Introduced in February 2015, TechCrunch Magazine noted IPFS was “quickly spreading by word of mouth.”
It’s possibly a key component to solving deep-seated but largely unknown problems that exist in today’s internet usage.
Some believe IPFS, a new tongue-twisting acronym, is a tool that’ll finally evolve the internet from central entities to a world wide web of shared information, as our online founders always envisioned.

The Simple Breakdown:
IPFS = Git + BitTorrent
To understand IPFS or an Interplanetary File System, one can envision a file system that stores files and tracks versions over time, like the project Git……
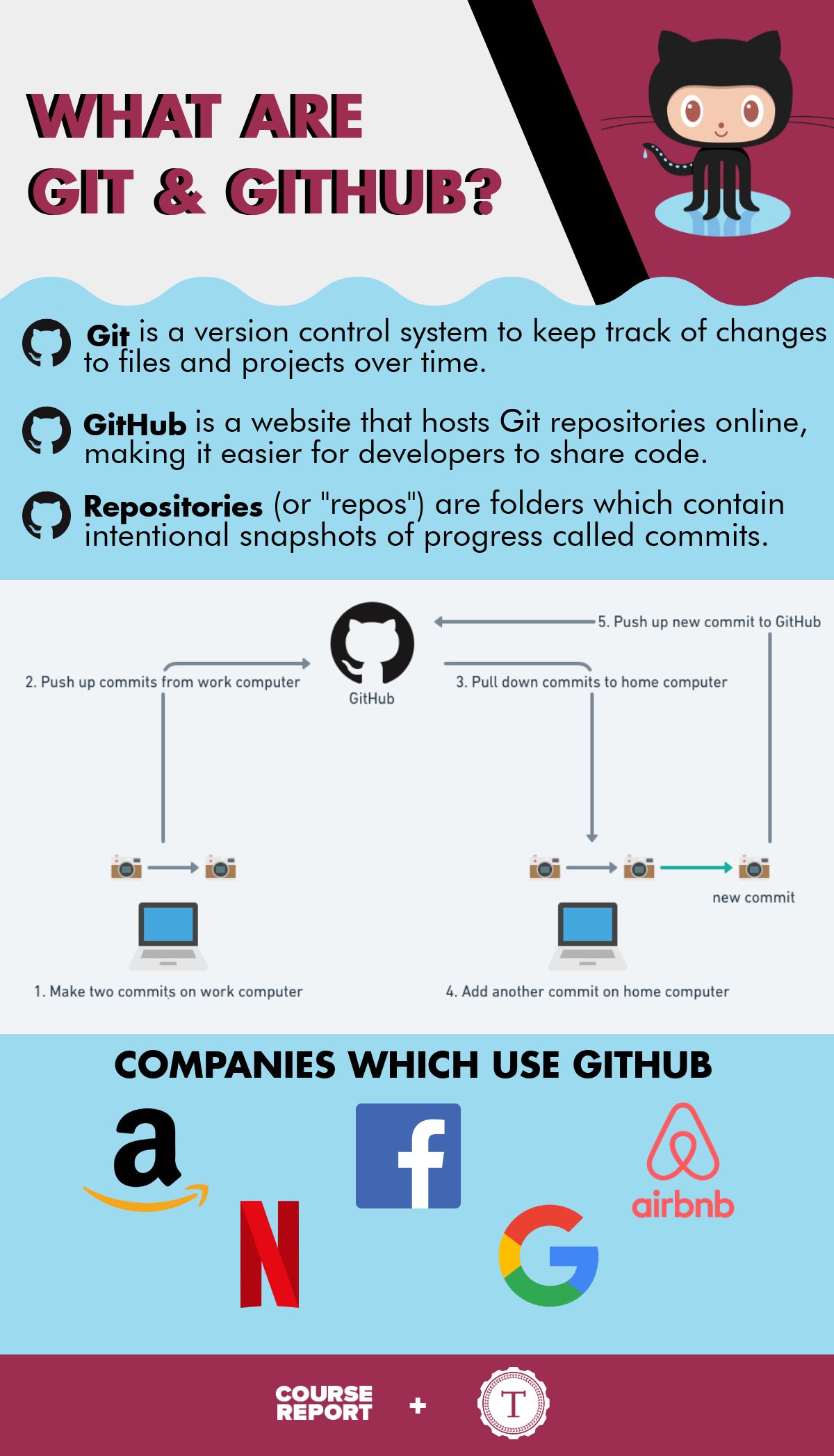
Photo Source.
Git is a distributed version control system, or VCS. Developers use it to track changes to their code . When text is added, edited or deleted in any piece of code, Git tracks the changes line-by-line It’s distributed because every user has all the source code on their computer and can act as a server. Secondly, Git is backed by a content-addressable database, meaning the content in the database is immutable.
But… IPFS also incorporates how files move across a network, making it a distributed file system, such as BitTorrent.
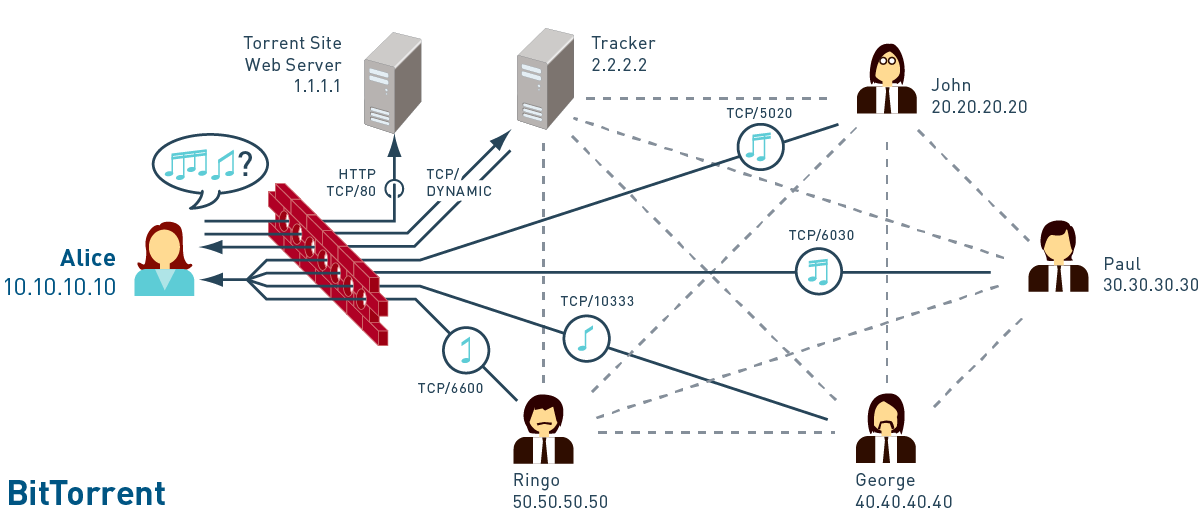
Photo Source.
_BitTorrent allows users to quickly download large files using minimum internet bandwidth. For this reason it is free to use and includes no spyware or pop-up advertising. BitTorrent’s protocol maximizes transfer speed by gathering small pieces of files desired by the user and downloads the content pieces simultaneously from other users that retain seekers content. BitTorrent is popular for freely sharing videos, programs, books, music, legal/medical records, and more. Not to mention, the downloads are much faster than other protocols. _

Photo Source.
Git + BitTorrent = BFF
IPFS uses BitTorrent’s approach, but applies Git’s concept and creates a new type of file system that tracks the respective versions of files from all the users in the network.
By utilizing both characteristics of these two entities, IPFS birthed a new permanent web that challenges existing internet protocols, such as HTTP.
WTF Is Wrong With HTTP? It Seems Fine To Me, TYVM.
Well, first, I’m not sure if you realized you had options. So while the thought: “The World Wide Web is actually wider…” sinks into your head, here’s a brief summary of what you’ve likely been using for some time.
Sit back for a quick lesson on HTTP, ASAP. (lol, you love the free jokes in my articles).
The internet is a collection of protocols that describe how data moves through a network. Developers adopted these protocols over time as they built applications on top of existing infrastructure. The protocol that serves as the backbone of the web is the HyperText Transfer Protocol.
HTTP, or HyperText Transfer Protocol is an application layer protocol for distributed, collaborative hypermedia systems created by Tim Berners Lee at CERN in 1989. HTTP is the foundation for data communication using hypertext files. It is currently used for most of the data transfer on the internet.
HTTP is a request-response protocol.
Since the internet boasts a vast array of resources hosted on different servers. To access these resources, a browser needs to be able to send a request to the server and display the resources. HTTP is the underlying format for structuring requests and responses for communication between client and host.
The message that is sent by a client to a server is what is known as an HTTP request. When these requests are being sent, clients can use various methods to make this request.
HTTP request methods are the assets that indicate a specific action to be performed on a given resource. Each method implements a distinct semantic, but there are some shared features.
Common Example: the Google homepage-back to the “client” or browser. This is a location-addressed protocol which means when google.com is inserted into a browser, it gets translated into an IP address belonging to a Google server, initiating a request-response cycle with that server.
WTF, We Have a 404 On HTTP! SOS!
Internet savvy, or not, I believe we have all fallen victim to an HTTP meltdown at least once in our lives.

Photo Source.
Do you recall a time in your life when you and a large group of people went to the same website at the same time?
Each individual participating in this action types the request into their online device and sends a request to that website, where a response is given.
each person is sent the same data, individually. If there’s 10,000 people trying to access a site, on the backend, there are 10k requests, and 10k responses. This sounds great, right? Problem is it’s pretty inefficient.
In a perfect world, participants should be able to leverage physical proximity to more effectively retrieve requested information.
HTTP presents another significant issue if there is a problem in the network’s line of communication, leaving the client unable to connect with the server.
This occurs if:
- A country is blocking some content
- An ISP has an outage
- Content was merely moved or deleted.
These types of broken links exist everywhere on the HTTP web.
A location-based addressing model, like HTTP, encourages the centralization of information.
It is convenient to trust a handful of applications with all our online data, but there’s a great sense of power and responsibility that comes with placing centralized providers with our precious personal and public information.
#ipfs #blockchain #bittorrent #women-in-blockchain #women-in-tech #what-is-ipfs #how-does-ipfs-work #hackernoon-top-story
