The series so far:
Heaps are not necessarily the developer’s favourite child, as they are not very performant, especially when it comes to selecting data (most people think so!). Certainly, there is something true about this opinion, but in the end, it is always the workload that decides it. In this article, I describe how a Heap works when data are selected. If you understand the process in SQL Server when reading data from a Heap, you can easily decide if a Heap is the best solution for your workload.
Advanced Scanning
As you may know, Heaps can only use Table Scans to retrieve data which are requested by the client software. In SQL Server Enterprise, the advanced scan feature allows multiple tasks to share full table scans. If the execution plan of a Transact-SQL statement requires a scan of the data pages in a table, and the Database Engine detects that the table is already being scanned for another execution plan, the Database Engine joins the second scan to the first, at the current location of the second scan. The Database Engine reads each page one time and passes the rows from each page to both execution plans. This continues until the end of the table is reached.
At that point, the first execution plan has the complete results of a scan, but the second execution plan must still retrieve the data pages that were read before it joined the in-progress scan. The scan for the second execution plan then wraps back to the first data page of the table and scans forward to where it joined the first scan. Any number of scans can be combined like this. The Database Engine will keep looping through the data pages until it has completed all the scans. This mechanism is also called “merry-go-round scanning” and demonstrates why the order of the results returned from a SELECT statement cannot be guaranteed without an ORDER BY clause.
Select data in a Heap
Since a Heap has no index structures, Microsoft SQL Server must always read the entire table. Microsoft SQL Server solves the problem with predicates with a FILTER operator (Predicate Pushdown). For all examples shown in this article, I created a table with ~ 4,000,000 data records from my demo database [CustomerOrders]. After restoring the database, run the code to create the new table, CustomerOrderList.
– Create a BIG table with ~4.000.000 rows
SELECT C . ID AS Customer_Id ,
C . Name ,
A . CCode ,
A . ZIP ,
A . City ,
A . Street ,
A .[ State ],
CO . OrderNumber ,
CO . InvoiceNumber ,
CO . OrderDate ,
CO . OrderStatus_Id ,
CO . Employee_Id ,
CO . InsertUser ,
CO . InsertDate
INTO dbo . CustomerOrderList
FROM CustomerOrders . dbo . Customers AS C
INNER JOIN CustomerOrders . dbo . CustomerAddresses AS CA
ON ( C . Id = CA . Customer_Id )
INNER JOIN CustomerOrders . dbo . Addresses AS A
ON ( CA . Address_Id = A . Id )
INNER JOIN CustomerOrders . dbo . CustomerOrders AS CO
ON ( C . Id = CO . Customer_Id )
ORDER BY
C . Id ,
CO . OrderDate
OPTION ( MAXDOP 1 );
GO
When data is read from a Heap, a TABLE SCAN operator is used in the execution plan – regardless of the number of data records that have to be delivered to the client.
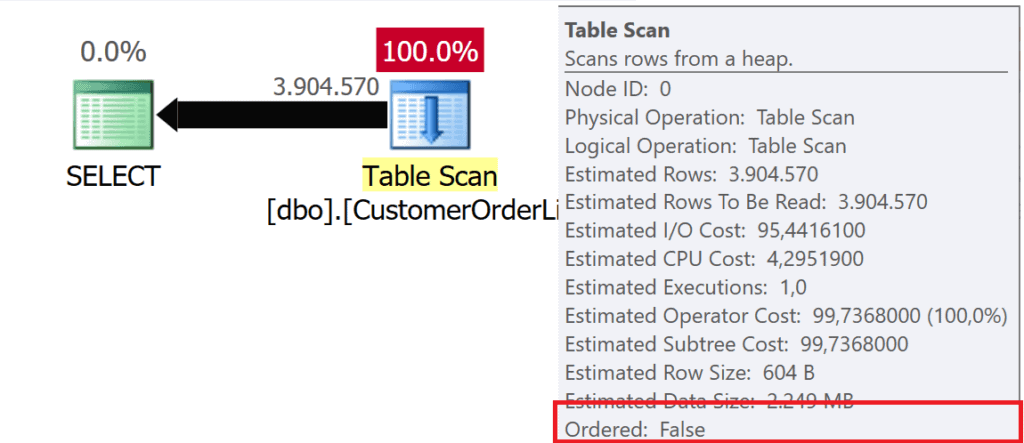
Figure 1: SELECT * FROM dbo.CustomerList
When Microsoft SQL Server reads data from a table or an index, this can be done in two ways:
- The data selection follows the B-tree structure of an index
- The data is selected in accordance with the logical arrangement of data pages
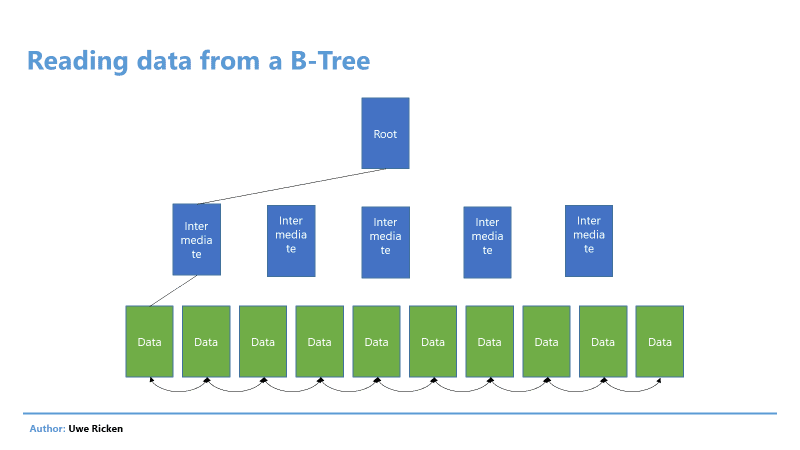
Figure 2: Reading data in a B-Tree basically follows the index structure
In a Heap, the reading process takes place in the order in which data was saved on the data pages. Microsoft SQL Server reads information about the data pages of the Heap from the IAM page of a table, which is described in the article “Heaps in SQL Server: Part 1 The Basics”.
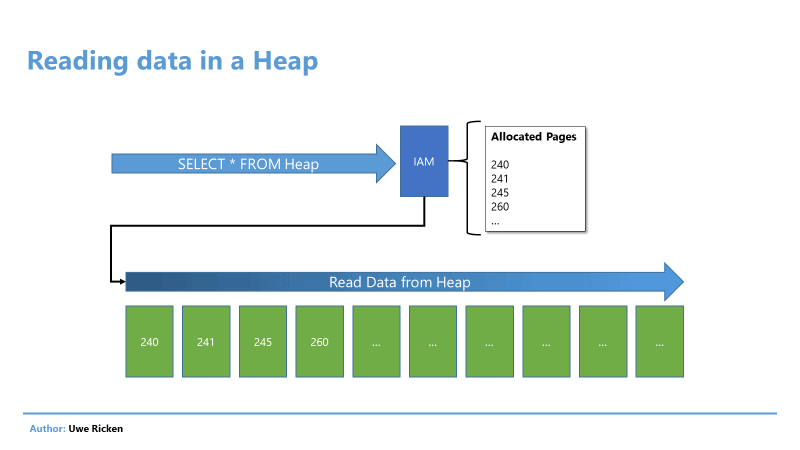
Figure 3: Reading data in a Heap follows the logical order of data pages
After the “route” for reading the data has been read from the IAM, the SCAN process begins to send the data to the client. This technique is called “Allocation Order Scan” and can be observed above all at Heaps.
If the data is limited by a predicate, the way of working does not change. Since the data is unsorted in a Heap, Microsoft SQL Server must always search the complete table (all data pages).
SELECT * FROM dbo . CustomerOrderList
WHERE Customer_Id = 10 ;
GO
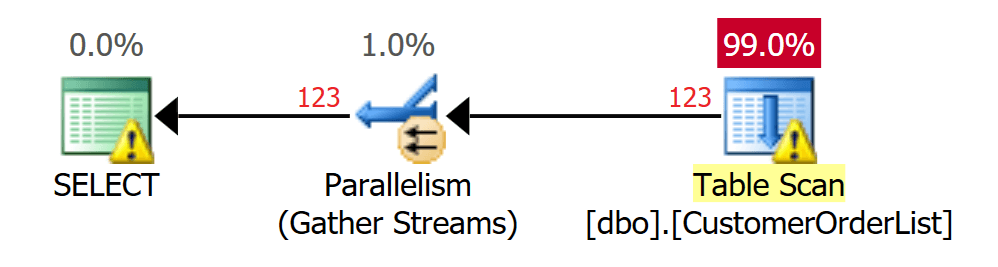
Figure 4: Scan over the whole table
The filtering is called “predicate pushdown”. Before further processes are processed, the number of data records is reduced as much as possible! A predicate pushdown can be made visible in the execution plan using trace flag 9130!
SELECT * FROM dbo . CustomerOrderList
WHERE Customer_Id = 10
OPTION ( QUERYTRACEON 9130 );
GO

Figure 5: FILTER Operator for selected data
Advantages of reading from Heaps
Heaps appear to be inferior to an index when reading data. However, this statement only applies if the data is to be limited by a predicate. In fact, when reading the complete table, the Heap has two – in my view – significant advantages:
- No B-tree structure has to be read; only the data pages are read.
- If the Heap is not fragmented and has no forwarded records (described in a later article), Heaps can be read sequentially. Data is read from the storage in the order in which they were entered.
- An index always follows the pointers to the next data page. If the index is fragmented, random reads occur that are not as powerful as sequential read operations.
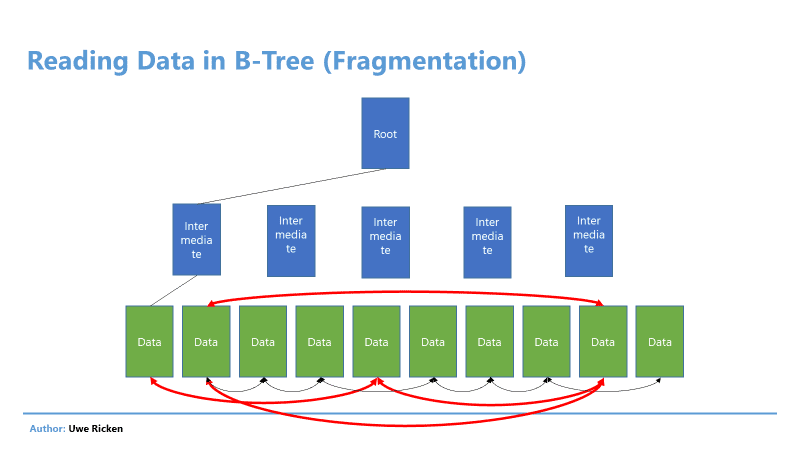
Figure 6: Reading from a B-Tree
Disadvantages when reading from Heaps
One of the biggest drawbacks when reading data from a Heap is the IAM scan while reading the data. Microsoft SQL Server must hold a lock to ensure that the metadata of the table structure is not changed during the read process.
The code shown below creates an extended event that records all the locks set in a transaction. The script only records activity for a predefined user session, so be sure to change the user session ID in the script to match yours.
– Create an XEvent for analysis of the locking
CREATE EVENT SESSION [ Track Lockings ]
ON SERVER
ADD EVENT sqlserver . lock_acquired
( ACTION ( package0 . event_sequence )
WHERE
(
sqlserver . session_id = 55
AND mode = 1
)
),
ADD EVENT sqlserver . lock_released
( ACTION ( package0 . event_sequence )
WHERE
(
sqlserver . session_id = 55
AND mode = 1
)
),
ADD EVENT sqlserver . sql_statement_completed
( ACTION ( package0 . event_sequence )
WHERE ( sqlserver . session_id = 55 )
),
ADD EVENT sqlserver . sql_statement_starting
( ACTION ( package0 . event_sequence )
WHERE ( sqlserver . session_id = 55 )
)
WITH
(
MAX_MEMORY = 4096KB ,
EVENT_RETENTION_MODE = ALLOW_SINGLE_EVENT_LOSS ,
MAX_DISPATCH_LATENCY = 30 SECONDS ,
MAX_EVENT_SIZE = 0KB ,
MEMORY_PARTITION_MODE = NONE ,
TRACK_CAUSALITY = ON ,
STARTUP_STATE = OFF
);
GO
ALTER EVENT SESSION [ Track Lockings ]
ON SERVER
STATE = START ;
GO
When you run the SELECT statement from the first demo, the Extended Event session will record the following activities:

Figure 7: Holding a SCH_S-Lock when reading data from a Heap
The lock is not released until the SCAN operation has been completed.
NOTE: If Microsoft SQL Server chooses a parallel plan when executing the query, EVERY thread holds a SCH‑S lock on the table.
In a highly competitive system, such locks are not desirable because they serialize operations. The larger the Heap, the longer the locks will prevent further metadata operations:
- Create indexes
- Rebuild indexes
- Add or delete columns
- TRUNCATE operations
- …
Another “shortcoming” of Heaps can be the high number of I/O if only small amounts of data have to be selected. Here, however, it is advisable to use a NONCLUSTERED INDEX to optimize these operations.
#development #homepage #sql prompt #sql