It may be a requirement of your business to move a good amount of data periodically from one public cloud to another. More specifically, you may face mandates requiring a multi-cloud solution. This article covers one approach to automate data replication from AWS S3 Bucket to Microsoft Azure Blob Storage container using Amazon S3 Inventory, Amazon S3 Batch Operations, Fargate, and AzCopy.
Scenario
Your company produces new CSV files on-premises every day with a total size of around 100GB after compression. All files have a size of 1–2 GB and need to be uploaded to Amazon S3 every night in a fixed time window between 3 am, and 5 am. Your business has decided to copy those CSV files from S3 to Microsoft Azure Storage after all files uploaded to S3. You have to find an easy and fast way to automate the data replication workflow.
To accomplish this task, we can build a data pipeline to copy data periodically from S3 to Azure Storage using AWS Data Wrangler, Amazon S3 Inventory, Amazon S3 Batch Operations, Athena, Fargate, and AzCopy.
The diagram below represents the high-level architecture of the pipeline solution:
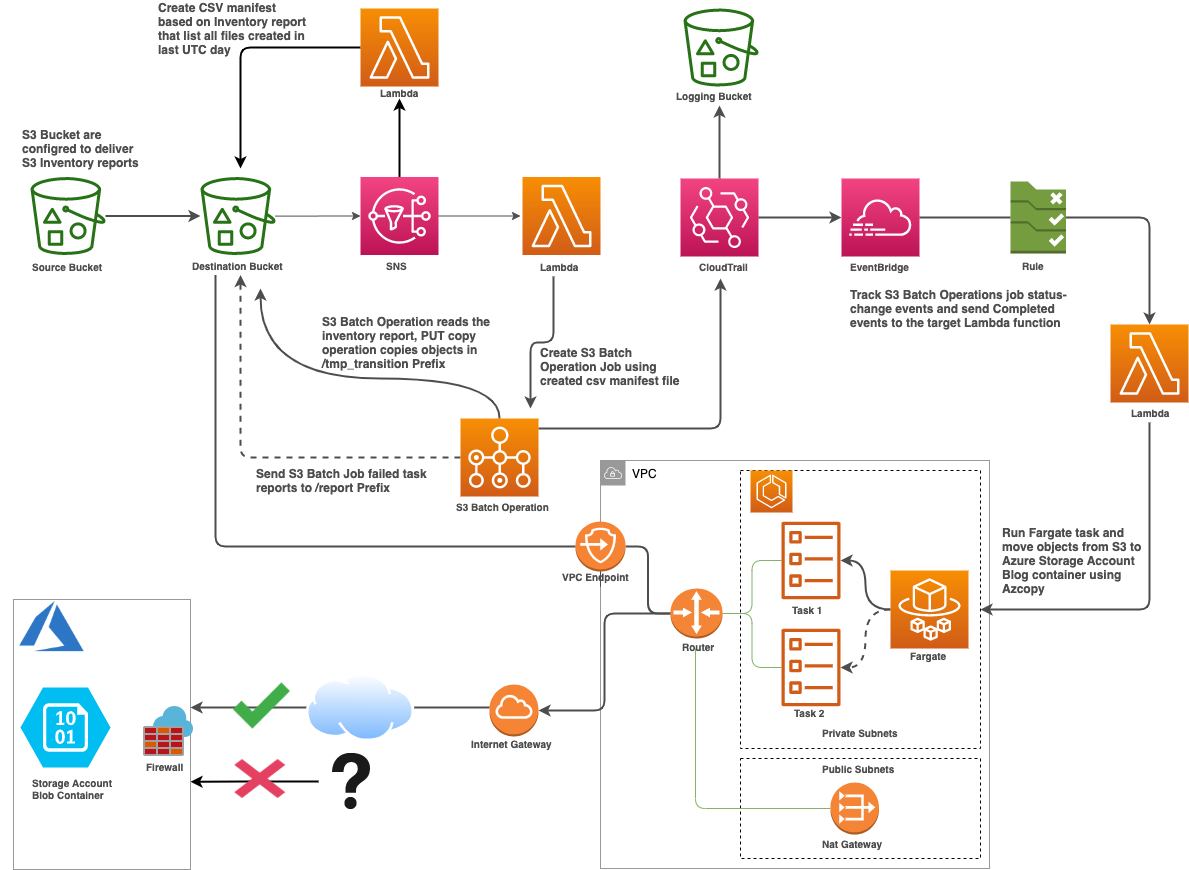
Architecture diagram by Yi Ai
What we’ll cover:
- Create a VPC with private and public subnets, S3 endpoints, and NAT gateway.
- Create an Azure Storage account and blob container, generate a SAS token, then add a firewall rule to allow traffic from AWS VPC to Azure Storage.
- Configure daily S3 Inventory Reports on the S3 bucket.
- Use Athena to filter only the new objects from S3 inventory reports and export those objects’ bucket names & object keys to a CSV manifest file.
- Use exported CSV manifest file to create an S3 Batch Operations PUT copy Job that copies objects to a destination S3 bucket with lifecycle policy expiration rule configured.
- Setup an Eventbridge rule, invoke lambda function to run Fargate task that copies all objects with the same prefix in destination bucket to Azure Storage container.
#azure #data-wranger #athena #aws #data-science
