level of warehouse stock is largely determined by the need from the factory).
Click here to see the full deck
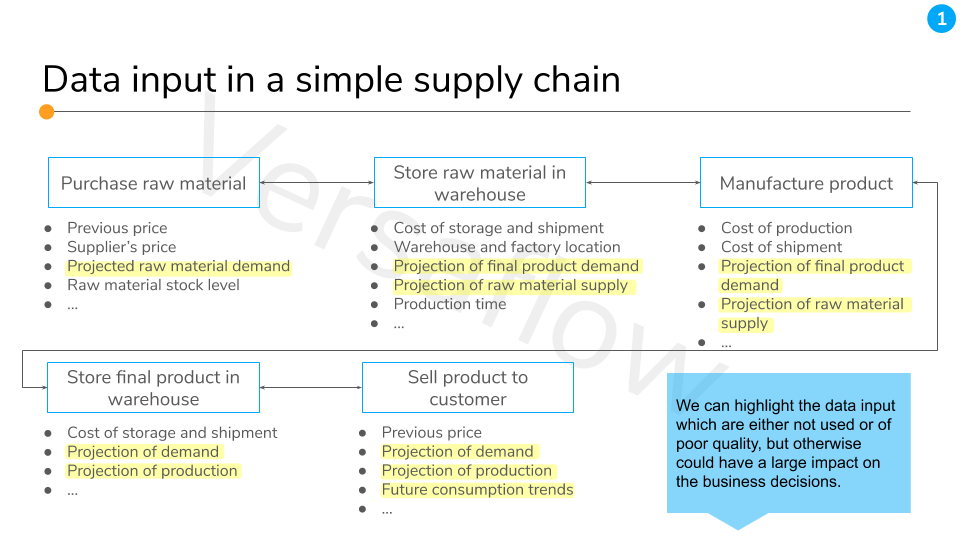
- Then list out the data used to drive this BDA. Ask yourself if these data are of good quality, or if any other data could be pulled in to improve this decision making, note them down as well.
Click here to see the full deck
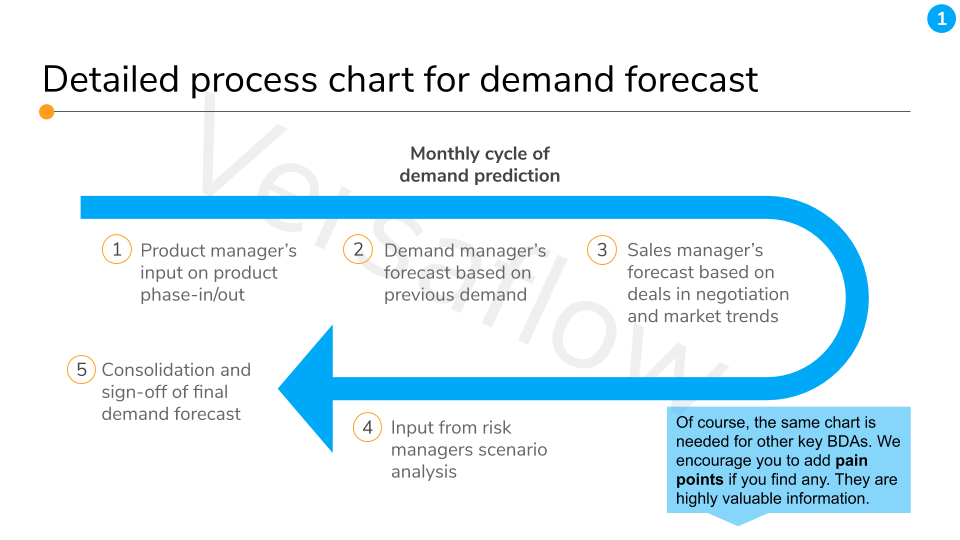
- Finally, add some information on the processes that drives those BDA, paying attention to the time needed, people or business unit involved, how well it is supported by technologies, and if there are any pain-points.
Click here to see the full deck
This process could take a while, since it’s not always easy to know what going on in other parts of the company. However, it is crucial to have a good understanding about the mechanism and rationales that drives a BDA, otherwise we risk passing over the real problem to solve and end up with a perfect but useless model. So, search for documentations and presentations, and most importantly, talk to people.Step 2: narrow down the focusIt’s time to evaluate and select the best BDAs for your data science project. Try to answer the following questions for each of them:
- Does it have a large financial impact, i.e. either incur high costs, or generate significant revenue?Is it a necessary input for many other BDAs and thus need to be of high quality?Is there and pressing pain-points that could be alleviated by using better technology and data science?How likely are OP³ to accept new technology and changes in their ways of working?

For the ideal BDAs, you should be able to answer “yes” to all these questions. They are the ones which can benefit the most from data science, and that’s why we should focus on them.Step 3: high-level data evaluationData quality is crucial to the feasibility of a data science use case. An early evaluation can helps us prioritise, and choose the right method and technology. To get a high-level understanding of the data quality, we can consider the following aspects:
- Is data a key input (if not the major) for the decision making? If not, would it be better if some data is used as a key/major input?Are data sources reliable? How does the ETL work? Is it dependent on legacy IT systems? Does it require manual operations? How well is the database maintained?What’s the size of the data used? What’s the size of the data that can potentially be used in the decision making?How likely can we get the additional data needed to improve the current decision?

Click here to see the full deck
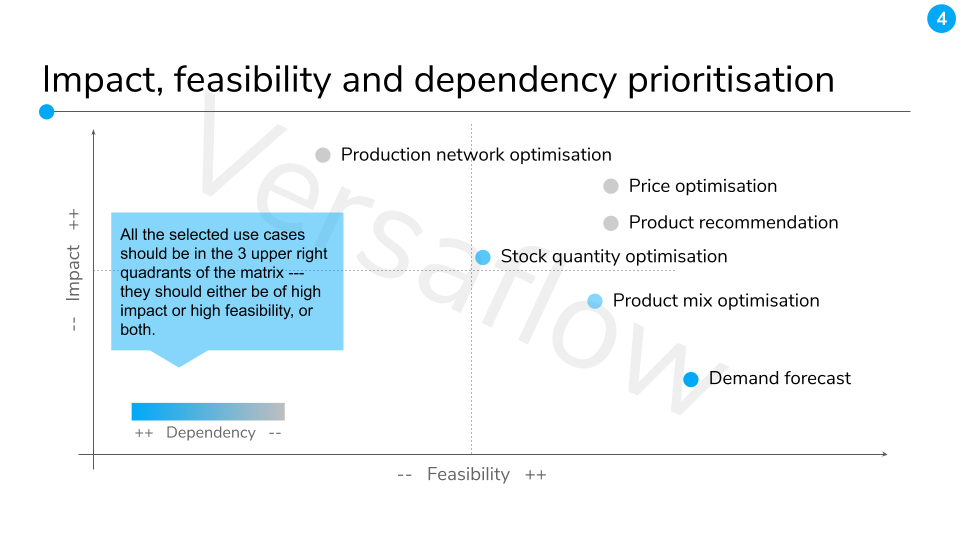
In the best scenario, the data source should be reliable, and used as a main input of the decision making. The data size could indicate to us right tools (e.g. distributed system should be considered when the data size is large) and often times the methods (e.g. for small data set, simple algorithms such as linear regression or traditional statistical methods are preferred to avoid overfitting).Step 4: wrap up and concludeBy comparing the results from step 2 and 3, we should be able to select or even rank the BDAs according to these criteria based on two dimensions — impact and feasibility:
- [impact] it has a large impact, either in financial or non financial terms_[impact]_ data science and technologies can greatly improve its outcome_[feasibility]_ key stakeholders are willing to accept new technology and change_[feasibility]_ the required data input is available and of good quality_[feasibility] _the DS and SE⁴ team has the skillset to deploy the required technology
Click here to see the full deck
Use cases can then be defined by grouping together closely linked BDAs with overlapping data requirements and key stakeholders. Finally, to find out where to start and where to finish, we will again look at the impact and feasibility of each use case, but now with an additional dimension — the dependency. Needless to say, the ones on which other cases are depend should started early. And now, you have a solid roadmap for your data science use case(s) !

#data-science #strategy #use-cases #towards-data-science #business