A single-layer perceptron is the basic unit of a neural network. A perceptron consists of input values, weights and a bias, a weighted sum and activation function.
In the last decade, we have witnessed an explosion in machine learning technology. From personalized social media feeds to algorithms that can remove objects from videos. Like a lot of other self-learners, I have decided it was my turn to get my feet wet in the world of AI. Recently, I decided to start my journey by taking a course on Udacity called, Deep Learning with PyTorch. Naturally, this article is inspired by the course and I highly recommend you check it out!
If you have taken the course, or read anything about neural networks one of the first concepts you will probably hear about is the perceptron. But what is a perceptron and why is it used? How does it work? What is the history behind it? In this post, we will briefly address each of these questions.
A little bit of history
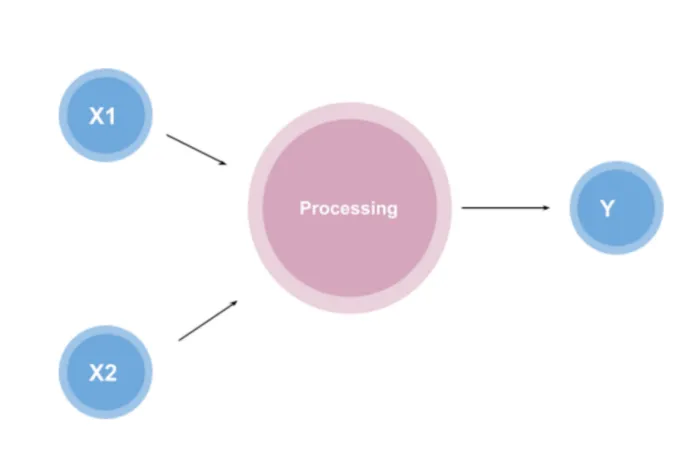
The perceptron was first introduced by American psychologist, Frank Rosenblatt in 1957 at Cornell Aeronautical Laboratory (here is a link to the original paper if you are interested). Rosenblatt was heavily inspired by the biological neuron and its ability to learn. Rosenblatt’s perceptron consists of one or more inputs, a processor, and only one output.
#machine-learning #neural-networks #deep-learning #perceptron #artificial-intelligence