The prior SVMs worked with linearly separable data. If we would like to separate non-linear data, we can change how we project the linear separator onto the data. This is done by changing the kernel in the SVM loss function. In this article, we introduce how to change kernels and separate non-linear separable data.
Getting ready
We will motivate the usage of kernels in support vector machines. In the linear SVM section, we solved the soft margin with a specific loss function. A different approach to this method is to solve what is called the dual of the optimization problem. It can be shown that the dual for the linear SVM problem is given by the following formula:
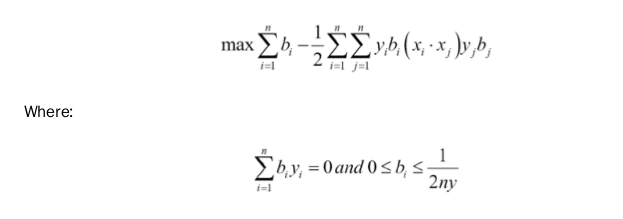
Here, the variable in the model will be the b vector. Ideally, this vector will be quite sparse, only taking on values near 1 and -1 for the corresponding support vectors of our dataset. Our data point vectors are indicated by_ xi _and our targets ( 1 or -1 ) are represented by _yi _.
The kernel in the preceding equations is the dot product,_ xi.xj,_, which gives us the linear kernel. This kernel is a square matrix filled with the _i,j _dot products of the data points.
Instead of just doing the dot product between data points, we can expand them with more complicated functions into higher dimensions, in which the classes may be linearly separable. This may seem needlessly complicated, but if we select a function, k, that has the property where:

#deep-learning #tensorflow #machine-learning #kernel