Concepts and relations explored by mathematicians with some application in mind — turn out decades later to be the unexpected solutions to problems they initially never imagined. Riemann’s geometry discovered only for pure reason- with absolutely no application in mind, later was used by Einstein to explain space-time fabric and general relativity.
In Reinforcement Learning (RL) an agent seeks an optimal policy for a sequential decision making problem. The common approach to reinforcement learning which models the expectation of this return, or value. But the recent advances in RL which comes under the banner of “Distributional RL” focuses on the distribution of the random return R received by an agent. State-action values can be explicitly treated as a random variable Z whose expectation is the value Q
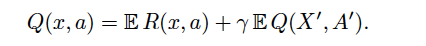
Eq1: Normal Bellman operator B
Normal Bellman operator B (Eq-1)plays a crucial role in approximating the Q values by iteratively minimise the L-square distance between Q and BQ (TD-learning).
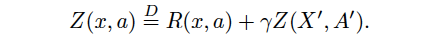
Eq2: Distributional Bellman operator Ⲧπ
Similarly Distributional Bellman operator Ⲧπ approximatesthe Z values by iteratively minimise the DISTANCE between Z and ⲦπZ**.**
Z and** Ⲧπ**Z are not vectors instead they are distributions, how does one calculate distance between 2 different probability distributions? The answers can be many (KL, DL metrics etc) but we are particularly interested in Wasserstein Distance.
#machine-learning #probability-distributions #probability
