Medical claims data is complicated, like much of the US healthcare system. But that just means that the opportunities available from leveraging this important dataset in useful ways are all the greater. This extended series of articles will help make sense of medical claims datasets for those new to using them — what the many fields mean, what information they hold, and what kinds of interesting questions you can answer using them and how to do that.
Where Does Medical Claims Data Come From
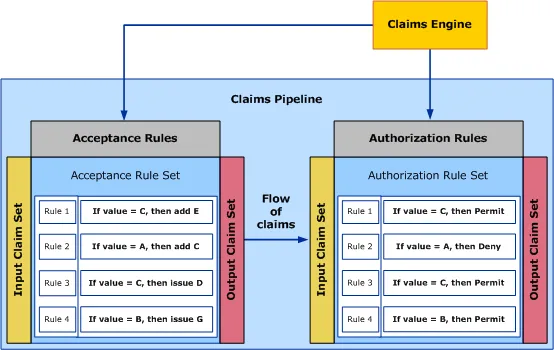
Medical claims datasets are the final step in a long process. It can be helpful to understand this process (we’ll call it the “claim submission pipeline”) for several reasons:
- Data Integrity: like all datasets, healthcare claims data contains errors and inaccuracies. Understanding where those errors may enter the data can help diagnose and remediate them. Additionally, sometimes data that looks erroneous can be an indicator of fraud or other malfeasance, and understanding the claims submission pipeline can help distinguish between intentional and unintentional data integrity gaps.
- **Understanding Data: **there are lots of conventions embedded in medical claims data, and there are many competing incentives that get sorted out using those conventions. Knowing these rules helps you understand why your data looks the way it does. Listing those “unwritten rules” out is part of why I’m writing this series.
- **Application: **the insights you gain from data will hopefully be implemented to better the healthcare system. The claim submission pipeline drives financial payment of providers (and costs for insurers/payers) so the claim submission pipeline can be a good summary view of the whole healthcare system (“follow the money” is good advice when analyzing medical claims data).
#healthcare #medical-claims-processing #medical-coding #data-science
1.15 GEEK