Claim actually close to 1% improvement on image net data set¹.
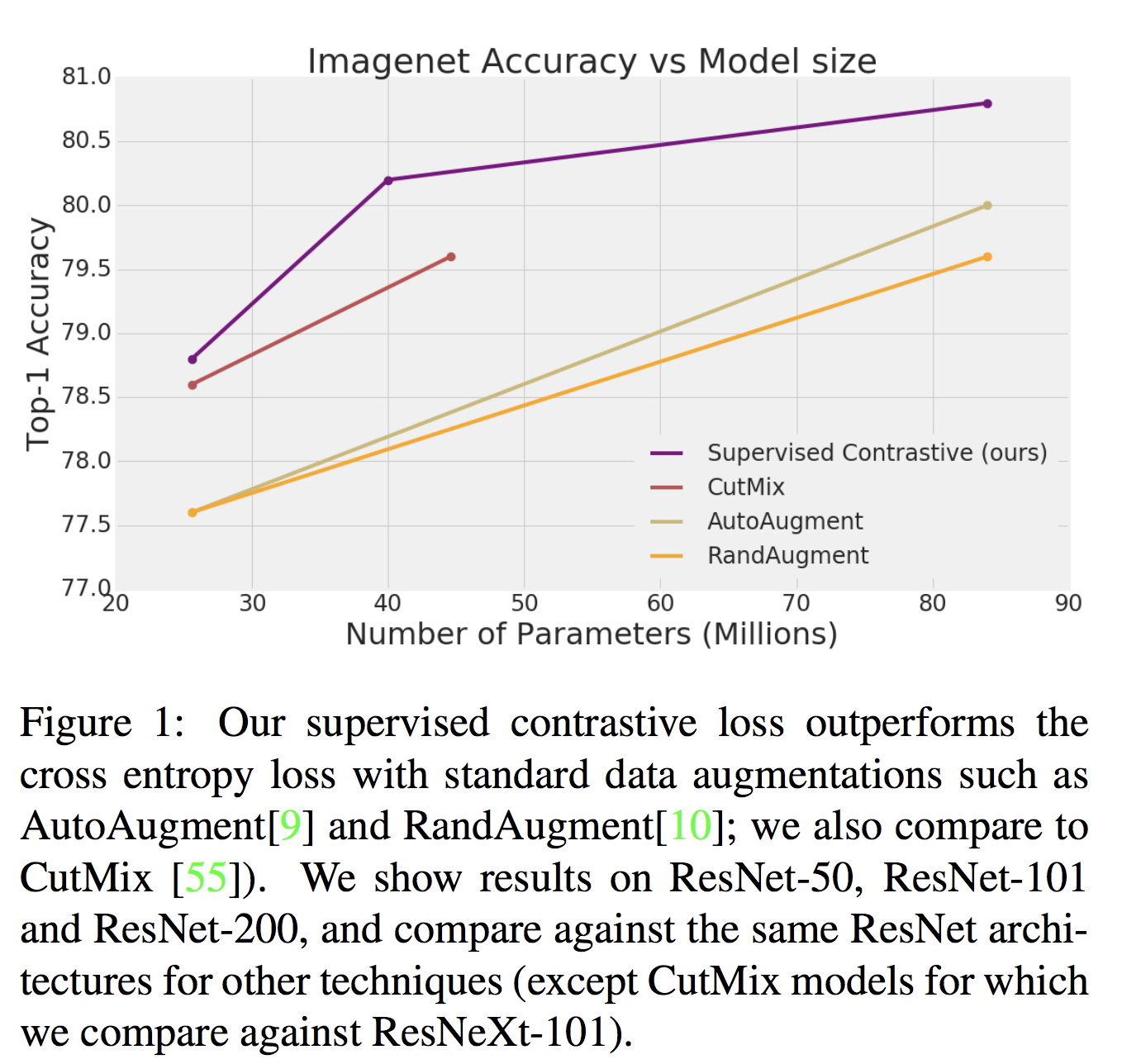
Classification accuracy from the paper¹
Architecture wise, its a very simple network resnet 50 having a 128-dimensional head. If you want you can add a few more layers as well.
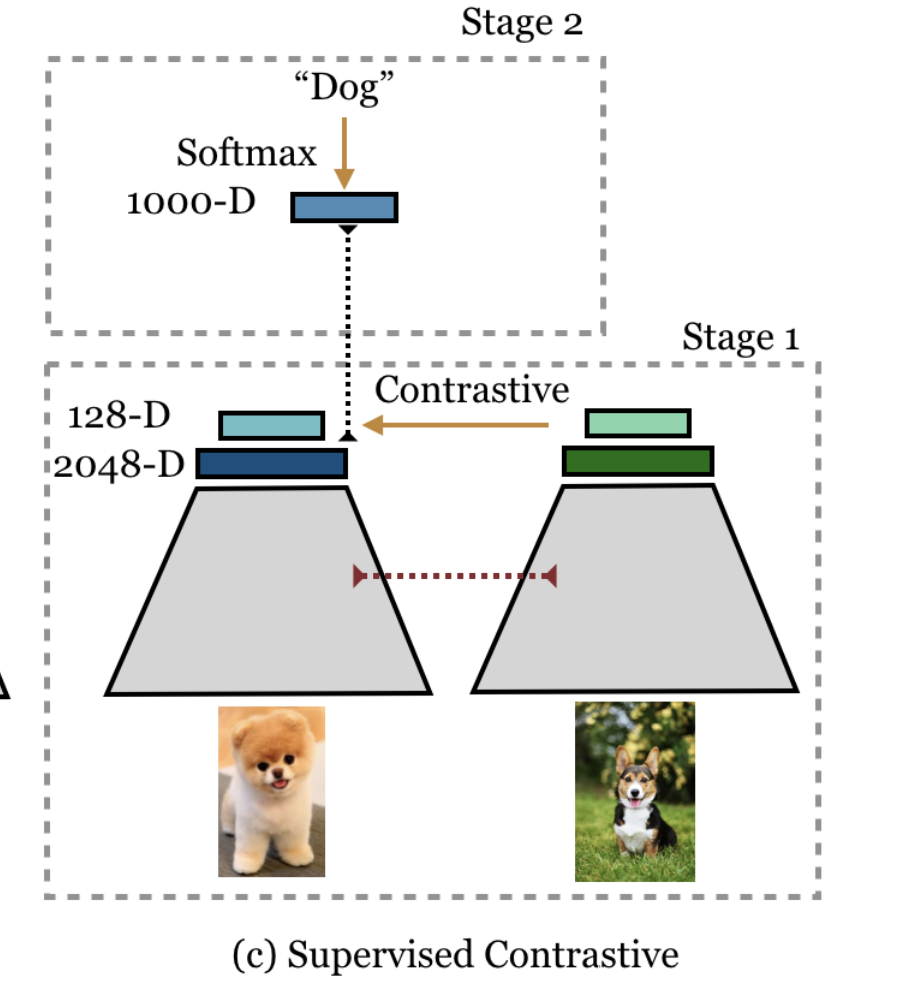
Architecture and training process from the paper¹
def forward(self, x):
feat = self.encoder(x) #normalizing the 128 vector is required Code self.encoder = resnet50() self.head = nn.Linear(2048, 128)
feat = F.normalize(self.head(feat), dim=1)
return feat
As shown in the figure training is done in two-stage.
- Train using contrastive loss (two variations)
- freeze the learned representations and then learn a classifier on a linear layer using a softmax loss. (From the paper)
The above is pretty self explanatory.
Loss, the main flavor of this paper is understanding the self supervised contrastive loss and supervised contrastive loss.
#programming #data-science
2.70 GEEK