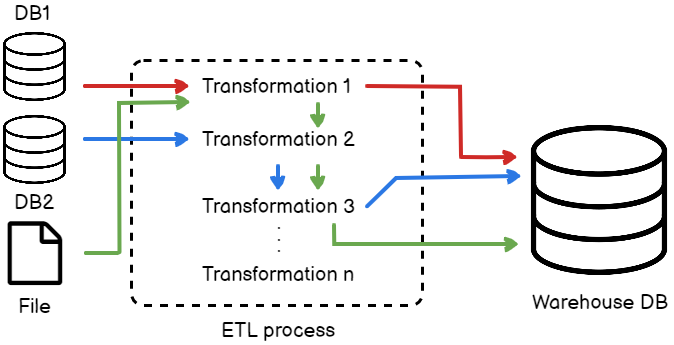
In this article, I am going to explain what Data Lineage in ETL is and how to implement the same. In this modern world, where companies are dealing with a humongous amount of data every day, there also lies a challenge to efficiently manage and monitor this data. There are systems that generate data every second and are being processed to a final reporting or monitoring tool for analysis. In order to process this data, we use a variety of ETL tools, which in turn makes the data transformation possible in a managed way.
While transforming the data in the ETL pipeline, it has to go through multiple steps of transformations in order to achieve the final result. For example, when the ETL receives the raw data from the source, there may be operations applied to it like filtering, sorting, merging, or splitting two columns, etc. There can also be aggregations or other calculations made on this raw data before finally moving into a data warehouse or preparing it for reporting. In order to be able to detect what the source of a particular record is, we need to implement something known as Data Lineage. It is a piece of simple metadata information that helps us detect gaps in the data processing pipeline and enables us to fix issues later.
Understanding Data Lineage
As it goes by the name, Data Lineage is a term that can be used for the following:
- It is used to identify the source of a single record in the data warehouse. This means there should be something unique in the records of the data warehouse, which will tell us about the source of the data and how it was transformed during the processing
- Simplify the process of moving data across multiple systems. When we move data across multiple systems for data processing, it might happen that a specific set of records were being missed out due to unknown reasons. In case we are not able to track down such missed records, it will lead us to incorrect figures being reported in the warehouse
- Makes the data movement process more transparent. Introducing a lineage key in the ETL process makes the documentation of the project a bit easier as we already know how the data has been transformed in order to come to a particular set
#etl #integration services (ssis) #data analysis