Quick summary: JavaScript brings interactivity and dynamism to the web that’s built on the static foundation of HTML markup. This guide covers everything you need to know to make sure using JavaScript doesn’t impair your rankings or your User Experience.
What is JavaScript SEO?
JavaScript SEO is a branch of technical SEO that makes JS-powered websites:
- easy for search engines to fully crawl, render, and index,
- accessible to users with outdated browsers,
- keep their metadata and internal linking consistent,
- load fast despite having to parse and execute JavaScript code.
JavaScript is extremely popular. Based on my research, as much as 80% of the popular eCommerce stores in the USA use JavaScript for generating main content or links to similar products.

However, many JavaScript websites – despite its popularity – underperform in Google because they don’t do JavaScript SEO properly.
In this article, I will guide you through why it’s happening and how to fix it. You’ll learn:
- how Google and other search engines deal with JavaScript
- how to check if your website has a problem with JavaScript
- what are the best practices of JavaScript SEO
- the most common problems with JavaScript that SEOs overlook
I will provide tons of additional tips and recommendations, too. We have a lot to cover, so get yourself a cup of coffee (or two) and let’s get started.
Contents
- What is JavaScript and How is it Used?
- Can Google Index JavaScript?
- The Foundations for Successful JavaScript SEO
- Different Ways of Presenting JavaScript Content to Google
- Common Pitfalls with JS Websites
- FAQ - BONUS CHAPTER!
Chapter 1: What is JavaScript and How is it Used?
In 2020, there’s no doubt: JavaScript is the future of the web.
Of course, HTML and CSS are the foundation. But virtually every modern web developer is expected to code in JavaScript too.
But what can JavaScript do, exactly? And how can you check which elements of your website are using it? Read on and you’ll find out.

JavaScript is an extremely popular programming language. It’s used by developers to make websites interactive.
JavaScript has the unique ability to dynamically update the content of a page.
For instance, it’s used by Forex and CFD trading platforms to continually update the exchange rates in real-time.
Now, imagine a website like Forex.com without JavaScript.
Without JavaScript, users would have to manually refresh the website to see the current exchange rates. JavaScript simply makes their lives much easier.
In other words, you can build a website using only HTML and CSS, but JavaScript is what makes it dynamic and interactive.
In other words, you can build a website using only HTML and CSS, but JavaScript is what makes it dynamic and interactive.
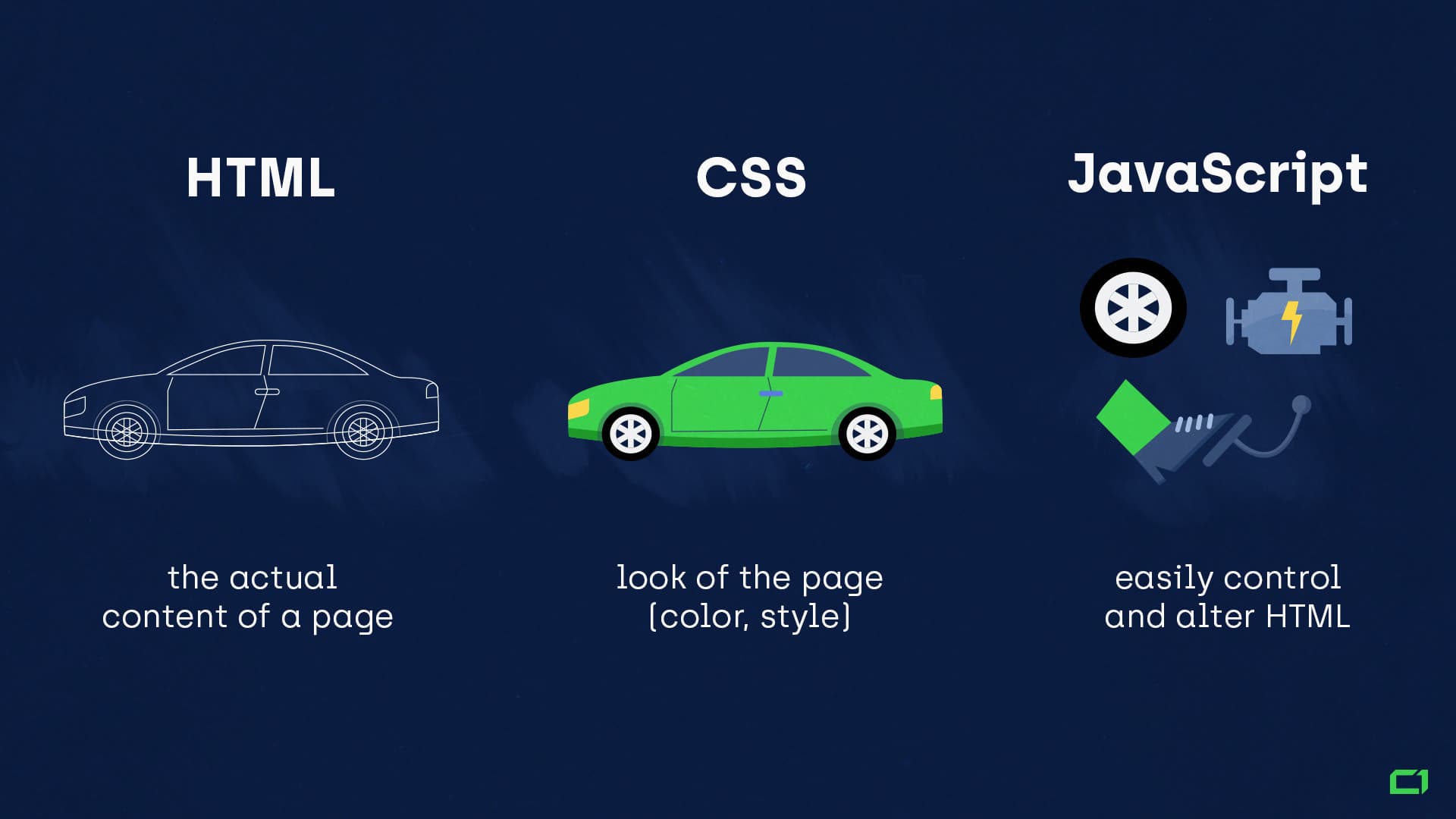
- HTML defines the actual content of a page (body/frame of a car).
- CSS defines the look of the page (colors, style).
- JavaScript adds interactivity to the page. It can easily control and alter HTML (engine + wheel + gas pedals).
Which website elements are commonly generated by JavaScript?
The types of content that are commonly generated by JavaScript can be basically put into six categories:

- Pagination
- Internal links
- Top products
- Reviews
- Comments
- Main content (rarely)
How do I know if my website is using JavaScript?
1. Use WWJD
To make it easy for you to check if your website relies on JavaScript, we created WWJD – What Would JavaScript Do- which is just one of our FREE tools.
Simply go to WWJD and type the URL of your website into the console.
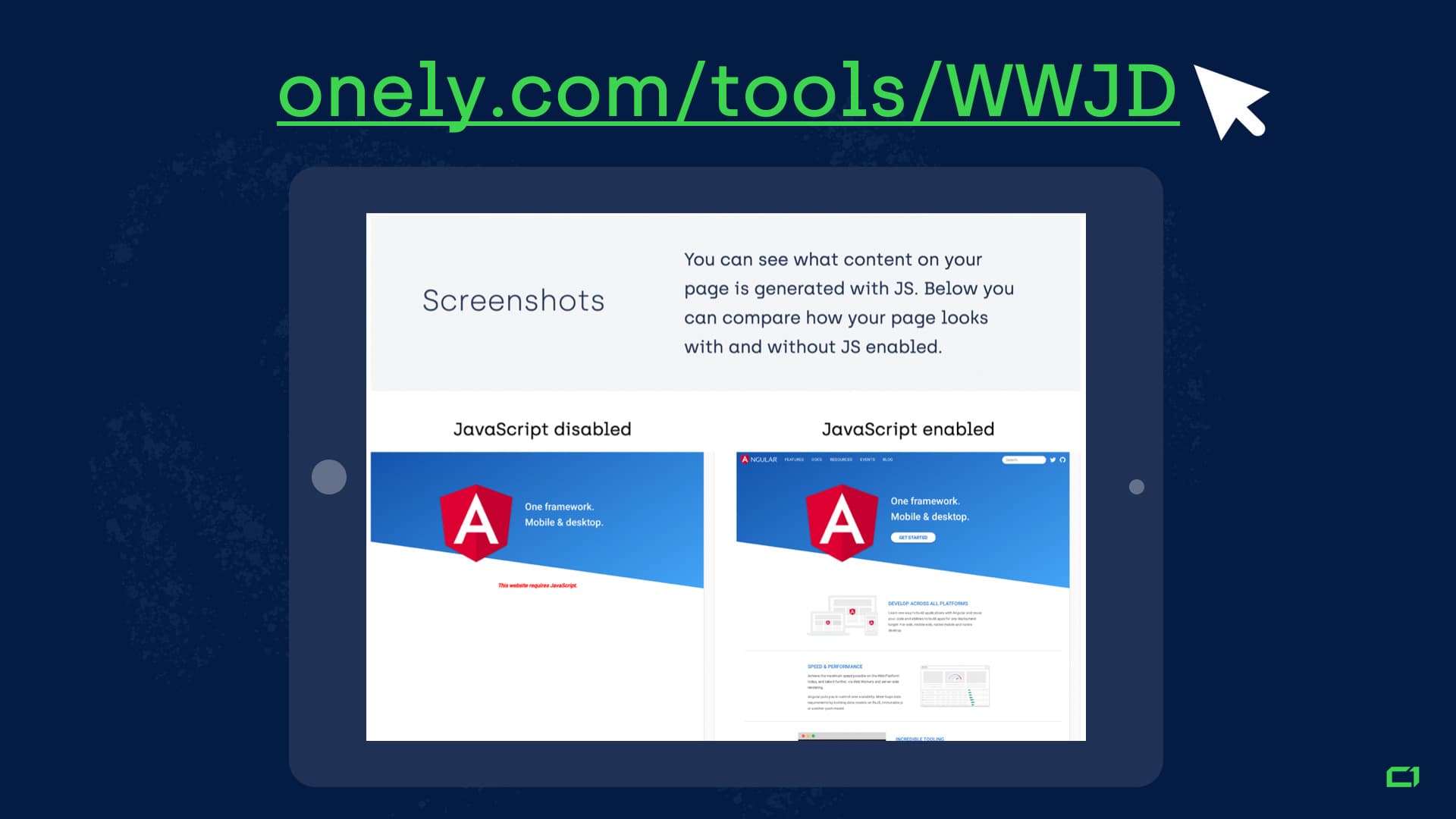
Then look at the screenshots that the tool generates and compare the two versions of your page – the one with JavaScript enabled and the one with JavaScript disabled.
2. Use a browser plugin
Using our tool is not the only way to check your website’s JavaScript dependency. You can also use a browser plugin like Quick JavaScript Switcher on Chrome, or JavaScript Switch on Firefox.
When you use the plugin, the page you’re currently on will be reloaded with JavaScript disabled.
If some of the elements on the page disappear, it means that they were generated by JavaScript.
An important tip: if you decide to use a browser plugin instead of WWJD, make sure you also take a look at the page source and the DOM (Document Object Model) and pay attention to your canonical tags and links. It often happens that JavaScript doesn’t change much visually and you wouldn’t notice that it’s even there. However, it can change your metadata under the hood, which can potentially lead to serious issues.
Important: “view source” is not enough when auditing JS websites

You may hear that investigating what’s inside the source code of your web pages is one of the most important things in an SEO audit. However, with JavaScript in the picture, it gets more complicated.
HTML is a file that represents just the raw information used by the browser to parse the page. It contains some markup representing paragraphs, images, links, and references to JS and CSS files.
You can see the initial HTML of your page by simply right-clicking -> View page source.
However, by viewing the page source you will not see any of the dynamic content updated by JavaScript.
With JavaScript websites, you should look at the DOM instead. You can do it by right-clicking -> Inspect element.
Here’s how I would describe the difference between the initial HTML and the DOM:
- The initial HTML (right-click -> View page source) is just a cooking recipe. It provides information about what ingredients you should use to bake a cake. It contains a set of instructions. But it’s not the actual cake.

- DOM (right-click -> inspect element) is the actual cake. In the beginning, it’s just a recipe (an HTML document) and then, after some time it gains a form and then it’s baked (page fully loaded).

Note: If Google can’t fully render your page, it can still index just the initial HTML (which doesn’t contain dynamically updated content).
Now that you’re sure what elements of your page depend on JavaScript, it’s time to find out if Google can properly deal with your JavaScript content.
Chapter 2: Can Google Index JavaScript?
JavaScript makes the web truly dynamic and interactive, and that’s something that users love.
But what about Google and other search engines? Can they easily deal with JavaScript, or is it more of a love-hate relationship?
As a leading technical SEO agency, we’re constantly doing research to look for Google’s strengths and weaknesses.
And when it comes to JavaScript, it’s sort of a mixed bag…

Indexing JavaScript content by Google is never guaranteed.
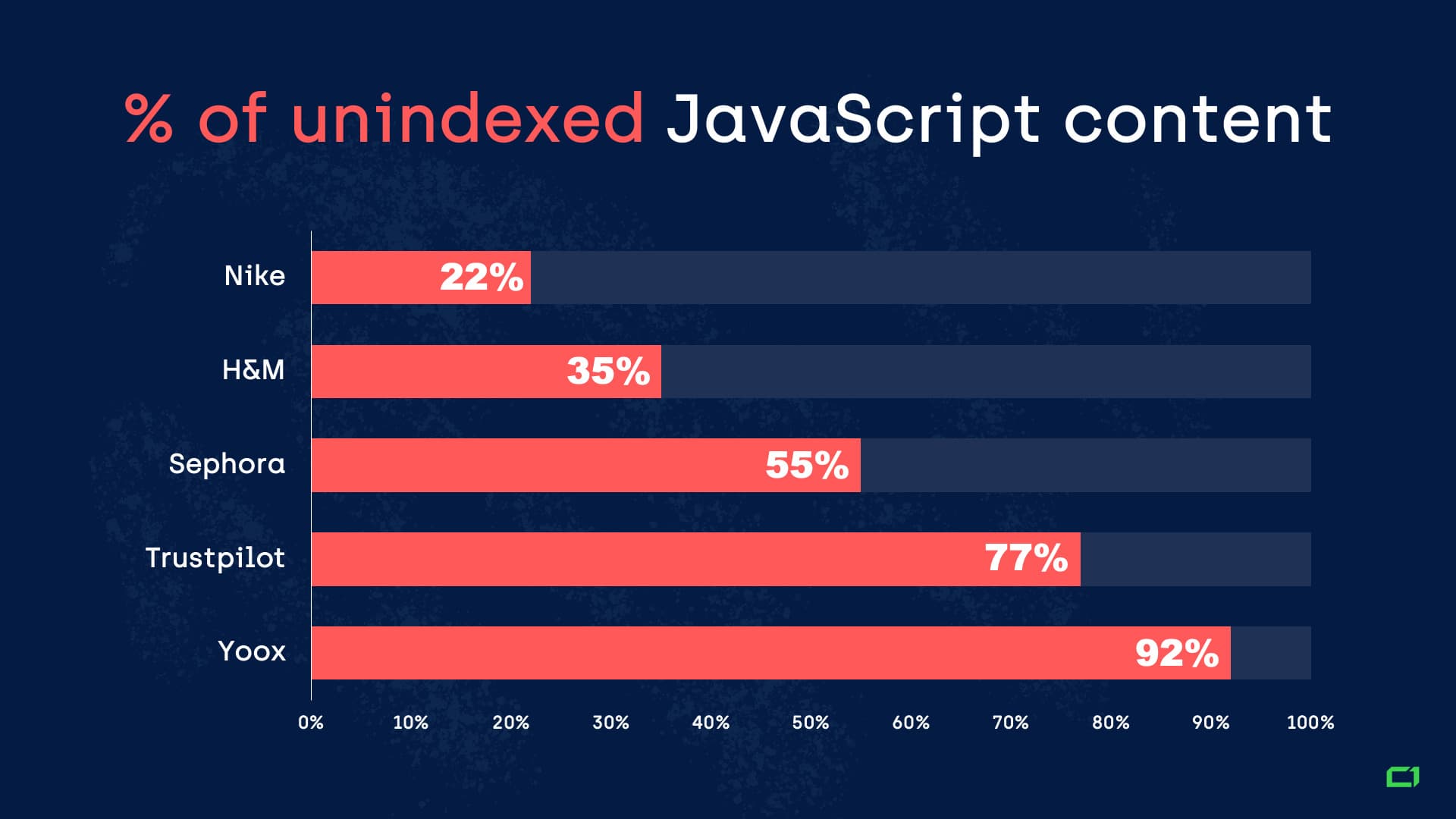
We recently investigated multiple websites that are using JavaScript. It turned out that on average, their JavaScript content was not indexed by Google in 25% of the cases.
That’s one out of four times.
Here are some examples of the tested websites:
On the other hand, some of the websites we tested did very well:
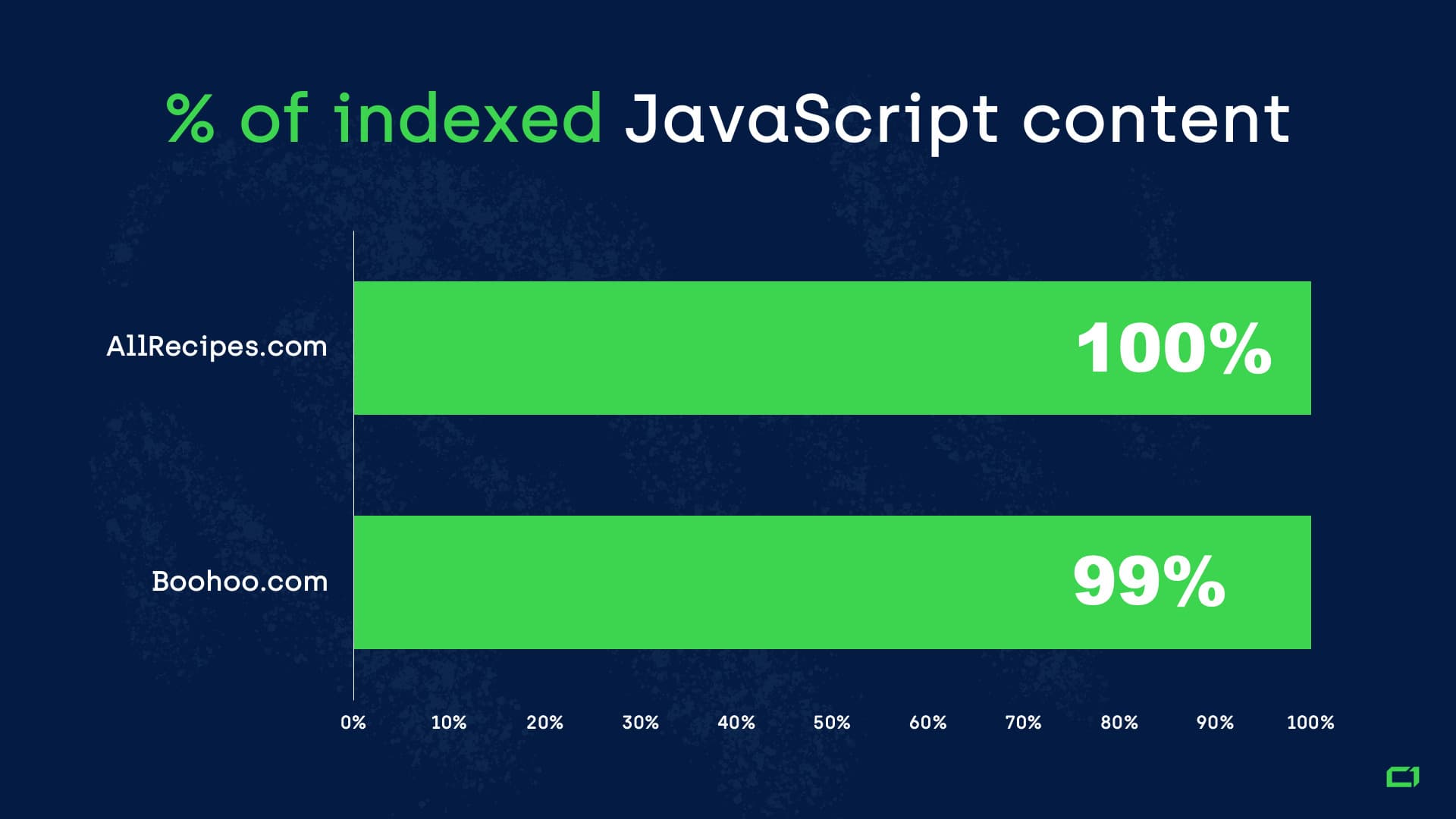
As you can see, Google can index JavaScript content on some websites much better than others. This means that these issues are self-induced and can be avoided. Keep reading to learn how.
It’s also important to know that indexing content isn’t guaranteed even in the case of HTML websites. JavaScript simply adds more complexity, as there are a couple more things that could go wrong.
Why Google (and other search engines) may have difficulties with JavaScript
I. The complexity of JavaScript crawling
In the case of crawling traditional HTML websites, everything is easy and straightforward, and the whole process is lightning fast:
- Googlebot downloads an HTML file.
- Googlebot extracts the links from the source code and can visit them simultaneously.
- Googlebot downloads the CSS files.
- Googlebot sends all the downloaded resources to Google’s Indexer (Caffeine).
- The indexer (Caffeine) indexes the page.
For Google, things get complicated when it comes to crawling a JavaScript-based website:
- Googlebot downloads an HTML file.
- Googlebot finds no links in the source code as they are only injected after executing JavaScript.
- Googlebot downloads the CSS and JS files.
- Googlebot has to use the Google Web Rendering Service (a part of the Caffeine Indexer) to parse, compile and execute JavaScript.
- WRS fetches the data from external APIs, from the database, etc.
- The indexer can index the content.
- Google can discover new links and add them to the Googlebot’s crawling queue. In the case of the HTML website, that’s the second step.
In the meantime, there are many things that can go wrong with rendering and indexing JavaScript. As you can see, the whole process is much more complicated with JavaScript involved. The following things should be taken into account:
- Parsing, compiling and running JavaScript files is very time-consuming – both for users and Google. Think of your users! I bet anywhere between 20-50% of your website’s users view it on their mobile phone. Do you know how long it takes to parse 1 MB of JavaScript on a mobile device? According to Sam Saccone from Google: Samsung Galaxy S7 can do it in ~850ms and Nexus 5 in ~1700ms. After parsing JavaScript, it has to be compiled and executed, which takes additional time. Every second counts.
- In the case of a JavaScript-rich website, Google can’t usually index the content until the website is fully rendered.
- The rendering process is not the only thing that is slower. It also refers to the process of discovering new links. With JavaScript-rich websites, it’s common that Google cannot discover any links on a page before the page is rendered.
- The number of pages Googlebot wants to & can crawl is called the crawl budget. Unfortunately, it’s limited, which is important for medium to large websites in particular. If you want to know more about the crawl budget, I advise you to read the Ultimate Guide to the Crawler Budget Optimization by Artur Bowsza, Onely’s SEO Specialist. Also, I recommend reading Barry Adams’ article “JavaScript and SEO: The Difference Between Crawling and Indexing” (the JavaScript = Inefficiency and Good SEO is Efficiency sections, in particular, are must-haves for every SEO who deals with JavaScript).
II. Googlebot Doesn’t Act Like a Real Browser
It’s time to go deeper into the topic of the Web Rendering Service.
As you may know, Googlebot is based on the newest version of Chrome. That means that Googlebot is using the current version of the browser for rendering pages. But it’s not exactly the same.
Googlebot visits web pages just like a user would when using a browser. However, Googlebot is not a typical Chrome browser.
- Googlebot declines user permission requests (i.e. Googlebot will deny video auto-play requests).
- Cookies, local, and session storage are cleared across page loads. If your content relies on cookies or other stored data, Google won’t pick it up.
- Browsers always download all the resources – Googlebot may choose not to.

When you surf the internet, your browser (Chrome, Firefox, Opera, whatever) downloads all the resources (such as images, scripts, stylesheets) that a website consists of and puts it all together for you.
However, since Googlebot acts differently than your browser, its purpose is to crawl the entire internet and grab valuable resources.
The World Wide Web is huge though, so Google optimizes its crawlers for performance. This is why Googlebot sometimes doesn’t load all the resources from the server. Not only that, Googlebot doesn’t even visit all the pages that it encounters.
Google’s algorithms try to detect if a given resource is necessary from a rendering point of view. If it isn’t, it may not be fetched by Googlebot. Google warns webmasters about this in the official documentation.
Googlebot and its Web Rendering Service (WRS) component continuously analyze and identify resources that don’t contribute essential page content and may not fetch such resources. source: Google’s Official Documentation
Because Googlebot doesn’t act like a real browser, Google may not pick some of your JavaScript files. The reason might be that its algorithms decided it’s not necessary from a rendering point of view, or simply due to performance issues (i.e. it took too long to execute a script).
Additionally, as confirmed by Martin Splitt, a Webmaster Trends Analyst at Google, Google might decide that a page doesn’t change much after rendering (after executing JS) so they won’t render it in the future.
Also, rendering JavaScript by Google is still delayed (however, it is much better than in 2017-2018, when we commonly had to wait weeks till Google rendered JavaScript).
If your content requires Google to click, scroll, or perform any other action in order for it to appear, it won‘t be indexed.
Last but not least: Google’s renderer has timeouts. If it takes too long to render your script, Google may simply skip it.
#javascript #seo #web-development #programming #developer
