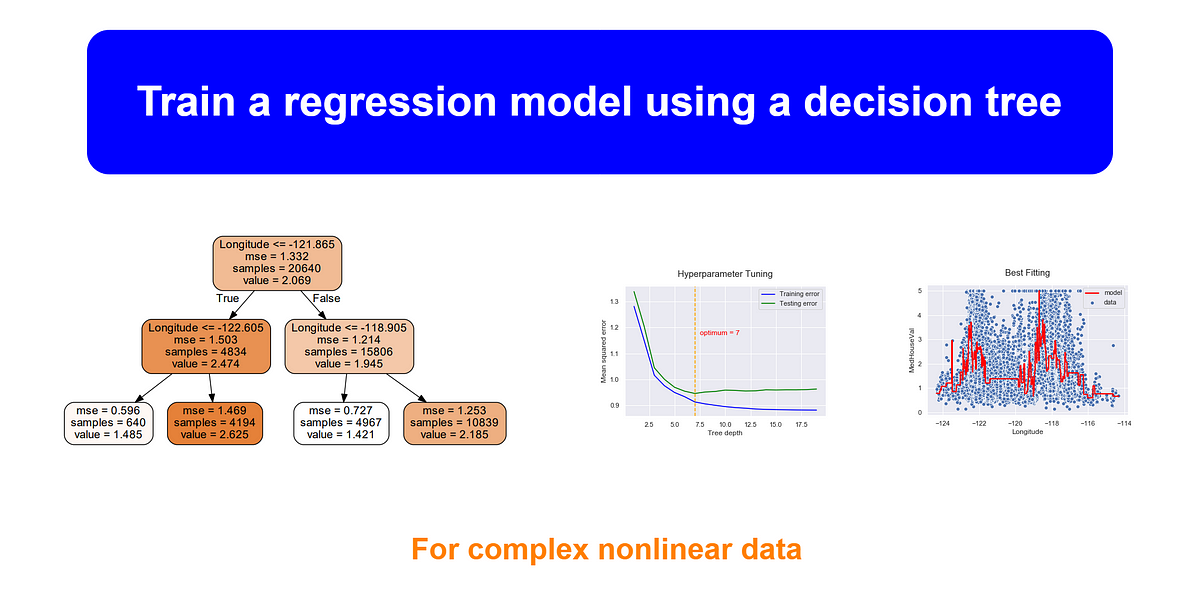
**Decision Trees **are a non-parametric supervised learning method, capable of finding complex nonlinear relationships in the data. They can perform both classification and regression tasks. But in this article, we only focus on decision trees with a regression task. For this, the equivalent Scikit-learn class is DecisionTreeRegressor.
We will start by discussing how to train, visualize and make predictions with Decision Trees for a regression task. We will also discuss how to regularize hyperparameters in decision trees. This will avoid the problem of overfitting. Finally, we will discuss some of the advantages and disadvantages of Decision Trees.
Code convention
We use the following code convention to import the necessary libraries and set the plot style.
%matplotlib inline
import numpy as np
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
sns.set()
Target audience
I assume that you have a basic understanding of the terminology used in the decision tree and how it works behind the scenes. In this tutorial, more emphasis is given for the model hyperparameter tuning techniques such as k-fold cross-validation.
#scikit-learn #machine-learning #decision-tree-regressor #data-science