This article has two main motivating factors. Firstly, I work primarily in the NLP and Search Relevance space as a Data Scientist, and I have always wanted to share some of the findings that I find beneficial along the way. Secondly, as an avid reader, I have recently just finished a book called AI Superpowers: China, Silicon Valley and the New World Order, written by Kai-Fu Lee. I love the comparison between the two well respected countries, and the narrative as well as the AI descriptions in the book. Hence, it motivated the title of this article, as a form of comparison between the big tech in two dominating worlds. As a Malaysian Chinese, I feel proud :)
In general, the whole purpose of a search is to satisfy a user’s query, and hopefully, what is relevant is returned to the user. However, language is seemingly complex and there are bound to be ambiguities. In other words, language can also be semantic. Take for example, the word run can have different meanings under different contexts, i.e.the water is**_ running_, or he is running.Unfortunately, the ambiguity does not stop at English, and it also extends to other languages. Take for example, Chinese, i.e. 一朵漂亮的花,他今天花**了不少钱。Or Malay/Indonesia, i.e. timbang rasa, timbang keberatan badan. I guess you can never escape polysemy. Therefore, this also gives rise to a little something known technically as semantic search. Google released an open-source big boy NLP model, known as BERT in 2018, and in 2019, they have released an article to tell us about its integration into their proprietary search engine. All these Deep Learning fuss, huh :)
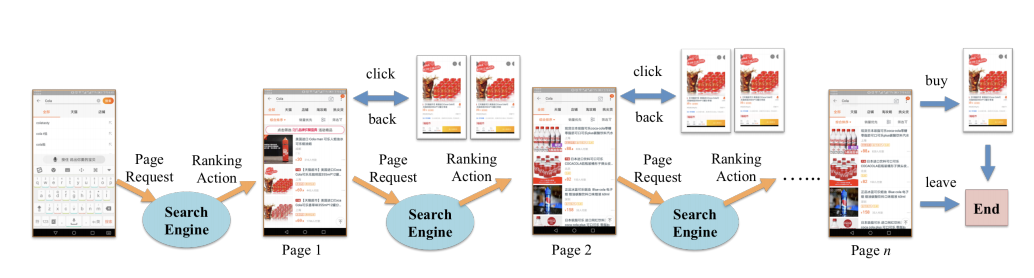
Let’s start with something simpler before playing with the big toys. Usually, we require that a user’s search query to be fast and responsive. Imagine having billions of documents, it is hard to use expensive models to rank them all at once. Hence, a very well-known architecture involves a three-step process, with the first being the retriever, and the second being a re-ranker, and lastly the question answering model.
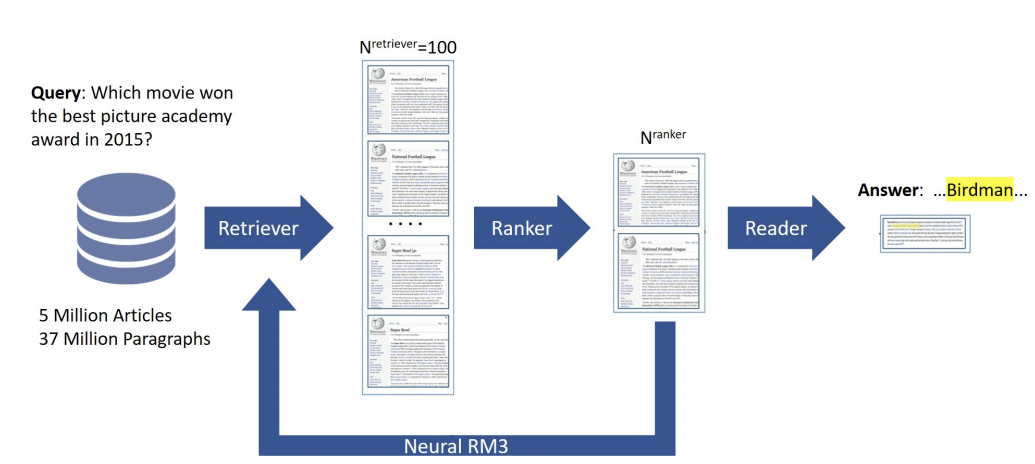
Domain-Specific Question Answering at Scale for Conversational Systems (2019)
Operating at the highest possible level, we will use a retriever to first quickly retrieve K documents, which will now be fed into a re-ranker, usually a more expensive algorithm, and finally to answer the query. For a retrieval engine, ElasticSearch is very commonly used. There are so many different ways we can build a re-ranker. For example, NLP word vectors such as FastText, Word2Vec, ELMo, BERT embeddings, or even models such as LambdaRank, LambdaMart, or RankNet that is built just for the purpose of ranking. BERT is also commonly used as a Question Answering model these days.
#nlp #usa #deep-learning #search-engines #china #deep learning