How do we evaluate how well a machine learning classifier or test model performs? How do we know if a medical test is reliable enough to use in a clinical setting?
While a highly accurate coronavirus test may be useful where there is a higher incidence, why is it less informative in populations with lower rates of disease? This sounds counterintuitive and confusing, but does have applications for determining the utility of your own binary classifiers!
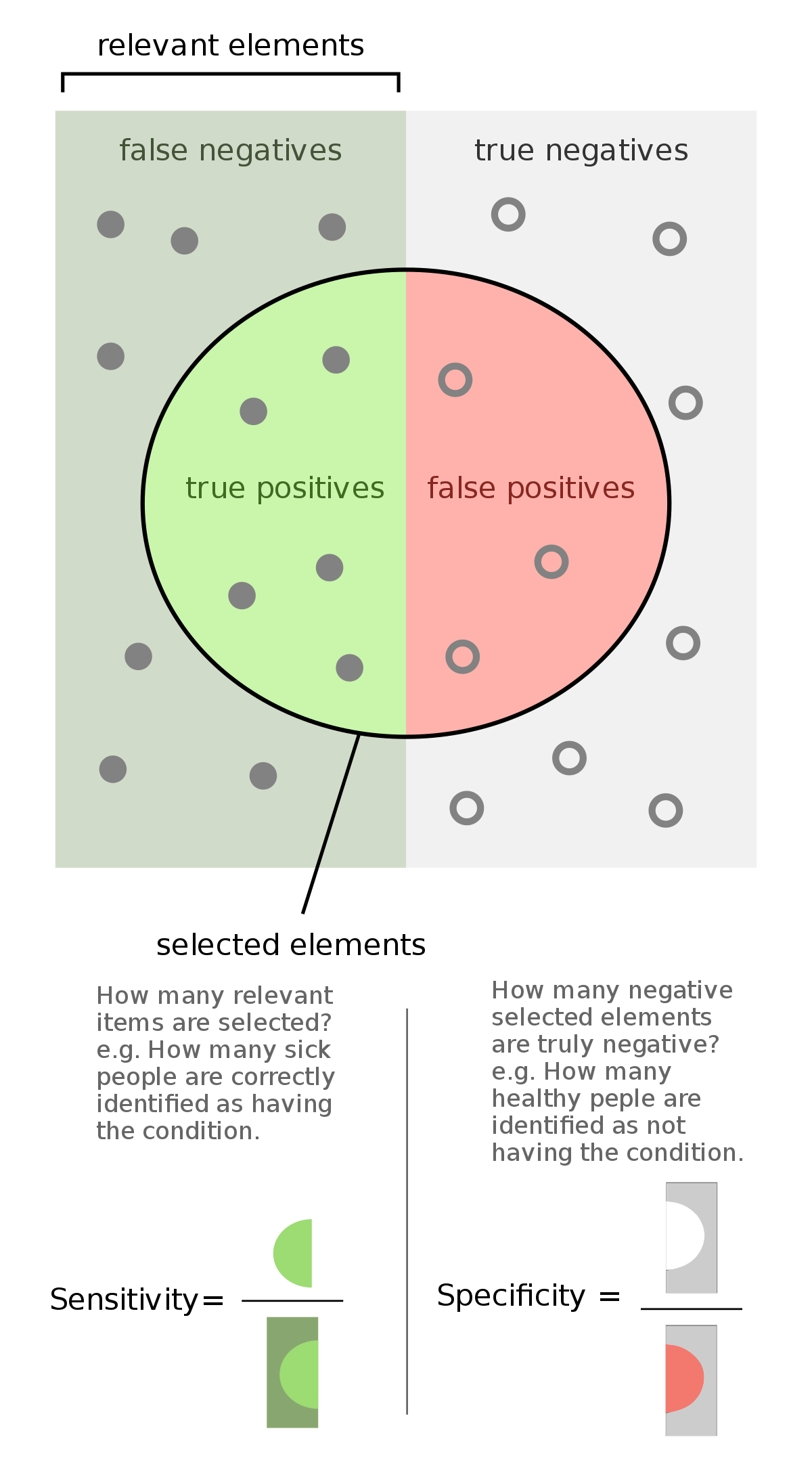
We define the validity of a test by measuring its specificity and sensitivity. Quite simply, we want to know how often the test identifies true positives and true negatives.
Our sensitivity describes how well our test catches all of our positive cases. Sensitivity is calculated by dividing the number of true-positive results by the total number of positives (which include false positives).
Our specificity describes how well our test classifies negative cases as negatives. Specificity is calculated by dividing the number of true-negative results by the total number of negatives (which include false negatives).
#medicine #machine-learning #statistics #coronavirus #bayesian-statistics