Message Queues in Distributed Systems
Learn about monolithic and microservices architecture. Exploring the concept of synchronous, asynchronous, message queues, distributed systems and how to implement an asynchronous communication pattern in a microservices architecture.
From town criers to written letters and now real-time chat applications, humanity has always been on the lookout for innovative ways to communicate. And we can say the same about computers.
There's an even greater need to allow computers to communicate with the increasing adoption of distributed architecture. This also means that coordinating and managing communication between smaller services has gotten more complex.
But different ways of allowing the services in a distributed architecture to communicate have evolved over the years. We can put these different communication patterns into two broad categories: synchronous and asynchronous modes of communication.
But more relevant to this article would be exploring how we can use message queues to implement asynchronous communication in a distributed system. And, more importantly, how this can help us realize a more reliable and scalable architecture.
Synchronous, asynchronous, message queues, distributed systems — what are all these terms?
This article will cover what they are and, more importantly, explore the link between message queues and distributed systems. To begin, let’s look at the evolution from monoliths to distributed systems.
Note: for brevity’s sake, this article will interchangeably use the term distributed systems and microservices.
The Era of Monoliths
In the early days, software systems were relatively simple and small. As a result, they were developed and deployed as a unit that runs on a single process.
For example, let's say you were working on an application that does authentication, processes orders, and, eventually, handles payments. You would bundle all these components, and the application’s database, into a tightly-coupled unit that’s deployed as one application — a monolith.
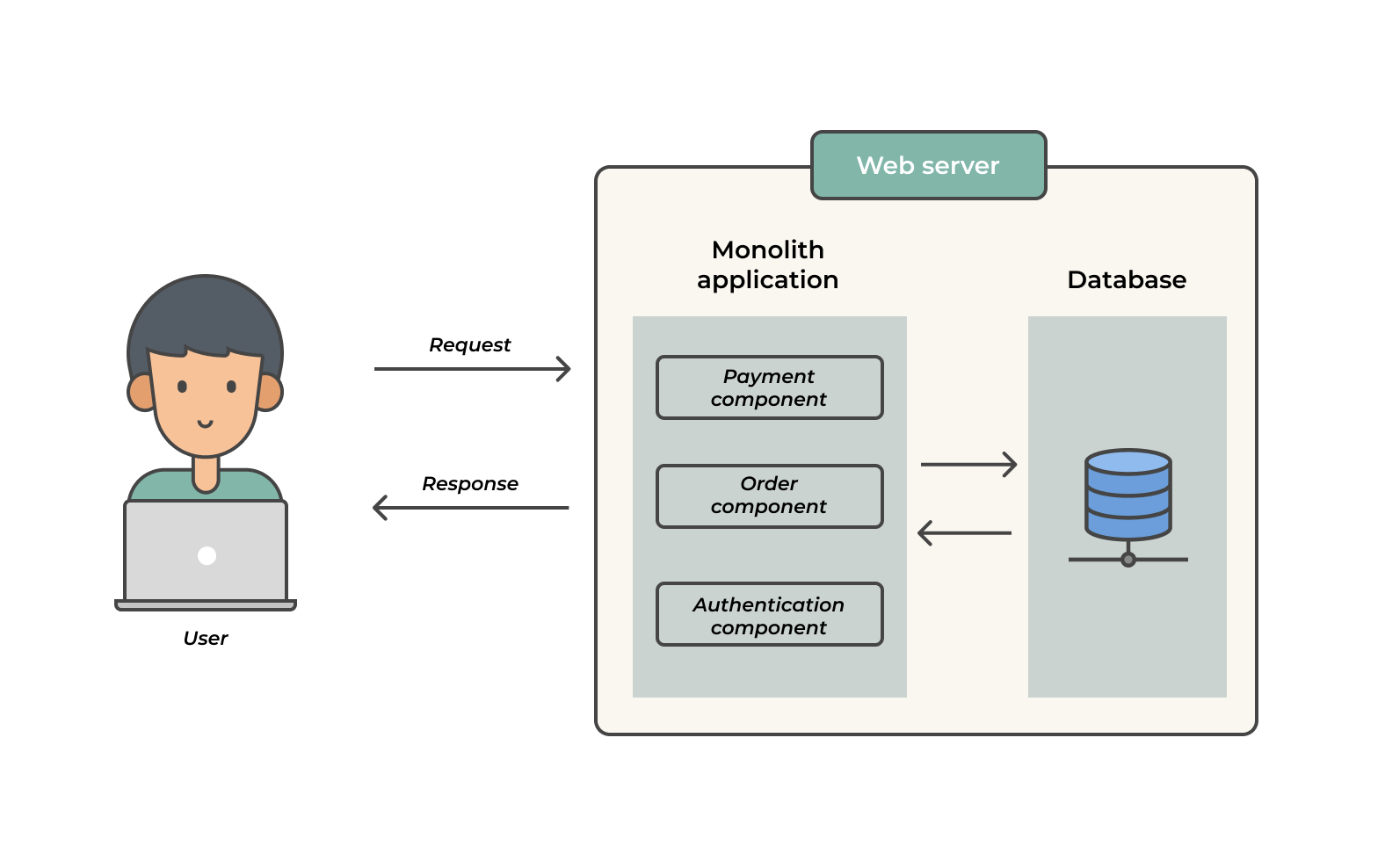
Illustration of a monolithic style of architecture
Over time, as more and more people embraced the internet, these monolith applications began to experience an explosion in the number of their users — a good thing, right? But this unmasked some limitations of the monolithic architecture.
Limitations of the monolithic architecture
First, with the increasing number of users, developers realized that having an application and its database hosted on the same machine wasn’t great. The database quickly became a resource hog, eating up the server’s memory and compute power.
To solve that, developers figured it’d be great if the application and its database could be hosted on different machines.

A monolithic application with a separate database
Even with that, they noticed that just moving the database to a separate machine wasn’t enough. As more users used an application, the demand for the host machine’s compute resources equally increased.
As users interacted with an application even more, developers realized that the host machine was being pushed to its limit. This negatively affected how quickly the monolith application could serve a user request. This latency problem got worse with increasing user traffic.
To fix that, they adopted a new design.
Enter the replicated monolithic architecture
In this design pattern, the same monolith application is duplicated on multiple servers — with all the servers hidden behind a load balancer. Each of the monoliths connected to the same database, and the load balancer routed requests to these instances optimally so as not to overwhelm any of the instances.
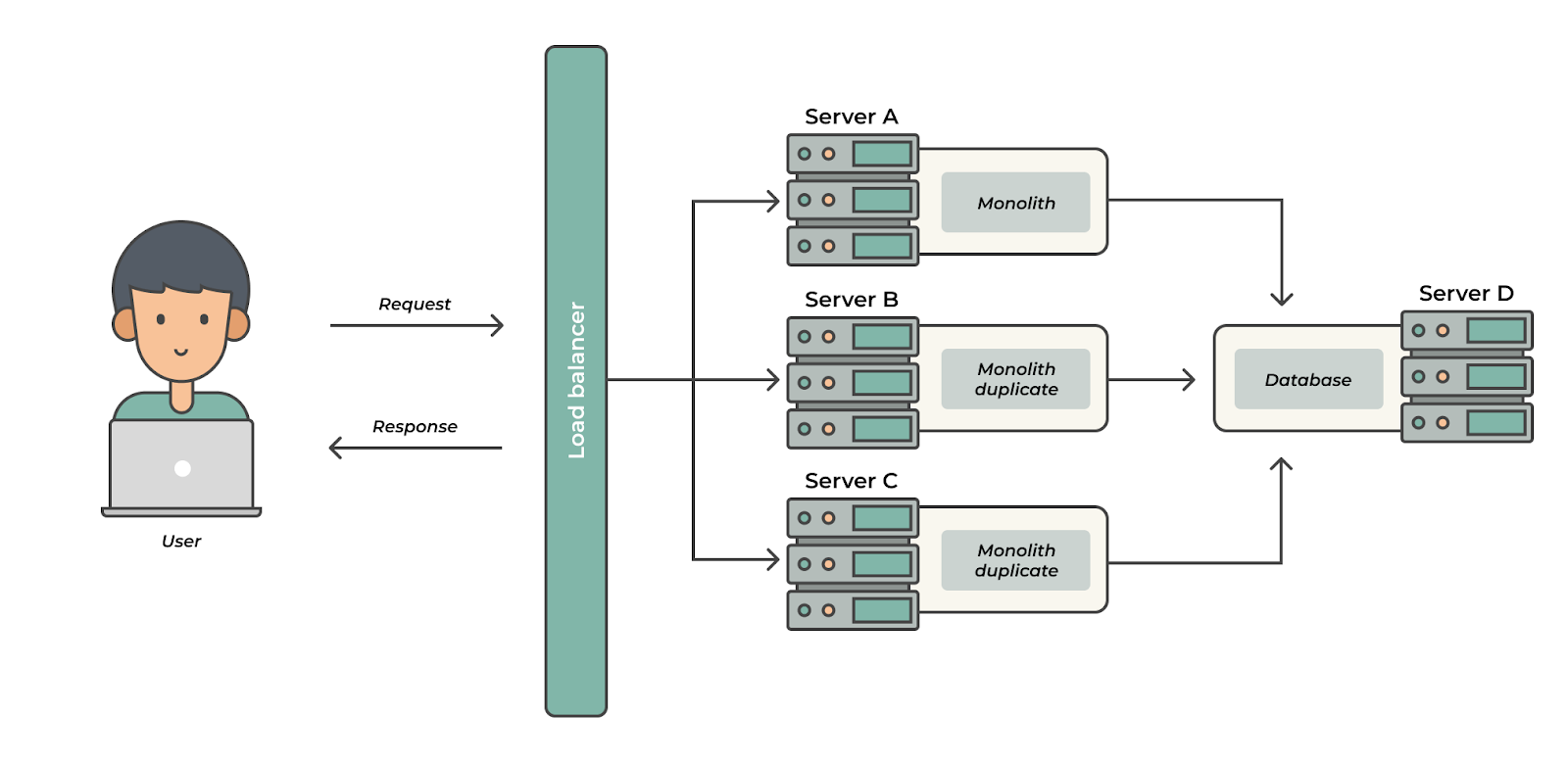
Replicated monolithic architecture
Replicating a monolith across multiple machines improved performance, but at what cost?
Making changes to a monolith running a replicated architecture became an undertaking that had all the makings of a nightmare. Let's review some of these downsides.
The pitfalls of the replicated monolithic architecture
Some of the limitations of the replicated monolith are, but not limited to:
1. Difficulty of upgrade or maintenance: For example, imagine you needed to update how your application was processing payments— maybe switch to a different payment processor. Updates like this would have to be reflected on all the replicated monoliths.
Essentially, all the copies would have to be taken down, updated, tested, and then redeployed. Overall, introducing changes or maintaining a monolith, in general, is way harder than it should be, because all the components are tightly coupled.
2. Inefficient horizontal scaling: Beyond maintenance and upgrades, yes, horizontally scaling a monolith by creating duplicate instances can improve performance – but how the scaling is done in this case is not optimal. Let’s see why…
Remember, a monolith is a bundle of different components that do different things but run as a single process. Going with our previous example, let's say our monolith has authentication, order processing, and payment components.
Now, in a monolith, it is common to have some components that do more work (receive and process user requests) than others. For example, in our case, not every user who logs in or signs up would make an order or pay for an order.
Even though, in our case, we are aware that it’s the authentication component that we need to allocate more resources to in order to scale, we can’t. This is because all the components are tied to each other and work as a single unit, so we can’t simply take out the authentication component.
That’s why, to scale a monolith horizontally, we’d have to create a duplicate instance of the entire application as opposed to scaling just the relevant components. This, in turn, leads to unnecessary pressure that could be avoided on the computing resources of the host machine.
A recap of the limitations of the monolithic architecture in general
Lastly, because all the components in a monolith are tightly coupled, if one component is faulty, this will directly affect the availability of the other parts. Clearly, with monoliths, we end up with fragile systems.
In summary, monolithic applications have the following limitations:
- It’s hard to introduce new changes to a monolith, as well as maintain and upgrade it over time
- Scaling a monolithic application is usually not optimal
- Monolithic applications are not resilient — if one part of the system fails, the entire system fails
The desire to create a software architecture that overcame the shortcomings of the monolith brought about the era of microservices.
What is a Microservice?
Well, burdened by the glaring limitations of the monolith, developers became analytical and went back to the big picture. They thought, what if we develop the tightly coupled components of the monolith as loosely coupled independent components?
That thinking gave rise to what we now call the microservice architecture. Unlike the monolithic architecture, the microservice architecture breaks down an application into smaller, self-reliant components called services.
Each service is developed and deployed separately. As a result, each service runs on a separate process.
Going with our previous example, our monolith will be broken down into three services: the authentication service, the order processing service, and the payment processing service, as shown in the image below.
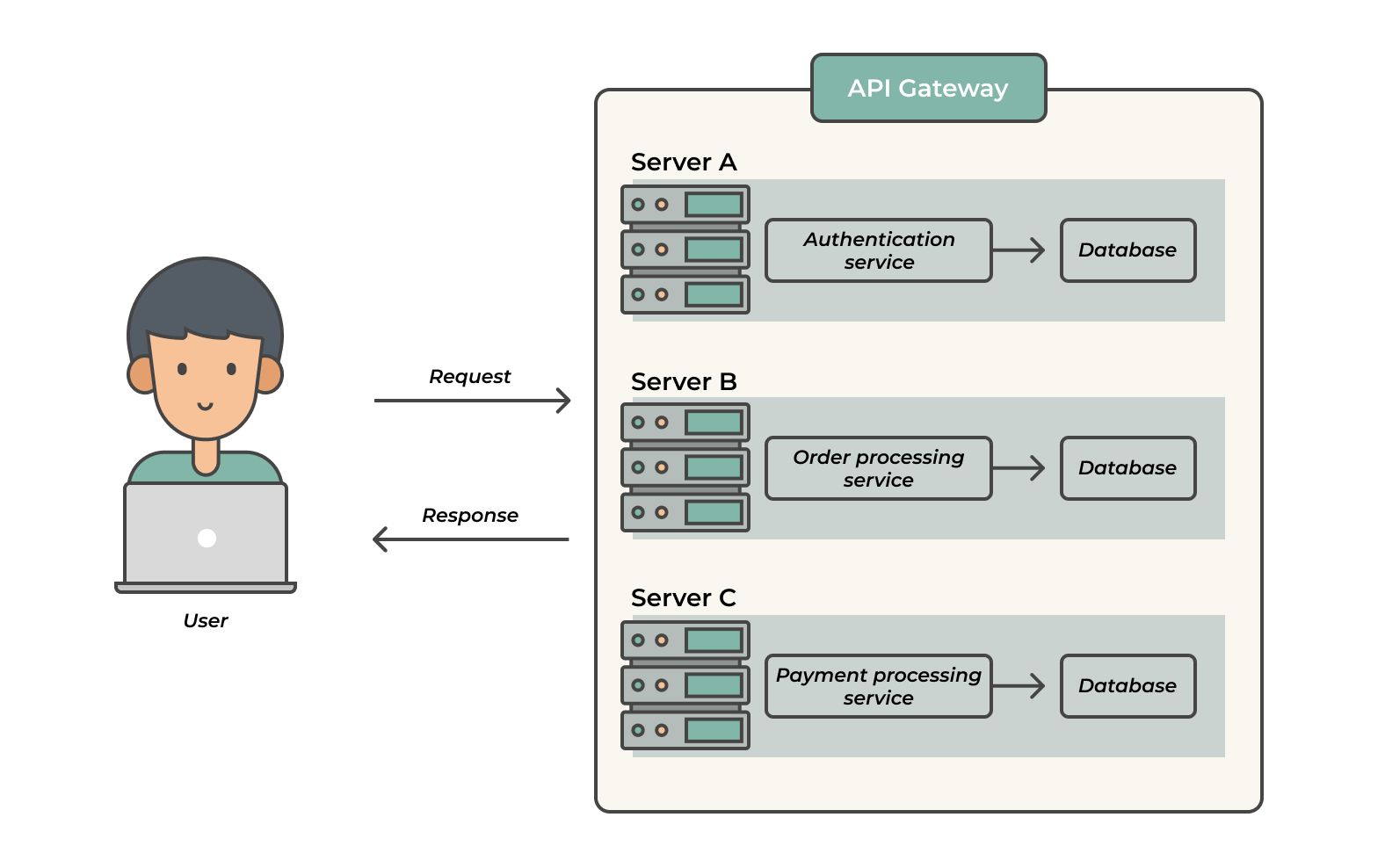
A microservice architecture
Even though these services are now developed as autonomous components, they all work together and communicate to achieve a common goal — ensuring that authenticated users can make purchases and pay.
But this brings up the question: how do these services communicate with each other?
Communication patterns in a microservice architecture
Broadly speaking, the services in the microservice architecture can be configured to communicate in one of two ways: synchronously or asynchronously.
To understand these two communication patterns, let’s pursue our previous example further — imagine a scenario where the order processing service needs to send the details of a new order to the payment processing service for payment to be processed.
Synchronous communication
Suppose the communication between the two services is synchronous. In that case, the order processing service will make an API call to the payment processing service and then wait for a response from that service before continuing its process.
As a result, the order processing service is blocked until it receives the response to its request. While the synchronous communication pattern is simple and direct, it has some major flaws when used in a microservice architecture.
One of the objectives of microservices is to create small independent services that remain operational even if one or more services experience downtime. This helps eliminate single points of failure.
However, the fact that the order processing service has to wait idly for a response from the payment service creates a level of interdependence that detracts from the intended autonomy of each service.
This is problematic because:
- If the payment processing service experiences an unexpected failure, the order processing service would be unable to fulfill its requests.
- If the order processing service encounters a sudden surge in traffic, it would also impact the payment service as it directly forwards its requests to the payment service.
- If the payment service takes too long to respond, the order processing service will also take very long to send a response to the end user.
How can these problems be fixed? Asynchronous communication to the rescue.
Asynchronous communication
Suppose the communication between the two services is asynchronous. In that case, the order processing service will initiate a request to the payment service and continue its execution without waiting for a response. Instead, it receives the response at a later time.
For asynchronous communication, multiple patterns are available such as publish/subscribe, message queueing, and event-driven architecture.
Here, we are interested in seeing how asynchronous communication can be implemented in microservices with message queues.
What is a Message Queue?
A message queue is fundamentally any technology that acts as a buffer of messages — it accepts messages and lines them up in the order they arrive. When these messages need to be processed, they are again taken out in the order they arrive.
A message is any data or instruction added to the message queue. Going with our example, a message would be the details of an order that could be added to the message queue and then later processed by the payment service.
The architecture of a message queue is simple — applications called the producers create messages and add them to the message queue. Other applications called the consumers pick up these messages and process them. Some examples of message queues are Apache Kafka, RabbitMQ, and LavinMQ, among others.
We can generally use a message queue to allow the services within a microservice to communicate asynchronously. But how, you might ask?
Async communication in distributed systems with message queues
To demonstrate how a message queue can foster asynchronous communication in a microservice architecture, let’s go to the example we’ve repeated in this article.
Recall we mentioned that the order processing service could forward the details of new orders to the payment processing service synchronously via an API call. We can replace the synchronous API with a message queue.
In essence, the message queue will sit between the two services. In this setup, the order processing service will act as the consumer that produces and adds messages to the message queue. The payment processing service will then act as the consumer that processes messages added to the queue.
The asynchronous communication here is inherent in the fact that when the producer (in this case, the order processing service) adds a message to the message queue, it continues with its execution without waiting for a response.
The consumer could then process messages from the message queue at its own pace and send a response to the producer or the end user at a later time.
This is a drastic shift from the synchronous approach. The genius of the asynchronous communication pattern with message queues lies in the fact that the services are separated and, as a result, made independent.
This is true because:
- If the payment processing service experiences an unexpected failure, the order processing service will continue to accept requests and place them in the queue as if nothing had occurred. The requests will always be present in the queue, waiting for the payment service to process them when it is back online. This leads to a more reliable architecture with no single point of failure
- The order processing service does not have to wait for a response from the consumer, the end users don’t also have to wait for long— this leads to improved performance and, by extension, a better user experience.
- If the order processing service experiences an increase in traffic, the payment service will not be affected as it only retrieves requests from the message queues at its own pace.
- This approach has the advantage of being simple to scale, as it allows for adding more queues or creating additional copies of the payment processing service to process more messages faster.
Wrapping Up
In this article, we learned about monolithic and microservices architecture. We also focused on exploring the concept of message queues and how to implement an asynchronous communication pattern in a microservices architecture.
Then we covered how adopting the asynchronous communication pattern as opposed to the synchronous approach could lead to increased performance, reliability, and ease of scale.
We merely managed to scratch the surface of message queues and what can be achieved with them— for example, being used in a distributed architecture isn’t their only use case.
This guide will go deeper and also walk you through building a demo application that adopts the microservice architecture with a message queue. That way, you get to see firsthand how to use a message queue in a distributed architecture.
Source: https://www.freecodecamp.org
#microservices #monolithic
