In this article, I will cover the topic of Sentiment Analysis and how to implement a Deep Learning model that can recognize and classify human emotions in Netflix reviews.
One of the most important elements for businesses is being in touch with its customer base. It is vital for these firms to know exactly what consumers or clients think of new and established products or services, recent initiatives, and customer service offerings.
Sentiment analysis is one way to accomplish this necessary task.
Sentiment Analysis is a field of Natural Language Processing (NLP) that builds models that try to identify and classify attributes of the expression e.g.:
- Polarity: if the speaker expresses a positive or negative opinion,
- Subject: the thing that is being talked about,
- Opinion holder: the person, or entity that expresses the opinion.
In a world where we generate 2.5 quintillion bytes of data every day, sentiment analysis has become a key tool for making sense of that data. This has allowed companies to get key insights and automate all kind of processes.
Sentiment Analysis can help to automatically transform the unstructured information into structured data of public opinions about products, services, brands, politics or any other topic that people can express opinions about. This data can be very useful for commercial applications like marketing analysis, public relations, product reviews, net promoter scoring, product feedback, and customer service.
In the following, I will show you how to implement a Deep Learning model that can classify Netflix reviews as positive or negative. The model will take a whole review as an input (word after word) and provide percentage ratings for checking whether the review conveys a positive or negative sentiment.
I am using a dataset that contains roughly 5000 negative and 5000 positive reviews. Here are 5 samples reviews from the dataset, that at the end of the article will be classified by the model:
"The film is a hoot and is just as good if not better than much of what s on saturday morning tv, especially the pseudo educational stuff we all can’t stand.”
"The things this movie tries to get the audience to buy just won’t fly with most intelligent viewers.”
"Although life or something like it is very much in the mold of feel good movies, the cast and director stephen herek’s polished direction pour delightfully piquant wine from aged bottles.”
"This is the case of a pregnant premise being wasted by a script that takes few chances and manages to insult the intelligence of everyone in the audience.”
"One of the finest most humane and important holocaust movies ever made."
The deep learning model + all necessary data can be found in my GitHub repo.
Let’s begin with some theory.
1. Recurrent Neural Network
Recurrent Neural Networks (RNNs) are popular models that have shown great promise in many NLP tasks.
RNN’s make use of sequential information such as text. In a “traditional” feedforward neural network we assume that all inputs are independent of each other. But for many tasks that’s a very bad idea. A sentence, for example, has a clear grammatical structure and order, where each word depends on the previous word. If you want your neural network to learn the meaning (or sentiment in our case) the network must know which words came in which order.
RNNs are called recurrent because they perform the same task for every element of a sequence, with the output being dependent on the previous computations. Another way to think about RNNs is that they have a “memory” which captures information about what has been calculated so far. Here is what a typical RNN looks like:
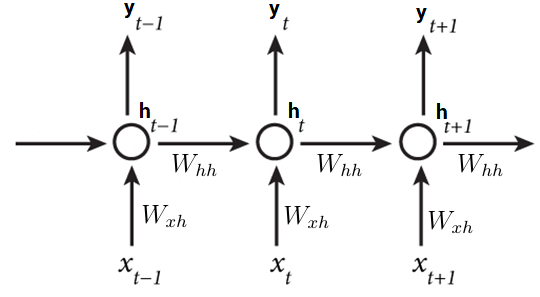
x(t-1), x(t), x(t+1) are sequential inputs that depend on each other (such as words in a sentence). y(t_1), y(t), ***y(t+1)***are the outputs. Unique for RNN is is the fact that the calculation of the current hidden state h(t) of the neurons for the input x(t) depends on the previous hidden state h(t-1) for the previous input x(t-1). Wxh and Whh are weight matrices that connect the input x(t) with the hidden layer h(t), and h(t) with h(t-1) respectively. This way we introduce a recurrence to the neural network which can be considered as a memory on the previous inputs. In theory, this way “vanilla” RNNs can make use of information in arbitrarily long sequences, but in practice, they are limited to looking back only a few steps.
This is where LSTMs come in handy.
1. 1 LSTMs
Long Short-Term Memory networks — usually just called “LSTMs” — are a special kind of RNN, capable of learning long-term dependencies. LSTMs don’t have a fundamentally different architecture from RNNs, but they incorporate additional components.
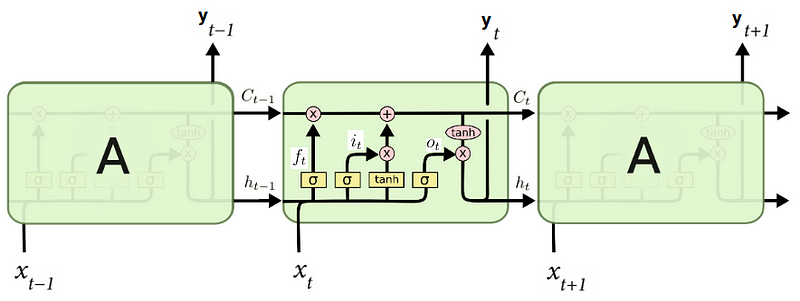
The key to LSTMs is the cell state C(t), the horizontal line running through the top of the diagram. A cell state is an additional way to store memory, besides just only using the hidden state h(t). However, C(t) makes it possible that LSTMs can work with much longer sequences in opposite to vanilla RNNs.
Furthermore, LSTMs have the ability to remove or add information to the cell state, carefully regulated by structures called gates. Gates are a way to optionally let information through. An LSTM has three of these gates, to protect and control the cell state.
- Polarity: if the speaker expresses a positive or negative opinion,
- Subject: the thing that is being talked about,
- Opinion holder: the person, or entity that expresses the opinion.
Behind each of these states are separate neural networks. As you can imagine this makes LSTMs quite complex. At this point, I won’t go much more into the detail about LSTMs.
2. Preprocessing
Before we can use the reviews as inputs for the recurrent neural network it is required to do some preprocessing on the data. Our main purpose here is to shrink the observation space.
2.1 Uniform Spelling of Words
Consider the words such as ”Something” and “something”. For us humans these words have the same meaning, the only difference between them is that the first word is capitalized, because it may be the first word in a sentence. But for the neural network, these words will have (at the beginning at least) a different meaning because of their different spelling. Only during training, the neural network may or may not learn to recognize that these words mean the same. Our aim is to prevent such misconceptions.
Because of this, the first step of preprocessing is to make all words lowercase words.
2.2 Removing Special Characters
Special characters such as . , ! ? ‘ etc. do not contribute to the sentiment of a review and hence can be removed.
End Result
Consider the following unprocessed review sample:
**_"Although life or something like it is very much in the mold of feel good movies, the cast and director stephen herek’s polished direction pour delightfully piquant wine from aged bottles.”_**
After we do the mentioned preprocessing steps the review sample look as follows:
**_"although life or something like it is very much in the mold of feel good movies the cast and director stephen hereks polished direction pour delightfully piquant wine from aged bottles”_**
The preprocessing is applied to every review in the dataset.
2.3 Word-To-Index
Another major step is to create a so-called Word-To-Index map, which assigns a unique integer value to each word in the dataset. The dataset I used in this project that contains all positive and negative reviews consists of 18339 unique words. Thus the word-to-index map has the same number of entries. This number is also called the vocabulary size.
The first and last entries in the word-to-index map that I have obtained look as follows:

This step of assigning a unique integer to words in the dataset is crucial because we can not feed in string data into a neural network. Instead, word-to-index allows us to use integers to represent whole sentences and reviews. Consider the following review:
**_"the things this movie tries to get the audience to buy just wont fly with most intelligent viewers”_**
Using word-to-index map, the review can be represented by an integer array, where each integer represents a word according to the map:
**_[0, 5094, 147, 81, 1269, 5, 532, 0, 1303, 5, 1835, 652, 236, 1101, 125, 188, 712, 855]_**
3. Word Embeddings
Of course, a neural network can neither take a string or a single integer value as input. Instead, we must use Word Embeddings.
Word Embeddings are a distributed representation for text that is perhaps one of the key breakthroughs for the impressive performance of deep learning methods on challenging NLP problems. Word Embeddings are in fact a class of techniques where individual words are represented by a real-valued vector, often with tens or hundreds of dimensions. Each word is mapped to one specific vector and the vector values are learned by the neural network.
This is contrasted to the thousands or millions of dimensions required for sparse word representations, such as a one-hot encoding. For instance, we can embed the words “although” and “life“ as 10-dimensional vectors:
**_although = [0.8 1.0 4.2 7.5 3.6]
life = [8.3 5.7 7.8 4.6 2.5 ]_**
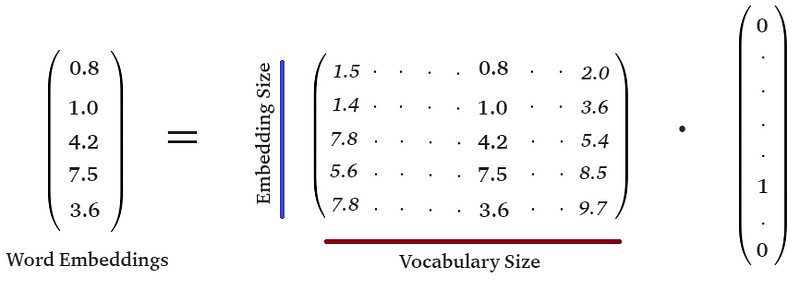
Each vector that represents a word in the dataset is obtained from a large matrix, called embedding-matrix. The number of rows of this matrix represents the dimensionality of the word embedding, the number of columns represents the vocabulary size or number of unique words in the dataset. Thus each column of this matrix represents an embedding vector for a unique word in the dataset.
How do we know which column represents which word? This is where we use the word-to-index map. Consider you want to get the embedding vector for the word “although”, according to the word-to-index map this word is represented by the number 2511. In the next step, it is necessary to create a one-hot-encoded vector of size 18339 (number of words in the dataset), where each entry is 0 except for the 2511th entry which has the value of 1.
By doing a dot-product between the embedding matrix and the one-hot-encoded vector we obtain the 2511th column of the matrix, which is the embedding vector for the word “although”.
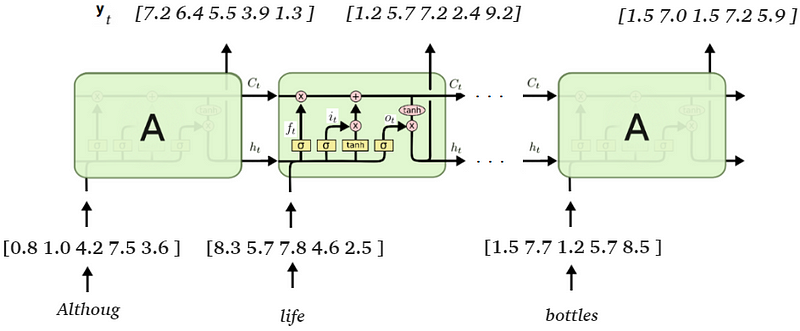
This way we can feed whole string-paragraphs or Netflix reviews into an LSTM. We just look up for each word the integer value in the word-to-index map, create the appropriate one-hot-encoded vector and perform a dot-product with the matrix. The review is then fed word by word (vector by vector) into the LSTM network.
4. Obtain the Sentiment of the Review
So far, you have seen how to preprocess the data and how to feed in the reviews in the LSTM network. Now, let’s discuss how we can finally get the sentiment of a given review.
For each time step t, the LSTM network receives an input vector x(t) which results in the output vector y(t). This process is repeated until x(n), n being the number of words in the review. Let’s say n=20 words. Until x(n) the LSTMnetwork produced y(n) output vectors.Each of these 20 vectors represents something, but not the sentiment we are looking for. Rather the vectors y are an encoded representation of features of the review that (according to the neural network) will be important in determining the sentiment.
y(8) represents the features the neural networks recognized for the first 8 words of the review. y(20), on the other hand, represents the features for the whole review. Although it is sufficient to use only the last output vector y(20) in practice, I have found that it leads to more accurate results if we use all vectors y(0) — y(20) for determining of the sentiment. This can be achieved by computing the mean value over all vectors. Let’s call this mean value vector y_mean.
Finally, the feature representation of the review that is encoded in y_mean can be used to classify the review into the categories of being positive or being negative. In order to do so, it is required to add a final classification layer, which is nothing else than the dot product between y_mean and another weight matrix W.
This process of sentiment analysis I just described is implemented in a deep learning model in my GitHub repo. You are welcome to check it out and try it for yourself. After the model is trained the can perform the sentiment analysis on yet unseen reviews:
Test Samples:
Review: "the film is a hoot and is just as good if not better than much of whats on saturday morning tv especially the pseudo educational stuff we all cant stand"
pos. sentiment: 0.96 %
neg. sentiment: 0.04 %
Review: "the things this movie tries to get the audience to buy just wont fly with most intelligent viewers"
pos. sentiment: 0.11 %
neg. sentiment: 0.89 %
Review: "although life or something like it is very much in the mold of feel good movies the cast and director stephen hereks polished direction pour delightfully piquant wine from aged bottles"
pos. sentiment: 0.97 %
neg. sentiment: 0.03 %
Review: "this is the case of a pregnant premise being wasted by a script that takes few chances and manages to insult the intelligence of everyone in the audience"
pos. sentiment: 0.02 %
neg. sentiment: 0.98 %
Special Announcement: There is an online-course coming!
We’re close to wrapping up our long-awaited course “Deep Learning for Predictive Analytics”. The course has an emphasis on building Deep Learning applications in the field of Predictive Analytics and making it work in a production environment. A skillset which is usually not covered by other online courses — but crucial for those who want to work in this field professionally.
If you are interested in getting notified when the course will be released or to receive further details, you can subscribe to the newsletter below — nice!
#deep-learning
