Line-by-Line Tutorial Implementation of a Deep Convolutional Neural Network for the Clustering of Mushroom Photos
Supervised image classification with Deep Convolutional Neural Networks (DCNN) is nowadays an established process. With pre-trained template models plus fine-tuning optimization, very high accuracies can be attained for many meaningful applications — like this recent study on medical images, which attains 99.7% accuracy on prostate cancer diagnosis with the template Inception v3 model, pre-trained on images of everyday objects.
For unsupervised image machine learning, the current state of the art is far less settled.
Clustering is one form of unsupervised machine learning, wherein a collection of items — images in this case — are grouped according to some structure in the data collection per se. Images that end up in the same cluster should be more alike than images in different clusters.
Image data can be complex — varying backgrounds, multiple objects in view —so it is not obvious what it means for a pair of images to be more alike than another pair of images. Without a ground truth label, it is often unclear what makes one clustering method better than another.
On the one hand, unsupervised problems are therefore vaguer than the supervised ones. There is no given right answer to optimize for. On the other hand, it is from vague problems, hypothesis generation, problem discovery, tinkering, that the most interesting stuff emerge. Tools that afford new capacities in these areas of a data and analytics workflow are worth our time and effort.
I will describe the implementation of one recent method for image clustering (Local Aggregation by Zhuang et al. from 2019). This is one of many possible DCNN clustering techniques that have been published in recent years.
I use the PyTorch library to show how this method can be implemented and I provide several detailed code snippets throughout the text. Complete code is available in a repo.
Despite that image clustering methods are not readily available in standard libraries, as their supervised siblings are, PyTorch nonetheless enables a smooth implementation of what really is a very complex method. Hence I am able to explore, test and gently poke at the enigmatic problem of what DCNNs can do when applied to a clustering task.
My goal is to show how starting from a few concepts and equations, you can use PyTorch to arrive at something very concrete that can be run on a computer and guide further innovation and tinkering with respect to whatever task you have.
I will apply this to images of fungi. Why fungi? You’ll see later.
But First… Implementation of a VGG Auto-Encoder
Before I get to the clustering method, I will implement an Auto-Encoder (AE). AEs have a variety of applications, including dimensionality reduction, and are interesting in themselves. Their role in image clustering will become clear later.
Basic AEs are not that diffucult to implement with the PyTorch library (see this and this for two examples). I will implement the specific AE architecture that is part of the SegNet method, which builds on the VGG template convolutional network. VGG defines an architecture and was originally developed for supervised image classifications.
The architecture of the AE is illustrated below.
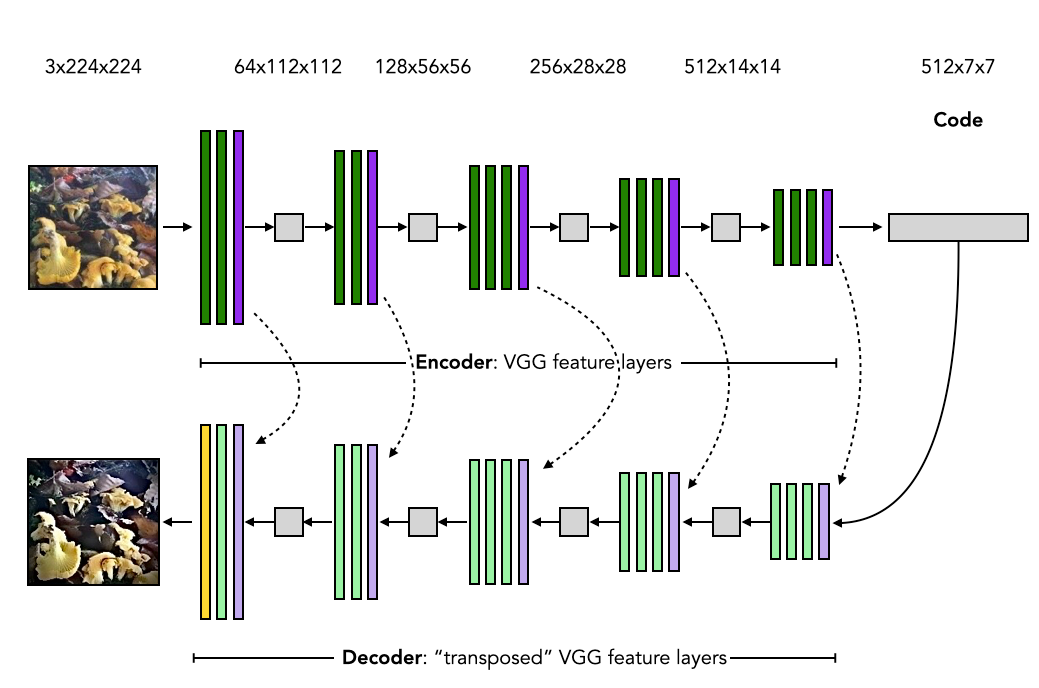
Image by Author
The steps of the image auto-encoding are:
- an input image (upper left) is processed by
- an Encoder, which is comprised of convolutional layers with normalization and ReLU activation (green) and max-pooling layers (purple), until
- a Code of lower dimension is obtained, which in turn is processed by
- a Decoder, which is comprised of transposed convolutional layers with normalization and ReLU activation (light green) and unpooling layers (light purple) plus a final convolution layer without normalization or activation (yellow), until
- an output image of identical dimension as the input is obtained.
Time to put this design into code.
I start with creating an Encoder module. The first lines, including the initialization method, look like:
import torch
from torch import nn
from torchvision import models
class EncoderVGG(nn.Module):
'''Encoder of image based on the architecture of VGG-16 with batch normalization.
Args:
pretrained_params (bool, optional): If the network should be populated with pre-trained VGG parameters.
Defaults to True.
'''
channels_in = 3
channels_code = 512
def __init__(self, pretrained_params=True):
super(EncoderVGG, self).__init__()
vgg = models.vgg16_bn(pretrained=pretrained_params)
del vgg.classifier
del vgg.avgpool
self.encoder = self._encodify_(vgg)
The architecture of the Encoder is the same as the feature extraction layers of the VGG-16 convolutional network. That part is therefore readily available in the PyTorch library, torchvision.models.vgg16_bn, see line 19 in the code snippet.
Unlike the canonical application of VGG, the Code is not fed into the classification layers. The last two layers vgg.classifier and vgg.avgpool are therefore discarded.
The layers of the encoder require one adjustment. In the unpooling layers of the Decoder, the pooling indices from the max-pooling layers of the Encoder must be available, which the dashed arrows represent in the previous image. The template version of VGG-16 does not generate these indices. The pooling layers can however be re-initialized to do so. That is what the _encodify method of the EncoderVGG module accomplishes.
def _encodify_(self, encoder):
'''Create list of modules for encoder based on the architecture in VGG template model.
In the encoder-decoder architecture, the unpooling operations in the decoder require pooling
indices from the corresponding pooling operation in the encoder. In VGG template, these indices
are not returned. Hence the need for this method to extent the pooling operations.
Args:
encoder : the template VGG model
Returns:
modules : the list of modules that define the encoder corresponding to the VGG model
'''
modules = nn.ModuleList()
for module in encoder.features:
if isinstance(module, nn.MaxPool2d):
module_add = nn.MaxPool2d(kernel_size=module.kernel_size,
stride=module.stride,
padding=module.padding,
return_indices=True)
modules.append(module_add)
else:
modules.append(module)
return modules
As this is a PyTorch Module (inherits from nn.Module ), a forward method is required to implement the forward pass of a mini-batch of image data through an instance of EncoderVGG :
def forward(self, x):
'''Execute the encoder on the image input
Args:
x (Tensor): image tensor
Returns:
x_code (Tensor): code tensor
pool_indices (list): Pool indices tensors in order of the pooling modules
'''
pool_indices = []
x_current = x
for module_encode in self.encoder:
output = module_encode(x_current)
## If the module is pooling, there are two outputs, the second the pool indices
if isinstance(output, tuple) and len(output) == 2:
x_current = output[0]
pool_indices.append(output[1])
else:
x_current = output
return x_current, pool_indices
The method executes each layer in the Encoder in sequence, and gathers the pooling indices as they are created. After execution of the Encoder module, the Code is returned along with an ordered collection of pooling indices.
Next the Decoder.
It is a “transposed” version of the VGG-16 network. I use scare quotes because the Decoder layers look a great deal like the Encoder in reverse, but strictly speaking it is not an inverse or transpose.
The initialization of the Decoder module is a touch thicker:
class DecoderVGG(nn.Module):
'''Decoder of code based on the architecture of VGG-16 with batch normalization.
Args:
encoder: The encoder instance of `EncoderVGG` that is to be inverted into a decoder
'''
channels_in = EncoderVGG.channels_code
channels_out = 3
def __init__(self, encoder):
super(DecoderVGG, self).__init__()
self.decoder = self._invert_(encoder)
def _invert_(self, encoder):
'''Invert the encoder in order to create the decoder as a (more or less) mirror image of the encoder
The decoder is comprised of two principal types: the 2D transpose convolution and the 2D unpooling. The 2D transpose
convolution is followed by batch normalization and activation. Therefore as the module list of the encoder
is iterated over in reverse, a convolution in encoder is turned into transposed convolution plus normalization
and activation, and a maxpooling in encoder is turned into unpooling.
Args:
encoder (ModuleList): the encoder
Returns:
decoder (ModuleList): the decoder obtained by "inversion" of encoder
'''
modules_transpose = []
for module in reversed(encoder):
if isinstance(module, nn.Conv2d):
kwargs = {'in_channels' : module.out_channels, 'out_channels' : module.in_channels,
'kernel_size' : module.kernel_size, 'stride' : module.stride,
'padding' : module.padding}
module_transpose = nn.ConvTranspose2d(**kwargs)
module_norm = nn.BatchNorm2d(module.in_channels)
module_act = nn.ReLU(inplace=True)
modules_transpose += [module_transpose, module_norm, module_act]
elif isinstance(module, nn.MaxPool2d):
kwargs = {'kernel_size' : module.kernel_size, 'stride' : module.stride,
'padding' : module.padding}
module_transpose = nn.MaxUnpool2d(**kwargs)
modules_transpose += [module_transpose]
## Discard the final normalization and activation, so final module is convolution with bias
modules_transpose = modules_transpose[:-2]
return nn.ModuleList(modules_transpose)
The _invert_ method iterates over the layers of the Encoder in reverse.
A convolution in the Encoder (green in the image) is replaced with the corresponding transposed convolution in the Decoder (light green in the image). The nn.ConvTranspose2d is the library module in PyTorch for this and it upsamples the data, rather than downsample, as the better-known convolution operation does. For further explanation see here.
#deep-learning #pytorch #python #data-science #developer
