It is not easy to run Hive on Kubernetes. As long as I know, Tez which is a hive execution engine can be run just on YARN, not Kubernetes.
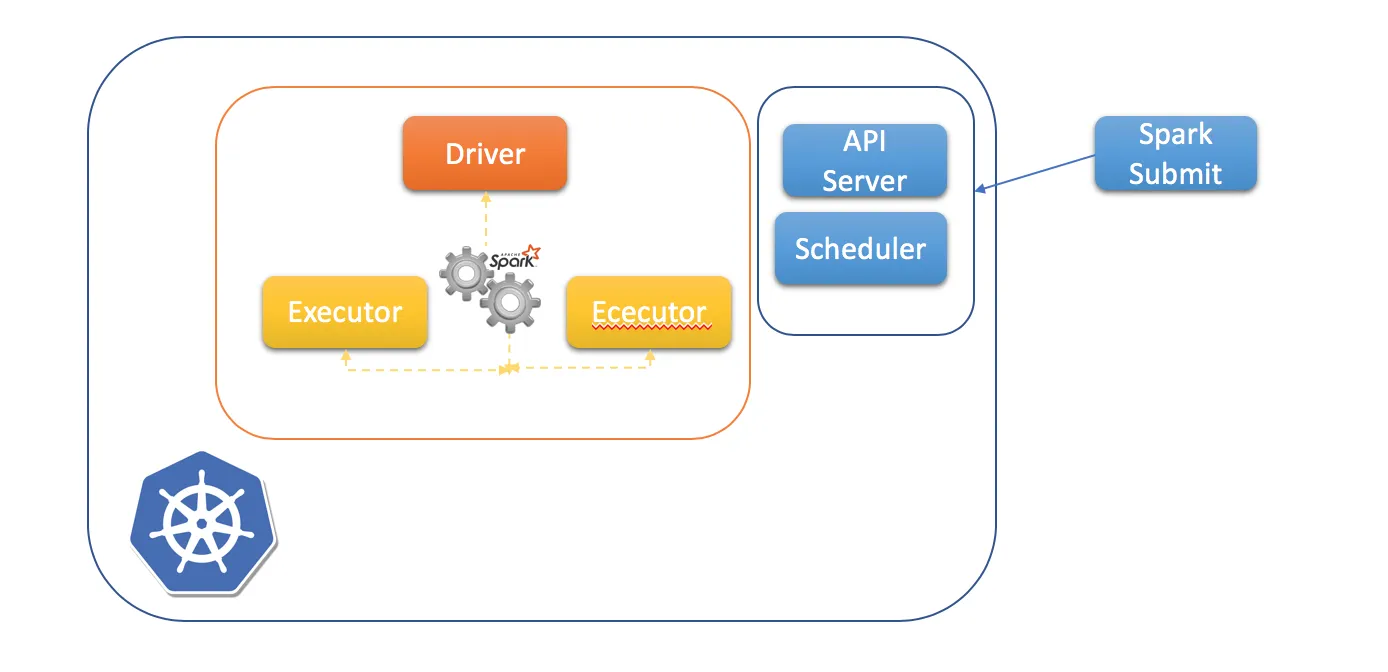
There is an alternative to run Hive on Kubernetes. Spark can be run on Kubernetes, and Spark Thrift Server compatible with Hive Server2 is a great candidate. That is, Spark will be run as hive execution engine.
I am going to talk about how to run Hive on Spark in kubernetes cluster .
All the codes mentioned here can be cloned from my github repo: https://github.com/mykidong/hive-on-spark-in-kubernetes
Assumed that S3 Bucket and NFS as Kubernetes Storage are available
Before running Hive on Kubernetes, your S3 Bucket and NFS as kubernetes storage should be available for your kubernetes cluster.
Your S3 bucket will be used to store the uploaded spark dependency jars, hive tables data, etc.
NFS Storage will be used to support PVC ReadWriteMany Access Mode which is needed to spark job.
If you have no such S3 bucket and NFS available, you can install them on your kubernetes cluster manually like me:
- MinIO Direct CSI: https://github.com/minio/direct-csi
- MinIO S3 Object Storage: https://github.com/minio/operator
- NFS: https://github.com/helm/charts/tree/master/stable/nfs-server-provisioner
#hive #kubernetes #spark #s3