Achieve faster startup and a smaller memory footprint to run serverless functions on Kubernetes
A faster startup and smaller memory footprint always matter in Kubernetes due to the expense of running thousands of application pods and the cost savings of doing it with fewer worker nodes and other resources. Memory is more important than throughput on containerized microservices on Kubernetes because:
- It’s more expensive due to permanence (unlike CPU cycles)
- Microservices multiply the overhead cost
- One monolith application becomes N microservices (e.g., 20 microservices ≈ 20GB)
This significantly impacts serverless function development and the Java deployment model. This is because many enterprise developers chose alternatives such as Go, Python, and Nodejs to overcome the performance bottleneck—until now, thanks to Quarkus, a new Kubernetes-native Java stack. This article explains how to optimize Java performance to run serverless functions on Kubernetes using Quarkus.
Container-first design
Traditional frameworks in the Java ecosystem come at a cost in terms of the memory and startup time required to initialize those frameworks, including configuration processing, classpath scanning, class loading, annotation processing, and building a metamodel of the world, which the framework requires to operate. This is multiplied over and over for different frameworks.
Quarkus helps fix these Java performance issues by “shifting left” almost all of the overhead to the build phase. By doing code and framework analysis, bytecode transformation, and dynamic metamodel generation only once, at build time, you end up with a highly optimized runtime executable that starts up super fast and doesn’t require all the memory of a traditional startup because the work is done once, in the build phase.
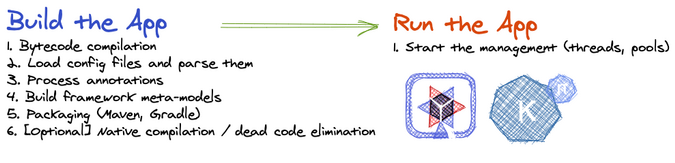
More importantly, Quarkus allows you to build a native executable file that provides performance advantages, including amazingly fast boot time and incredibly small resident set size (RSS) memory, for instant scale-up and high-density memory utilization compared to the traditional cloud-native Java stack.
#java #serverless #microservice #function
