Understand how one of the most popular algorithms works and how to use it
Introduction
XGBoost stands for eXtreme Gradient Boosting and it’s an open-source implementation of the gradient boosted trees algorithm. It has been one of the most popular machine learning techniques in Kaggle competitions, due to its prediction power and ease of use. It is a supervised learning algorithm that can be used for **regression **or **classification **tasks.
Regardless of its futuristic name, it’s actually not that hard to understand, as long as we first go through a few concepts: decision trees and gradient boosting. If you are already familiar with those, feel free to skip to “How XGBoost works”.
Decision trees
Decision trees are arguably the most easily interpretable ML algorithms you can find and, if used in combination with the right techniques, can be quite powerful.
A decision tree has this name because of its visual shape, which looks like a tree, with a root and many nodes and leaves. Imagine you take a list of the Titanic’s survivors, with some information such as their age and gender, and a binary variable telling who survived the disaster and who didn’t. You now want to create a classification model, to predict who will survive, based on this data. A very simple one would look like this:
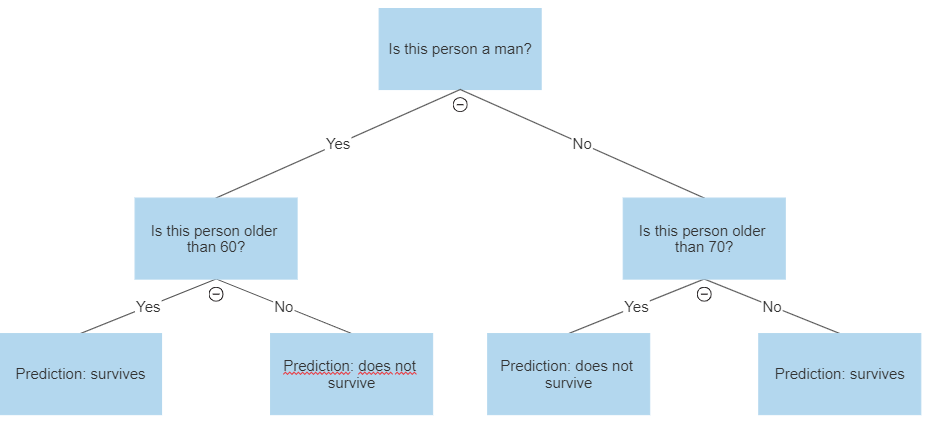
Image by author
As you can see, decision trees are just a sequence of simple decision rules that, combined, produce a prediction of the desired variable.
#data #python #statistics #machine-learning #data-science #data analytic