Web scraping has three simple steps:
- Step 1: Access the webpage
- Step 2: Locate and parse the items to be scraped
- Step 3: Save scraped items on a file
The top Python libraries for webscraping are: requests, selenium, beautiful soup, pandas and scrapy. Today**,** we will only cover the first four and save the fifth one, scrapy, for another post (it requires more documentation and is relatively complex). Our goal here is to quickly understand how the libraries work and to try them for ourselves.As a practice project, we will use this 20 dollar job post from Upwork:
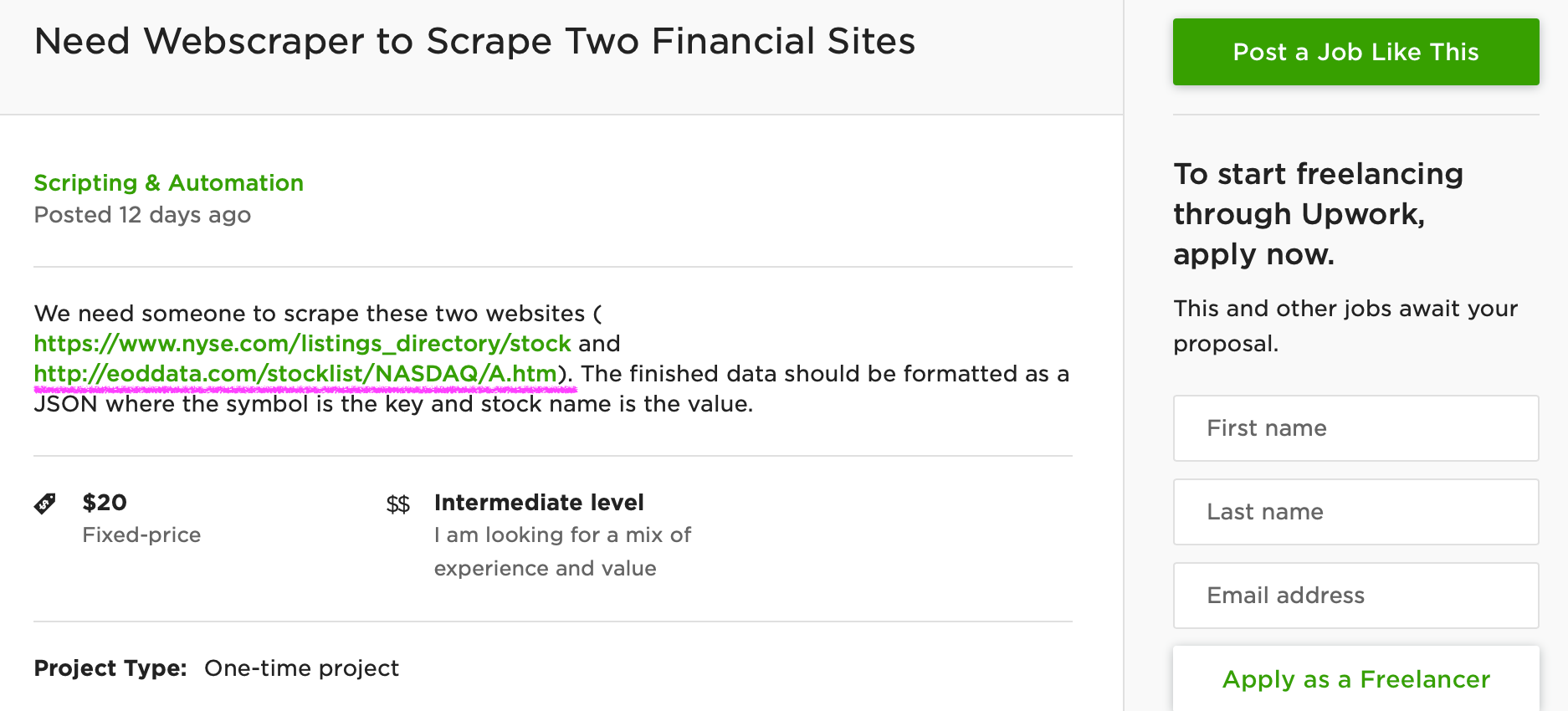
There are two links that the client wants to scrape and we will focus on the second one. It’s a webpage for publicly traded companies listed in NASDAQ:

According to the client, he wants to scrape the stock symbols and stock names listed on this webpage. Then he wants to save both data in one JSON file. There are hundreds of job posts like this on Upwork and this is a good example of how you can make money using Python.
Before we start, keep in mind that there are ethical and legal issues around web scraping. Be mindful of how the data you scrape will be used.
#python #web-development
