The Universal Approximation Theorem is, very literally, the theoretical foundation of why neural networks work. Put simply, it states that a neural network with one hidden layer containing a sufficient but finite number of neurons can approximate any continuous function to a reasonable accuracy, under certain conditions for activation functions (namely, that they must be sigmoid-like).
Formulated in 1989 by George Cybenko only for sigmoid activations and proven by Kurt Hornik in 1991 to apply to all activation functions (the architecture of the neural network, not the choice of function, was the driver behind performance), its discovery was a significant driver in spurring the excited development of neural networks into the plethora of applications in which they are used today.
Most importantly, however, the theorem is an eye-opening explanation of why neural networks appear to behave so intelligently. Understanding it is a key step in developing a strong and deep understanding of neural networks.
A Deeper Exploration
Any continuous function on a compact (bounded, closed) set can be approximated by a piecewise function. Take, for instance, the sine wave between -3 and 3, which can be very convincingly approximated with three functions — two quadratic and one linear.
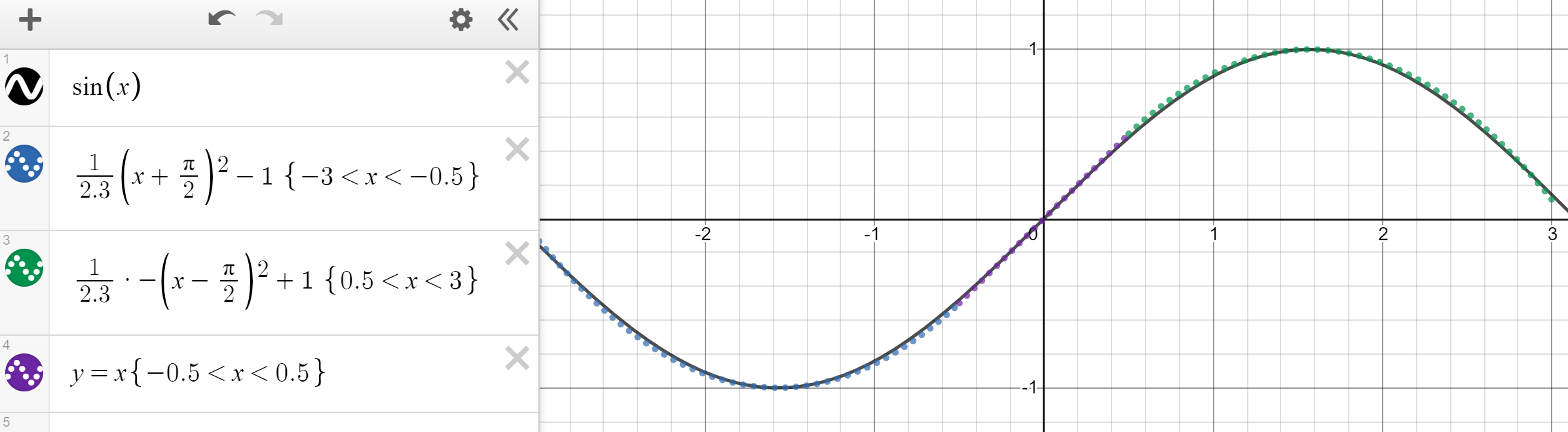
Graphed in Desmos.
Cybenko was more specific about this piecewise function, however, in that it could be constant, essentially consisting of several steps fitted to the function. With enough constant regions (‘steps’), one can reasonably estimate the function within the bounds it is given in.
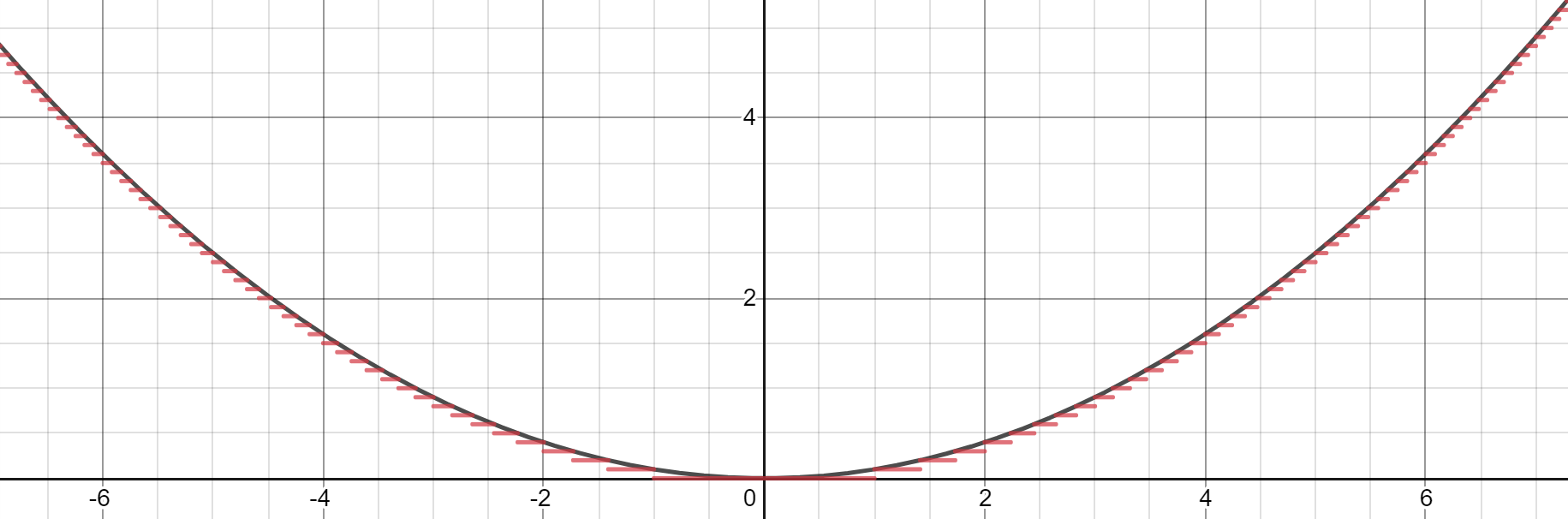
Graphed in Desmos.
Based on this approximation, one could construct a network by delegating each neuron to one ‘step’. Using the weights and biases as ‘gates’ to determine which an input falls and hence which neuron should be activated, a neural network with a sufficient number of neurons could estimate a function simply be divvying it up into several constant regions.
For inputs that fall in a neuron’s delegated section, by blowing the weight to huge values, the final value approaches 1 (when evaluated using the sigmoid function). If it does not fall into the section, moving the weight towards negative infinity will yield a final result near 0. Using the sigmoid function as a “processor” of sorts to determine the degree of presence of a neuron, any function can be approximated almost perfectly, given an 6abundance of neurons. In multi-dimensional space, Cybenko generalized this idea, each neuron ‘controlling’ a hypercube of space within a multidimensional function.
#machine-learning #ai #data-science #data-analysis #data analysis #data analysis
