Python is often called a glue language. This is due to the fact that a plethora of interface libraries and features have been developed over time — driven by its widespread usage and an amazing, extensive open-source community. Those libraries and features give straightforward access to different file formats, but also data sources (databases, webpages, and APIs).
This story focuses on the extraction part of the data. Next week’s story will then dive a little deeper into analyzing the combined data to derive meaningful and exciting insights. But don’t let that stop you from analyzing the data yourself.
What you will learn:
· Extracting data from Google Sheets
· Extracting data from CSV files
· Extracting data from Excel files
Who is this article for:
· Python beginners
· People who have to wrangle data regularly
As this article is intended as a code-along article, you should have your development environment (I recommend Jupyter Notebook/Lab) set up and start a new Notebook. You can find the source code and files here.
Situation:
In today’s story, I will take you into a fictitious but probably oddly familiar situation. You are to combine data from various sources to create a report or run some analyses.
Disclaimer: The following example and data used are entirely fictitious
You are tasked with figuring out how to increase your sales team’s performance. In our hypothetical situation, potential customers have rather spontaneous demand. When this happens, your sales team puts an order lead** **into the system. Your sales reps then try to get set up a meeting that occurs around the time the order lead was noticed. Sometimes before, sometimes after. Your sales reps have an expense budget and always combine the meeting with a meal for which they pay. The sales reps expense their costs and hand the invoices to the accounting team for processing. After the potential customer has decided whether or not they want to go with your offer, your diligent sales reps track whether or not the order lead converted into a sale.
For your analysis, you have access to the following three data sources:
· 100.000 order leads (Google Sheets)
· ~50.000 meal invoices (Excel file)
· List of companies and sales reps responsible for them (CVS file)
Get Google Sheets Data:
Accessing Google Sheets turns out to be the most complicated of the three because it requires you to set up some credentials for using the Google Sheets API. You could, in theory, scrape a publicly available Google Sheet (i.e., pull the source HTML code), but you would have to do a lot of data manipulation with tools like Beautiful Soup to turn that HTML dump into something useful. I did try this, but the results were a mess and not worth the effort. So API it is. Additionally, we will use gspread for more seamless conversion to a pandas DataFrame.
Obtain OAuth2 credentials
Head to Google Developers Console and create a new project (or select an existing one). Click the “Create Project” button. If your company uses Google Mail, you might want to change into your private account to avoid potential permission conflicts.
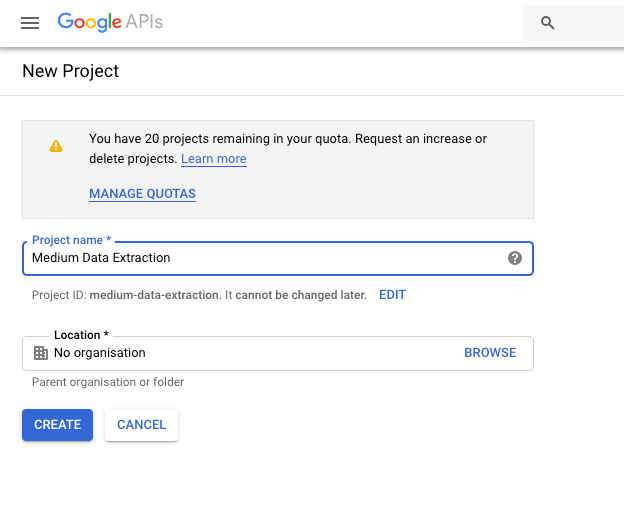
Choose a name for your project (the name does not matter, I call mine Medium Data Extraction)
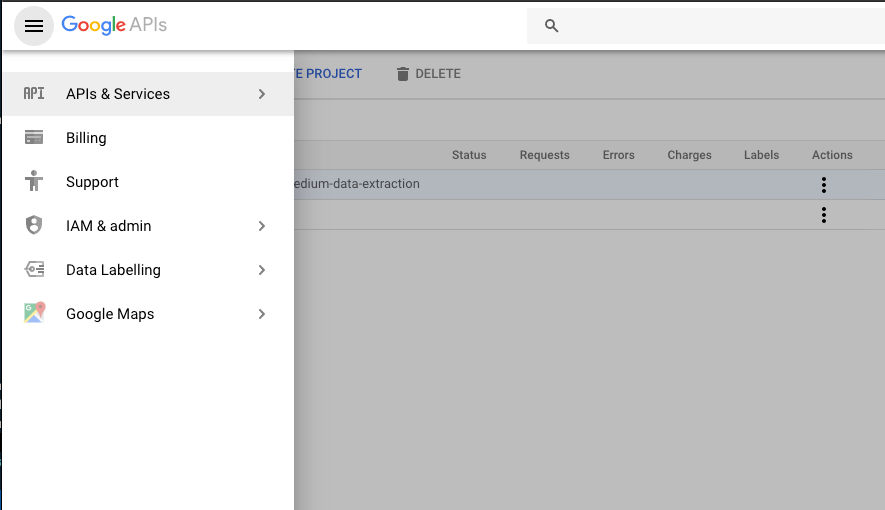
**Click APIs & Services **and head to library
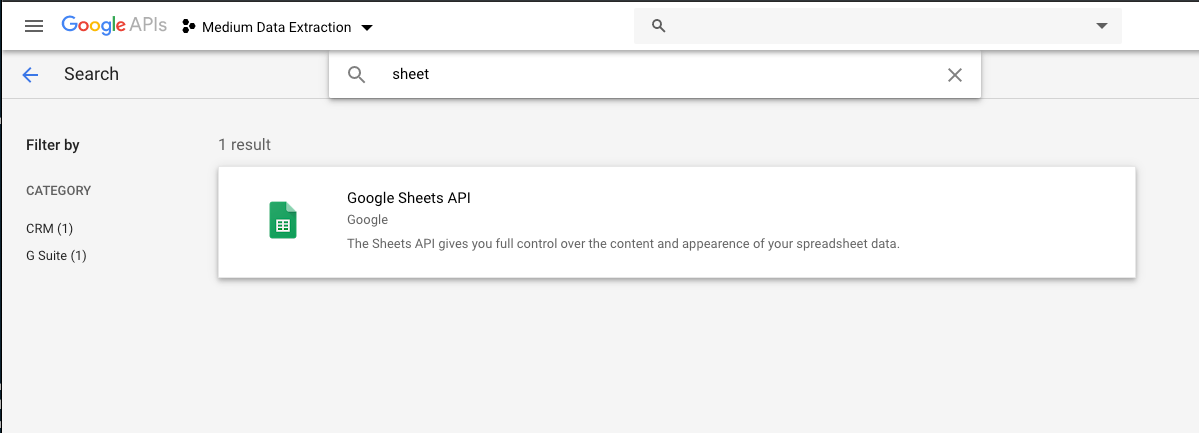
Enable Google Sheets API. Click on the result and click enable API on the following page.
Create a service account & key file. A service account is a dedicated account used for programmatic access with limited access rights. Service accounts can and should be set up by project with as specific permissions as possible and necessary for the task at hand.

Create a JSON (another file format) key file. For Role select “Project -> Viewer.”
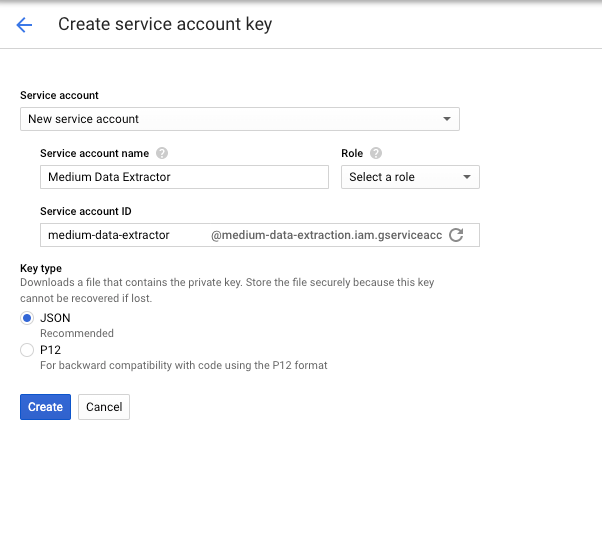
If you have not set the Role in the previous step, do it now.
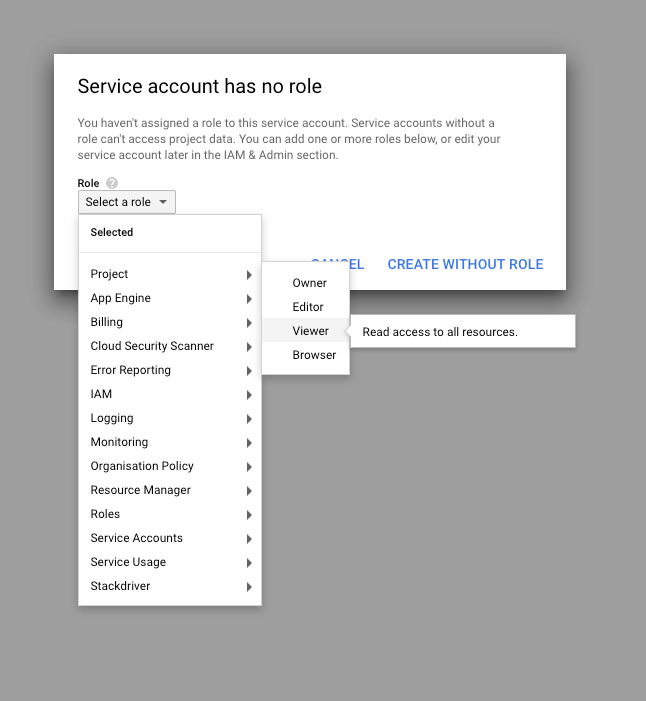
Note: Setting “Viewer” is somewhat restrictive. If you want to create google sheets programmatically, you’ll have to choose a different setting
Your private JSON key file will then be ready for download or downloaded automatically. I suggest renaming the file to Medium_Data_Extraction_Key.jsonand moving the file to the folder of your Jupyter Notebook as this will make the following examples work seamlessly. The JSON file contains your credentials for the recently created service account.
Perfect. You are almost done.
Download the data
First, you will have to download and install additional packages by running the following commands in your Notebook.
!pip install gspread
!pip install oauth2client
Secondly, you will have to make sure to move your previously created JSON key file to the folder from which you are running the Jupyter notebook, if it is not already there. Alternatively, you could specify a different GOOGLEKEYFILE path.
from oauth2client.service_account import ServiceAccountCredentials
import gspread
import pandas as pd
scope = [
'https://www.googleapis.com/auth/spreadsheets',
]
GOOGLE_KEY_FILE = 'Medium_Data_Extraction_Key.json'
credentials = ServiceAccountCredentials.from_json_keyfile_name(GOOGLE_KEY_FILE, scope)
gc = gspread.authorize(credentials)
wokbook_key = '10HX66PbcGDvx6QKM8DC9_zCGp1TD_CZhovGUbtu_M6Y'
workbook = gc.open_by_key(wokbook_key)
sheet = workbook.get_worksheet(0)
values = sheet.get_all_values()
sales_data = pd.DataFrame(values[1:],columns=values[0])
WORKBOOK_KEY is the workbook id of the Google Sheet I prepared for this session.
WORKBOOK_KEY = '10HX66PbcGDvx6QKM8DC9_zCGp1TD_CZhovGUbtu_M6Y'
The sheet is publicly available. You need to change the WORKBOOK_KEY if you want to download different data. The id can typically be found between the last two backslashes in the Google Sheets at question URL.
Get the CSV data
We can either download the CSV data the traditional way from the repo or by using the following snippet. Again you might have to install the missing requests package like this (run in your notebook):
!pip install requests
import requests
url = 'https://raw.githubusercontent.com/FBosler/Medium-Data-Extraction/master/sales_team.csv'
res = requests.get(url, allow_redirects=True)
with open('sales_team.csv','wb') as file:
file.write(res.content)
sales_team = pd.read_csv('sales_team.csv')
The beauty of CSV data is that Python / Pandas can deal with it out of the box. For Excel, there are additional libraries required.
Get the Excel Data
Before we get started, you will most likely have to install openpyxl and xlrd, which enables your Pandas to also open Excel sheets.
!pip install openpyxl
!pip install xlrd
After having done that, we get the Excel data in the same fashion and load it into another DataFrame.
url = 'https://github.com/FBosler/Medium-Data-Extraction/blob/master/invoices.xlsx?raw=true'
res = requests.get(url, allow_redirects=True)
with open('invoices.xlsx','wb') as file:
file.write(res.content)
invoices = pd.read_excel('invoices.xlsx')
Done! You have created three different Pandas data frames and can access them in the same Jupyter notebook:
· sales_data
· sales_team
· invoices
Stay tuned for next week’s article, when we look into how to combine these data frames and analyze the data.
#python #data-science
