When I started my machine learning journey, math was something that always intrigued me and still does.
I for one believe that libraries such as scikit learn have indeed done wonders for us when it comes to implementing the algorithms but without an understanding of the maths that goes into making the algorithm, we are bound to make mistakes on complicated problems.
In this article, I will be going over the math behind Gradient Descent and the derivation behind the Normal linear Equation and then implementing them both on a dataset to get my coefficients.
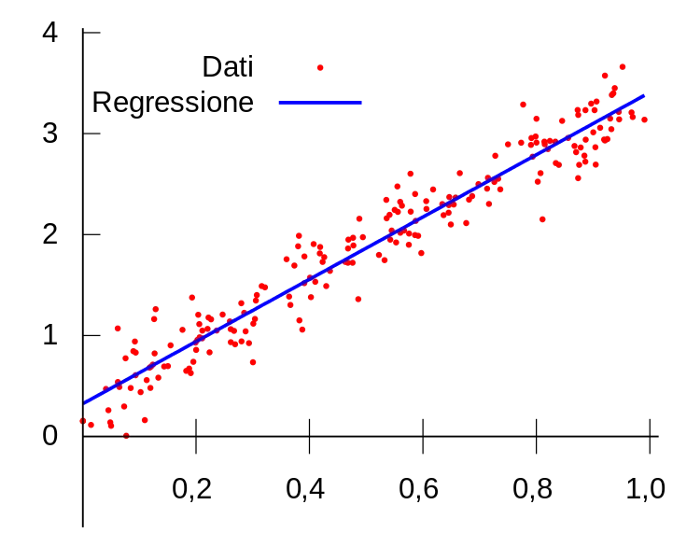
A Linear Regression model. Red dots are the true y values and the blue line is the model line
The Normal Equation
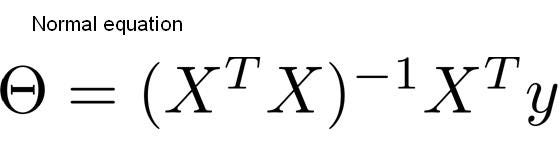
Looks pretty straight forward, no? When I was getting started with Linear Regression and trying to get an understanding of the different ways to calculate the coefficients, The Normal Equation was by far my most favorite method to find coefficients but where does this equation come from? Well, let us take a look.
The first thing we have to understand is that the Mean Squared Error or MSE for short is a metric that measures how well our model performs. The lower the MSE, the closer our predictions are to the actual values of y.
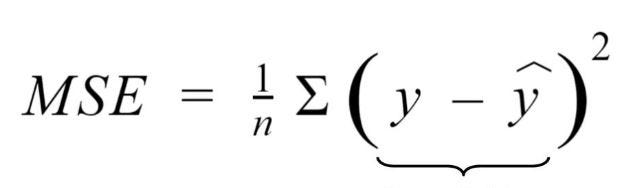
As can be seen in the equation, the lesser the difference between the actual and predicted values of y, the lower the MSE. And that is the goal, to have as low of an MSE as possible.
But can we use the MSE to find our coefficients? Yes, we can.
#gradient-descent #machine-learning #data-science #artificial-intelligence #towards-data-science