This is a summary of some of the key points from the paper “A Review of Relational Machine Learning for Knowledge Graphs (28 Sep 2015)”[1], which gives a nice introduction to Knowledge Graphs and some of the methods used to build and expand them.
The key takeaway
Information can be structured in the form of a graph, with nodes representing entities and edges representing relationships between entities. A knowledge graph can be built manually or using automatic information extraction methods on some source text (for example Wikipedia). Given a knowledge graph, statistical models can be used to expand and complete it by inferring missing facts.
The low-down
Topics covered:
- The basics of Knowledge Graphs
- Statistical Relational Learning
- 2.1 Latent Feature Models
- 2.1.1 RESCAL
- 2.1.2 Multi-Layer perceptrons
- 2.1.3 Latent distance models
- 2.2 Graph Feature Models
- 2.2.1 Path Ranking Algorithm
- 2.3 Combining Latent and Graph Feature Models
- Some more cool stuff
1. The basics of Knowledge Graphs
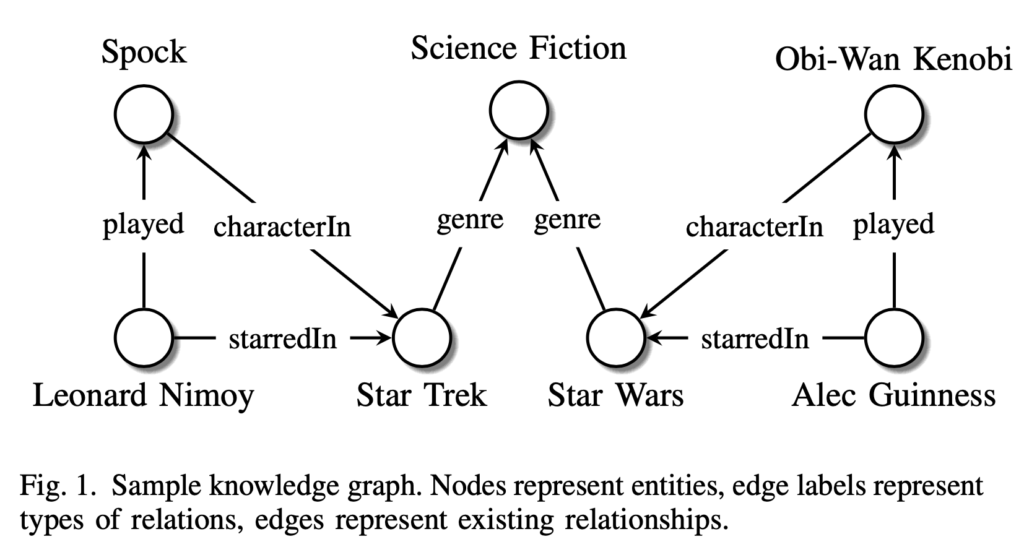
Knowledge Graphs (KGs) are a way of structuring information in graph form, by representing entities (eg: people, places, objects) as nodes, and relationships between entities (eg: being married to, being located in) as edges. Facts are typically represented as “SPO” triples: (Subject, Predicate, Object). Essentially, two nodes connected by a relationship form a fact. For example, a fact in the image above could be: “Spock is a character in Star Trek”. This fact is formed by the two nodes Spock and Star Trek and the relation characterIn forming the SPO triple (Spock, characterIn, Star Trek).
So, existing edges indicate known facts. What about missing edges?
There are two possibilities:
- _Closed World Assumption _(CWA): non-existing triples/edges indicate false relationships: for example, since there is no
starredInedge from Leonard Nimoy to Star Wars, we infer that Leonard Nimoy did not star in Star Wars - _Open World Assumption _(OWA): non-existing triples/edges simply represent unknowns: since there is no
starredInedge from Leonard Nimoy to Star Wars, we don’t know whether Leonard Nimoy starred in Star Wars or not
KGs typically include various types of hierarchies (“Leonard Nimoy is an actor, which is a person, which is a living thing”) and constraints (“a person can only marry another person, not a thing”).
Ways of building Knowledge Graphs:
- Manually, by experts or volunteers
- By automatically extracting them from semi-structured text (eg: Wikipedia infoboxes)
- By automatically extracting them from unstructured text (using natural language processing techniques)
Main tasks in Knowledge Graph curation:
- Link prediction: predicting missing edges in the graph (ie: missing facts)
- Entity resolution: finding different nodes and/or different edges that actually refer to the same thing. For example, a system may contain triples such as (Obama, bornIn, Hawaii) and (Barack Obama, placeOfBirth, Honolulu). We may want to merge the
ObamaandBarack Obamanodes as they are probably referring to the same entity. - Link-based clustering: grouping entities based on the similarity of their links
2. Statistical Relational Learning (SRL) for KGs
Assumption: all entities and types of relationships in a graph are known (there are N_e entities and N_r types of relationships). However, triples are incomplete: that is, some of the nodes in the graph are connected, but there are also pairs of nodes that should be connected but aren’t. This translates to: there are a certain number of true facts, but we only know a subset of them. There could also be duplicates of entities and relationships.
Let’s call e_i the subject node (eg: Spock), e_j the object node (Star Trek), and r_k the relationship type (characterIn). We can now model each possible triple x_ijk = (e_i,r_k,e_j) as a binary random variable y_ijk ∈ {0,1}. Here, y_ijk is 1 if the triple exists and 0 otherwise. In the closed world assumption, a 0 indicates a false triple, while in open-world it indicates an unknown. These random variables are correlated with each other since the presence of certain triples can predict the presence/absence of other triples.
We can group all possible triples in a third-order tensor **Y **∈ {0,1} of dimensions N_e x N_e x N_r, see image below.

Each possible realisation of **Y **is a possible “world”, a certain combination of facts. We want to figure out which of these realisations is the most likely to be accurate given the limited number of triples that we know are true. To do so, we need to estimate the distribution P(Y) from a subset 𝒟 of N_d observed triples. **Y **can be incredibly large, so this task can be very complex. For example, Freebase had around 40M entities and 35k relations, giving 10¹⁹ possible triples.
However, only a small subset of these triples will actually be feasible, due to certain constraints. For example, we know that the relation marriedTo can only link two nodes that refer to people, so we can already exclude all the triples (e_i, r_marriedTo, e_j) where one or both of the entities are not people. Ideally, we’d like to find a way to easily identify and discard all these “impossible” triples.
Statistical properties of Knowledge Graphs
As already seen, KGs usually follow a set of deterministic rules, such as:
- Type constraints: the relation
marriedTocan only refer to a person - Transitivity: if A is located in B and B located in C, then A is located in C
They often also loosely follow a set of statistical patterns:
- Homophily (or “autocorrelation”): entities tend to be related to entities with similar characteristics
- Block structure: some entities can be grouped into “blocks” so that all members of one block have simila
#knowledge-graph #nlp #data-science #data #machine-learning #data analysis
