In this post, it will be about deploying a scikit-learn machine learning model using serverless services because it allows us to let the model deploy and only pay for the time it will be used unlike using a server.
Requirements
Before going further, you will need to have the following tool installed on your environment:
- An AWS account
- AWS CLI
- A Github account
- Python 3.7 or greater
- a scikit-learn model trained and serialized with its preprocessing step (using pickle)
Understanding the solution’s architecture
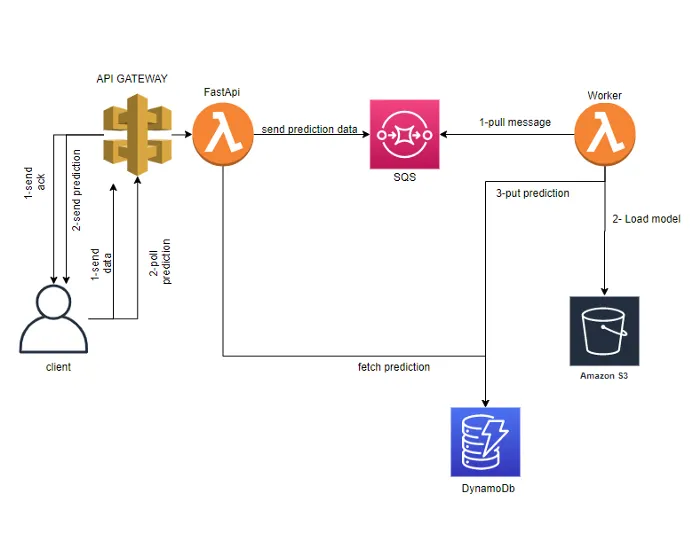
First, let’s see from a global point of view the application we are going to deploy.
Lots of tutorials on how to deploy a model in production directly integrates the serialized model into the API. This way of proceeding has the disadvantage of making the API coupled to the model. Another way to do this is to delegate the prediction load to workers. This is what the schema above shows.
The machine learning model is stored in an s3 bucket. It is loaded by the worker which is a Lambda function when a message containing prediction data is put in the SQS queue by the client through the API gateway/Lambda REST endpoint.
When the worker has finished the prediction job, it puts the result in a DynamoDb table in order to be accessed. Finally, the client requests the prediction result through an API endpoint that will read the DynamoDb table to fetch the result.
As you can see we are delegating the loading and prediction work to a worker and we do not integrate the model into the REST API. This is because a model can take a long time to load and predict. Therefore we manage them asynchronously thanks to the addition of an SQS queue and a DynamoDb table.
#data-science #technology #machine-learning #sofware-engineering #programming