Knowledge on NoSQL databases seems to be an increasing requirement in data science applications, yet, the taxonomy is so diverse and problem-centered that it can be a challenge to grasp them. This post attempts to shed light on some of the concepts, often delving into each design’s specificities.
We start by briefly introducing NoSQL and the reasoning behind its appearance, followed by an analysis of each of the four members of the NoSQL family, their behavior, and main mechanisms, in addition to their advantages, disadvantages, and typical use cases.

The NoSQL database family and their representations.
What is NoSQL?
NoSQL (Not-only SQL) came into prominence in the mid-late-2000s as alternatives to traditional SQL. Instigated by the Web 2.0 industry, it allows for horizontal scaling, distributed databases, and flexible models (schema-less design). This paradigm shift means developers can focus more of their time in growing features and less time in database design. Typically, NoSQL solutions are presented as a cost-effective alternative to their SQL counterpart which relaxes RDBM’s rigidity.
Initially, NoSQL languages focused on key-value models effectively removing the need for SQL hence the name, NoSQL, as an abbreviation of “No SQL Support”. Over time the community realized that each tool filled a specific need, abandoning the “death to SQL” feeling over a coexistence-driven approach, with NoSQL seeing its meaning changing to “Not-only SQL”.
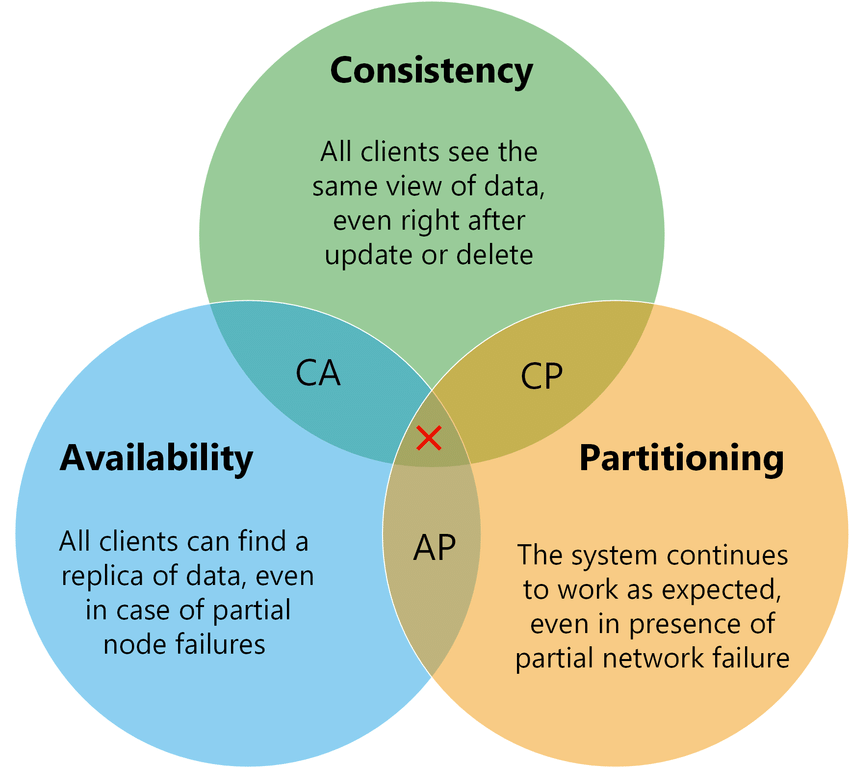
CAP Theorem Venn Diagram: the theorem states that no database paradigm is able to contain all three characteristics simultaneously.
The figure on the left represents the CAP theorem, which states that is is impossible for a distributed data store to simultaneously provide more than two of the three guarantees.
Whereas traditional RDBMs focus on the left side of the diagram, (Consistency and Availability, CA), NoSQL databases allow for horizontal partitioning and speed by sacrificing Consistency in favor of Availability and Partition Tolerance (AP).
Although some do have ACID compliance, most NoSQL databases revolve around what is known as “Eventual Consistency”, abiding by the BASE properties instead. Eventual consistency stipulates that eventually, all the nodes within the cluster will contain the same data version. Referred to as stale reads, it means that multiple queries may return different results, temporarily, a direct result of relaxing the Consistency guarantee.
So when to use NoSQL? Simply put: when ACID compliance is not a requirement, fast and cheap scalability is mandatory or your application falls into the Big Data category.
Before proceeding, keep in mind that NoSQL design is drastically different from that of its RDBMs counterparts, in the former, data tends to be denormalized and often repeated as storage is considered a cheap commodity when compared with access speed and availability. This paradigm combined with the no consistency guarantee is bound to generate temporary divergences.
Note #1: Several authors consider that NoSQL has clearly failed its goal, paving the way for the accommodation of NoSQL-like features in traditional SQL via NewSQL or Distributed SQL. But let us skip this topic for the time being.
Note #2: Some Document-Value NoSQL databases allow for ACID-like transactions as long as performed within the same collection, referred to as entity group transactions in Azure Table Storage; MongoDB added support for ACID-like distributed transactions in version 4.2.
Note #3: Some SQL databases are able to combine horizontal sharding/scaling and distributed queries using, for instance, the Citus extension for PostgresSQL.
Key-Value Databases
The simplest flavor of NoSQL databases revolves around the concept of associative arrays, in other words, it simply ties a given key to a record **of any type, **from a simple string or JSON to video files.
Key-value databases are organized into partitions or buckets, which can contain one or several entities, and each record is represented by a unique row key. Records in turn contain one or multiple fields. The concept of partition and row keys is one of the most critical aspects of NoSQL as it allows for logical partitions (defined by the partition key) to be moved around physical partitions (nodes) according to their workload. At the same time, its one of the major hindrances for newcomers: selecting the wrong key will spell disaster should your queries not take advantage of the selected key, and once you’ve selected it, there is no turning back.

AWS’ DynamoDB’s Storage Diagram
The choice of the partition key and row key is particularly challenging for key-value databases given you can only query via its key. What does this mean? In key-value terms, a JSON can be represented by a horizontal diagram with the id field representing the record’s key which is linked to the JSON’s values.

A dummy key-value association. Note how values do not abide by a fixed schema, varying from JSONs to strings within the same partition.
As long as you know the partition and record keys, CRUD operations are blazing fast. But what if you want to retrieve all cases where the “name” field equals “Michal”? Unlike in document databases, fields are not automatically indexed, which means that such a query will require going through every record to see if it contains the “name” field and it is equal to “Michal” — analogous to a full table scan in SQL. I hope this clarifies how important row key selection is, and why its important to know the system’s purpose beforehand. Of course, these systems are not designed to be field-queried, but we’re merely stating their limitations as a general-purpose database.
A typical key would be anything that can be considered to be unique, customerID, supplierID, sessionID, etc. Most developers opt for using composite keys, for instance, UserID.session would store session data; UserID.user in turn would represent the user’s cached information, simplifying the value for single fields instead of a dictionary-like structure, speeding up CRUD operations.
How about partition keys? In the beginning, we stated that partition keys allow for the system to move partitions around according to their workload. Hence the obvious and most direct consequence of improper partition key selection is creating _hot partitions — _groups of entities that are frequently accessed but can’t be distributed given they operate as a single unit (a single partition). With this in mind, a partition could be the UserID, whilst the keys would represent different user attributes, UserID.Name, UserID.Location, UserID.Height. If a physical partition contains several hot logical partitions (e.g. a set of users that request data frequently) the engine is able to distribute the logical partitions spreading the workload across different clusters. Without an appropriate partition key, the logical partition may be unary thus impossible to distribute.

Logical Partitions (LP) and their distribution between Physical Partitions (PP) according to their workload
Another important feature of key-value databases is the fact that their records can have a time to live (TTL), an automatic expiration date that can be controlled. This makes them strong candidates for session-driven storage.
Advantages
- Scalability
- Very fast read speed
- Simple and flexible data model
Disadvantages
- No relationship between entities
- No transaction-like behavior
- Only per-key queries are supported
- No support for retrieving multiple keys at once
- Slow multiple updates and collection scans
Vendors
- Redis
- Riak
- Memcached
- Azure Table Store
Use cases
- Web session cache
- Store user preferences
#sql #database #nosql #data-engineering #data-science
