Some facts just mess up in our minds and then it gets hard to recall what’s what. I had a similar experience with Bias & Variance, in terms of recalling the difference between the two. And the fact that you are here suggests that you too are muddled by the terms.
So let’s understand what Bias and Variance are, what Bias-Variance Trade-off is, and how they play an inevitable role in Machine Learning.
The Bias
Let me ask you a question. Why do humans get biased when they do? Or what motivates them to show some bias every now and then?
I’m sure you had a good answer or many good answers. But to summarise them all, the most fundamental reason that we see bias around us is —_ ease of mind._
Being humans, it’s easy to incline our thoughts and favors towards something we like, we admire, or something we think is right, without bending our thoughts much.
For most of our life’s decisions, we don’t want to put our brains into analyzing each and every scenario. Now one might be investigative, meticulous, or quite systematic while doing things that are important and consequential, but for the most part, we are too lazy to do that.
But how this human intuition of being biased is related to Machine Learning? Let’s understand how.
Consider the figure below.
One could easily guess that this figure represents Simple Linear Regression, which is an _inflexible _model that assumes a linear relationship between input and output variables. This assumption, approximation, and restriction introduce _bias _to this model.
Hence bias refers to the error which is observed while approximating a complex problem using a simple (or restrictive) model.
This analogy between humans and machines could be a great way to understand that inflexibility brings bias.
Observe the figure below. The plots represent two different models that were used to fit the same data. Which one do you think will result in higher bias?
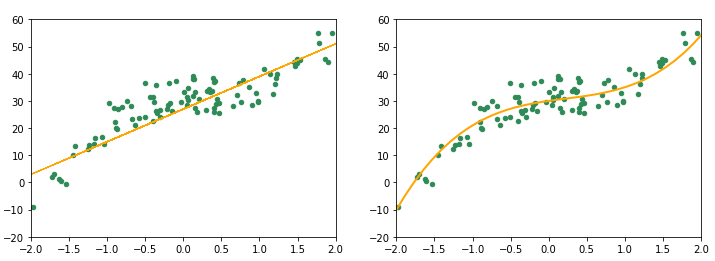
The plot on the right is quite more flexible than the one on the left. It fits more smoothly with the data. On the other hand, the plot on the left represents a poorly fitted model, which assumes a linear relationship in data. This poor-fitting due to high bias is also known as underfitting. Underfitting results in poor performance and low accuracies and can be rectified if needed by using more flexible models.
Let’s summarise the key points about bias:
- Bias is introduced when restrictive (inflexible) models are used to solve complex problems
- As the flexibility of a model increases, the bias starts decreasing for training data.
- Bias can cause underfitting, which further leads to poor performance and predictions.
So how can we get rid of this bias? We can build a more flexible model to fit our data and remove underfitting.
So should we keep building more complex models until we reduce the error to its minimum? Let’s try and do that with some randomly generated data.
#machine-learning #bias #variance #data-science #data analysis